 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniTransfer: All-in-one Framework for Spatio-temporal Video Transfer
Jan 20, 2026Videos convey richer information than images or text, capturing both spatial and temporal dynamics. However, most existing video customization methods rely on reference images or task-specific temporal priors, failing to fully exploit the rich spatio-temporal information inherent in videos, thereby limiting flexibility and generalization in video generation. To address these limitations, we propose OmniTransfer, a unified framework for spatio-temporal video transfer. It leverages multi-view information across frames to enhance appearance consistency and exploits temporal cues to enable fine-grained temporal control. To unify various video transfer tasks, OmniTransfer incorporates three key designs: Task-aware Positional Bias that adaptively leverages reference video information to improve temporal alignment or appearance consistency; Reference-decoupled Causal Learning separating reference and target branches to enable precise reference transfer while improving efficiency; and Task-adaptive Multimodal Alignment using multimodal semantic guidance to dynamically distinguish and tackle different tasks. Extensive experiments show that OmniTransfer outperforms existing methods in appearance (ID and style) and temporal transfer (camera movement and video effects), while matching pose-guided methods in motion transfer without using pose, establishing a new paradigm for flexible, high-fidelity video generation.
InstantCharacter: Personalize Any Characters with a Scalable Diffusion Transformer Framework
Apr 16, 2025Current learning-based subject customization approaches, predominantly relying on U-Net architectures, suffer from limited generalization ability and compromised image quality. Meanwhile, optimization-based methods require subject-specific fine-tuning, which inevitably degrades textual controllability. To address these challenges, we propose InstantCharacter, a scalable framework for character customization built upon a foundation diffusion transformer. InstantCharacter demonstrates three fundamental advantages: first, it achieves open-domain personalization across diverse character appearances, poses, and styles while maintaining high-fidelity results. Second, the framework introduces a scalable adapter with stacked transformer encoders, which effectively processes open-domain character features and seamlessly interacts with the latent space of modern diffusion transformers. Third, to effectively train the framework, we construct a large-scale character dataset containing 10-million-level samples. The dataset is systematically organized into paired (multi-view character) and unpaired (text-image combinations) subsets. This dual-data structure enables simultaneous optimization of identity consistency and textual editability through distinct learning pathways. Qualitative experiments demonstrate the advanced capabilities of InstantCharacter in generating high-fidelity, text-controllable, and character-consistent images, setting a new benchmark for character-driven image generation. Our source code is available at https://github.com/Tencent/InstantCharacter.
InstantIR: Blind Image Restoration with Instant Generative Reference
Oct 09, 2024



Handling test-time unknown degradation is the major challenge in Blind Image Restoration (BIR), necessitating high model generalization. An effective strategy is to incorporate prior knowledge, either from human input or generative model. In this paper, we introduce Instant-reference Image Restoration (InstantIR), a novel diffusion-based BIR method which dynamically adjusts generation condition during inference. We first extract a compact representation of the input via a pre-trained vision encoder. At each generation step, this representation is used to decode current diffusion latent and instantiate it in the generative prior. The degraded image is then encoded with this reference, providing robust generation condition. We observe the variance of generative references fluctuate with degradation intensity, which we further leverage as an indicator for developing a sampling algorithm adaptive to input quality. Extensive experiments demonstrate InstantIR achieves state-of-the-art performance and offering outstanding visual quality. Through modulating generative references with textual description, InstantIR can restore extreme degradation and additionally feature creative restoration.
CSGO: Content-Style Composition in Text-to-Image Generation
Sep 04, 2024

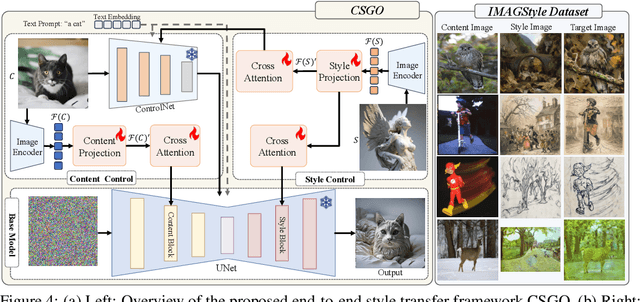
The diffusion model has shown exceptional capabilities in controlled image generation, which has further fueled interest in image style transfer. Existing works mainly focus on training free-based methods (e.g., image inversion) due to the scarcity of specific data. In this study, we present a data construction pipeline for content-style-stylized image triplets that generates and automatically cleanses stylized data triplets. Based on this pipeline, we construct a dataset IMAGStyle, the first large-scale style transfer dataset containing 210k image triplets, available for the community to explore and research. Equipped with IMAGStyle, we propose CSGO, a style transfer model based on end-to-end training, which explicitly decouples content and style features employing independent feature injection. The unified CSGO implements image-driven style transfer, text-driven stylized synthesis, and text editing-driven stylized synthesis. Extensive experiments demonstrate the effectiveness of our approach in enhancing style control capabilities in image generation. Additional visualization and access to the source code can be located on the project page: \url{https://csgo-gen.github.io/}.
InstantStyle-Plus: Style Transfer with Content-Preserving in Text-to-Image Generation
Jun 30, 2024



Style transfer is an inventive process designed to create an image that maintains the essence of the original while embracing the visual style of another. Although diffusion models have demonstrated impressive generative power in personalized subject-driven or style-driven applications, existing state-of-the-art methods still encounter difficulties in achieving a seamless balance between content preservation and style enhancement. For example, amplifying the style's influence can often undermine the structural integrity of the content. To address these challenges, we deconstruct the style transfer task into three core elements: 1) Style, focusing on the image's aesthetic characteristics; 2) Spatial Structure, concerning the geometric arrangement and composition of visual elements; and 3) Semantic Content, which captures the conceptual meaning of the image. Guided by these principles, we introduce InstantStyle-Plus, an approach that prioritizes the integrity of the original content while seamlessly integrating the target style. Specifically, our method accomplishes style injection through an efficient, lightweight process, utilizing the cutting-edge InstantStyle framework. To reinforce the content preservation, we initiate the process with an inverted content latent noise and a versatile plug-and-play tile ControlNet for preserving the original image's intrinsic layout. We also incorporate a global semantic adapter to enhance the semantic content's fidelity. To safeguard against the dilution of style information, a style extractor is employed as discriminator for providing supplementary style guidance. Codes will be available at https://github.com/instantX-research/InstantStyle-Plus.
InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation
Apr 04, 2024Tuning-free diffusion-based models have demonstrated significant potential in the realm of image personalization and customization. However, despite this notable progress, current models continue to grapple with several complex challenges in producing style-consistent image generation. Firstly, the concept of style is inherently underdetermined, encompassing a multitude of elements such as color, material, atmosphere, design, and structure, among others. Secondly, inversion-based methods are prone to style degradation, often resulting in the loss of fine-grained details. Lastly, adapter-based approaches frequently require meticulous weight tuning for each reference image to achieve a balance between style intensity and text controllability. In this paper, we commence by examining several compelling yet frequently overlooked observations. We then proceed to introduce InstantStyle, a framework designed to address these issues through the implementation of two key strategies: 1) A straightforward mechanism that decouples style and content from reference images within the feature space, predicated on the assumption that features within the same space can be either added to or subtracted from one another. 2) The injection of reference image features exclusively into style-specific blocks, thereby preventing style leaks and eschewing the need for cumbersome weight tuning, which often characterizes more parameter-heavy designs.Our work demonstrates superior visual stylization outcomes, striking an optimal balance between the intensity of style and the controllability of textual elements. Our codes will be available at https://github.com/InstantStyle/InstantStyle.
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Feb 02, 2024
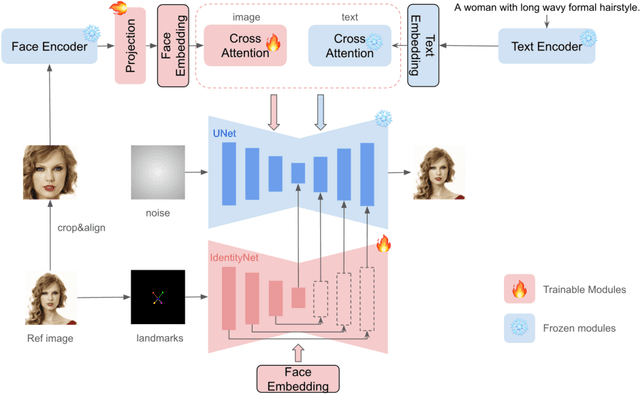


There has been significant progress in personalized image synthesis with methods such as Textual Inversion, DreamBooth, and LoRA. Yet, their real-world applicability is hindered by high storage demands, lengthy fine-tuning processes, and the need for multiple reference images. Conversely, existing ID embedding-based methods, while requiring only a single forward inference, face challenges: they either necessitate extensive fine-tuning across numerous model parameters, lack compatibility with community pre-trained models, or fail to maintain high face fidelity. Addressing these limitations, we introduce InstantID, a powerful diffusion model-based solution. Our plug-and-play module adeptly handles image personalization in various styles using just a single facial image, while ensuring high fidelity. To achieve this, we design a novel IdentityNet by imposing strong semantic and weak spatial conditions, integrating facial and landmark images with textual prompts to steer the image generation. InstantID demonstrates exceptional performance and efficiency, proving highly beneficial in real-world applications where identity preservation is paramount. Moreover, our work seamlessly integrates with popular pre-trained text-to-image diffusion models like SD1.5 and SDXL, serving as an adaptable plugin. Our codes and pre-trained checkpoints will be available at https://github.com/InstantID/InstantID.
RDGCN: Reinforced Dependency Graph Convolutional Network for Aspect-based Sentiment Analysis
Nov 08, 2023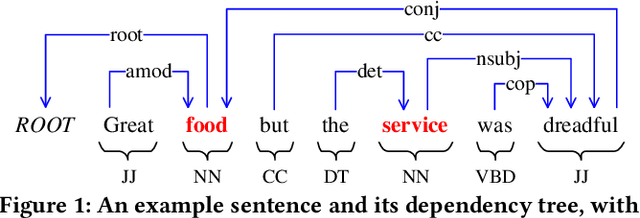
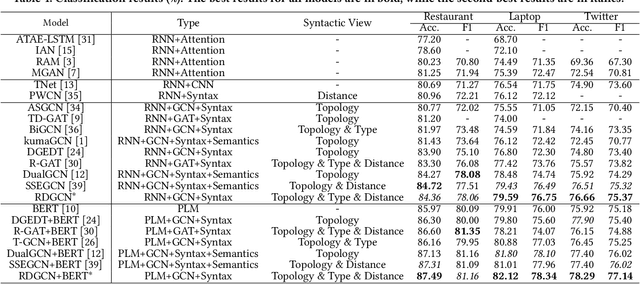
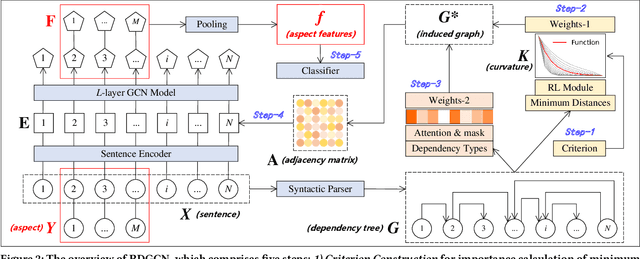
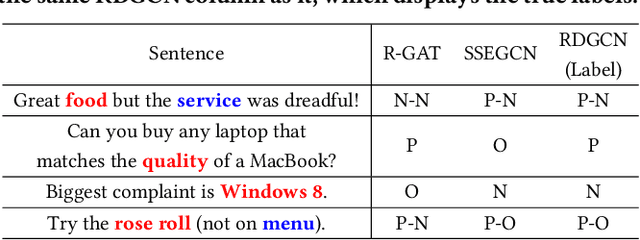
Aspect-based sentiment analysis (ABSA) is dedicated to forecasting the sentiment polarity of aspect terms within sentences. Employing graph neural networks to capture structural patterns from syntactic dependency parsing has been confirmed as an effective approach for boosting ABSA. In most works, the topology of dependency trees or dependency-based attention coefficients is often loosely regarded as edges between aspects and opinions, which can result in insufficient and ambiguous syntactic utilization. To address these problems, we propose a new reinforced dependency graph convolutional network (RDGCN) that improves the importance calculation of dependencies in both distance and type views. Initially, we propose an importance calculation criterion for the minimum distances over dependency trees. Under the criterion, we design a distance-importance function that leverages reinforcement learning for weight distribution search and dissimilarity control. Since dependency types often do not have explicit syntax like tree distances, we use global attention and mask mechanisms to design type-importance functions. Finally, we merge these weights and implement feature aggregation and classification. Comprehensive experiments on three popular datasets demonstrate the effectiveness of the criterion and importance functions. RDGCN outperforms state-of-the-art GNN-based baselines in all validations.
Multi-omics Sampling-based Graph Transformer for Synthetic Lethality Prediction
Oct 17, 2023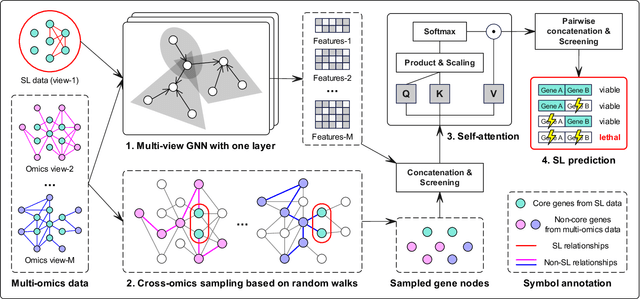
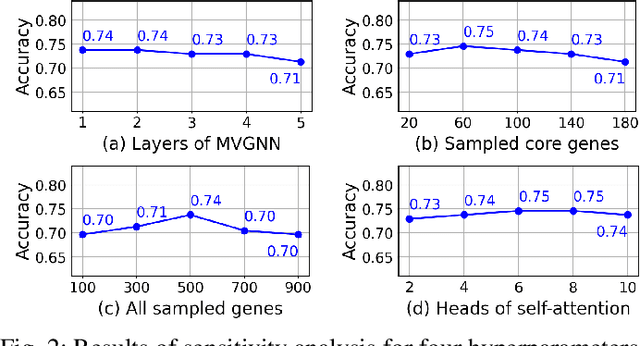
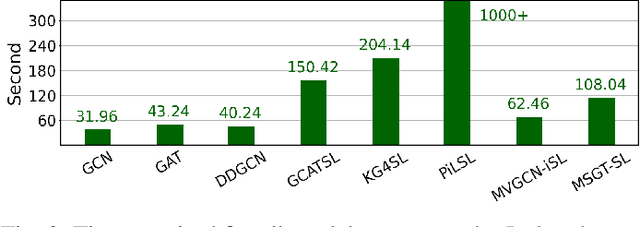
Synthetic lethality (SL) prediction is used to identify if the co-mutation of two genes results in cell death. The prevalent strategy is to abstract SL prediction as an edge classification task on gene nodes within SL data and achieve it through graph neural networks (GNNs). However, GNNs suffer from limitations in their message passing mechanisms, including over-smoothing and over-squashing issues. Moreover, harnessing the information of non-SL gene relationships within large-scale multi-omics data to facilitate SL prediction poses a non-trivial challenge. To tackle these issues, we propose a new multi-omics sampling-based graph transformer for SL prediction (MSGT-SL). Concretely, we introduce a shallow multi-view GNN to acquire local structural patterns from both SL and multi-omics data. Further, we input gene features that encode multi-view information into the standard self-attention to capture long-range dependencies. Notably, starting with batch genes from SL data, we adopt parallel random walk sampling across multiple omics gene graphs encompassing them. Such sampling effectively and modestly incorporates genes from omics in a structure-aware manner before using self-attention. We showcase the effectiveness of MSGT-SL on real-world SL tasks, demonstrating the empirical benefits gained from the graph transformer and multi-omics data.
Cross-Network Social User Embedding with Hybrid Differential Privacy Guarantees
Sep 04, 2022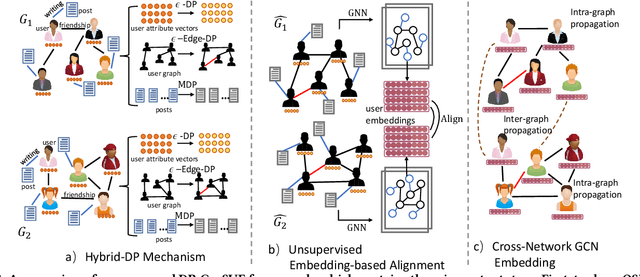

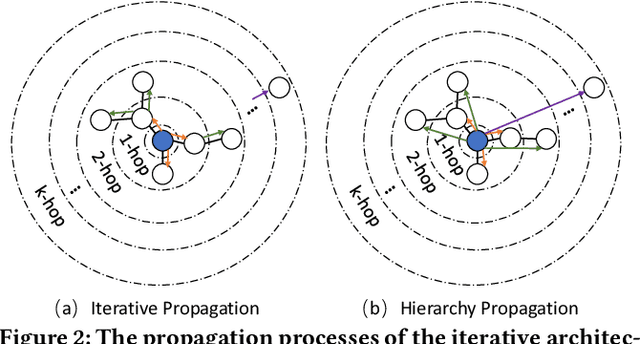
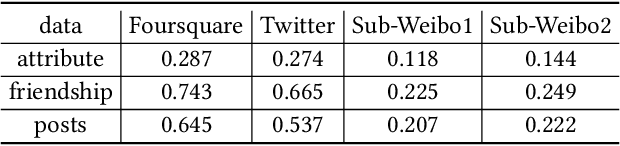
Integrating multiple online social networks (OSNs) has important implications for many downstream social mining tasks, such as user preference modelling, recommendation, and link prediction. However, it is unfortunately accompanied by growing privacy concerns about leaking sensitive user information. How to fully utilize the data from different online social networks while preserving user privacy remains largely unsolved. To this end, we propose a Cross-network Social User Embedding framework, namely DP-CroSUE, to learn the comprehensive representations of users in a privacy-preserving way. We jointly consider information from partially aligned social networks with differential privacy guarantees. In particular, for each heterogeneous social network, we first introduce a hybrid differential privacy notion to capture the variation of privacy expectations for heterogeneous data types. Next, to find user linkages across social networks, we make unsupervised user embedding-based alignment in which the user embeddings are achieved by the heterogeneous network embedding technology. To further enhance user embeddings, a novel cross-network GCN embedding model is designed to transfer knowledge across networks through those aligned users. Extensive experiments on three real-world datasets demonstrate that our approach makes a significant improvement on user interest prediction tasks as well as defending user attribute inference attacks from embedding.