 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniVideo-R1: Reinforcing Audio-visual Reasoning with Query Intention and Modality Attention
Feb 05, 2026While humans perceive the world through diverse modalities that operate synergistically to support a holistic understanding of their surroundings, existing omnivideo models still face substantial challenges on audio-visual understanding tasks. In this paper, we propose OmniVideo-R1, a novel reinforced framework that improves mixed-modality reasoning. OmniVideo-R1 empowers models to "think with omnimodal cues" by two key strategies: (1) query-intensive grounding based on self-supervised learning paradigms; and (2) modality-attentive fusion built upon contrastive learning paradigms. Extensive experiments on multiple benchmarks demonstrate that OmniVideo-R1 consistently outperforms strong baselines, highlighting its effectiveness and robust generalization capabilities.
PromptEnhancer: A Simple Approach to Enhance Text-to-Image Models via Chain-of-Thought Prompt Rewriting
Sep 04, 2025Recent advancements in text-to-image (T2I) diffusion models have demonstrated remarkable capabilities in generating high-fidelity images. However, these models often struggle to faithfully render complex user prompts, particularly in aspects like attribute binding, negation, and compositional relationships. This leads to a significant mismatch between user intent and the generated output. To address this challenge, we introduce PromptEnhancer, a novel and universal prompt rewriting framework that enhances any pretrained T2I model without requiring modifications to its weights. Unlike prior methods that rely on model-specific fine-tuning or implicit reward signals like image-reward scores, our framework decouples the rewriter from the generator. We achieve this by training a Chain-of-Thought (CoT) rewriter through reinforcement learning, guided by a dedicated reward model we term the AlignEvaluator. The AlignEvaluator is trained to provide explicit and fine-grained feedback based on a systematic taxonomy of 24 key points, which are derived from a comprehensive analysis of common T2I failure modes. By optimizing the CoT rewriter to maximize the reward from our AlignEvaluator, our framework learns to generate prompts that are more precisely interpreted by T2I models. Extensive experiments on the HunyuanImage 2.1 model demonstrate that PromptEnhancer significantly improves image-text alignment across a wide range of semantic and compositional challenges. Furthermore, we introduce a new, high-quality human preference benchmark to facilitate future research in this direction.
Prohibited Items Segmentation via Occlusion-aware Bilayer Modeling
Jun 13, 2025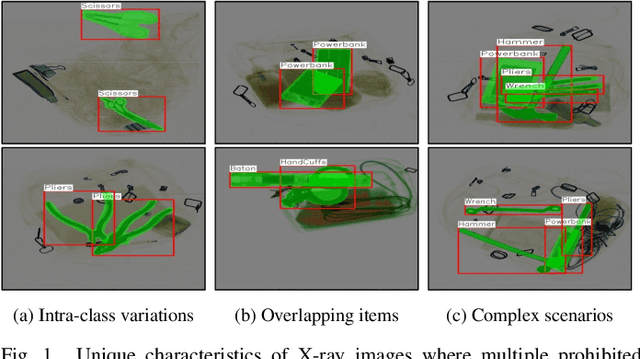
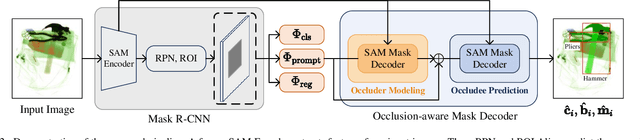
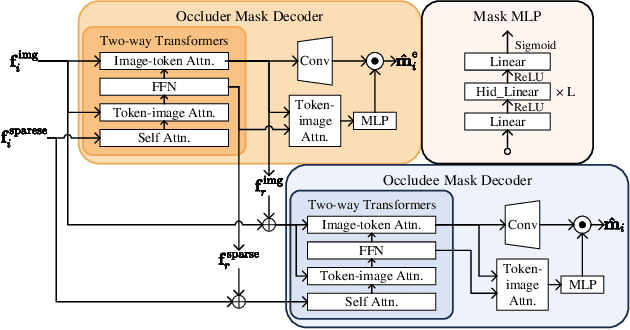

Instance segmentation of prohibited items in security X-ray images is a critical yet challenging task. This is mainly caused by the significant appearance gap between prohibited items in X-ray images and natural objects, as well as the severe overlapping among objects in X-ray images. To address these issues, we propose an occlusion-aware instance segmentation pipeline designed to identify prohibited items in X-ray images. Specifically, to bridge the representation gap, we integrate the Segment Anything Model (SAM) into our pipeline, taking advantage of its rich priors and zero-shot generalization capabilities. To address the overlap between prohibited items, we design an occlusion-aware bilayer mask decoder module that explicitly models the occlusion relationships. To supervise occlusion estimation, we manually annotated occlusion areas of prohibited items in two large-scale X-ray image segmentation datasets, PIDray and PIXray. We then reorganized these additional annotations together with the original information as two occlusion-annotated datasets, PIDray-A and PIXray-A. Extensive experimental results on these occlusion-annotated datasets demonstrate the effectiveness of our proposed method. The datasets and codes are available at: https://github.com/Ryh1218/Occ
Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
InstantCharacter: Personalize Any Characters with a Scalable Diffusion Transformer Framework
Apr 16, 2025Current learning-based subject customization approaches, predominantly relying on U-Net architectures, suffer from limited generalization ability and compromised image quality. Meanwhile, optimization-based methods require subject-specific fine-tuning, which inevitably degrades textual controllability. To address these challenges, we propose InstantCharacter, a scalable framework for character customization built upon a foundation diffusion transformer. InstantCharacter demonstrates three fundamental advantages: first, it achieves open-domain personalization across diverse character appearances, poses, and styles while maintaining high-fidelity results. Second, the framework introduces a scalable adapter with stacked transformer encoders, which effectively processes open-domain character features and seamlessly interacts with the latent space of modern diffusion transformers. Third, to effectively train the framework, we construct a large-scale character dataset containing 10-million-level samples. The dataset is systematically organized into paired (multi-view character) and unpaired (text-image combinations) subsets. This dual-data structure enables simultaneous optimization of identity consistency and textual editability through distinct learning pathways. Qualitative experiments demonstrate the advanced capabilities of InstantCharacter in generating high-fidelity, text-controllable, and character-consistent images, setting a new benchmark for character-driven image generation. Our source code is available at https://github.com/Tencent/InstantCharacter.
FreCaS: Efficient Higher-Resolution Image Generation via Frequency-aware Cascaded Sampling
Oct 24, 2024



While image generation with diffusion models has achieved a great success, generating images of higher resolution than the training size remains a challenging task due to the high computational cost. Current methods typically perform the entire sampling process at full resolution and process all frequency components simultaneously, contradicting with the inherent coarse-to-fine nature of latent diffusion models and wasting computations on processing premature high-frequency details at early diffusion stages. To address this issue, we introduce an efficient $\textbf{Fre}$quency-aware $\textbf{Ca}$scaded $\textbf{S}$ampling framework, $\textbf{FreCaS}$ in short, for higher-resolution image generation. FreCaS decomposes the sampling process into cascaded stages with gradually increased resolutions, progressively expanding frequency bands and refining the corresponding details. We propose an innovative frequency-aware classifier-free guidance (FA-CFG) strategy to assign different guidance strengths for different frequency components, directing the diffusion model to add new details in the expanded frequency domain of each stage. Additionally, we fuse the cross-attention maps of previous and current stages to avoid synthesizing unfaithful layouts. Experiments demonstrate that FreCaS significantly outperforms state-of-the-art methods in image quality and generation speed. In particular, FreCaS is about 2.86$\times$ and 6.07$\times$ faster than ScaleCrafter and DemoFusion in generating a 2048$\times$2048 image using a pre-trained SDXL model and achieves an FID$_b$ improvement of 11.6 and 3.7, respectively. FreCaS can be easily extended to more complex models such as SD3. The source code of FreCaS can be found at $\href{\text{https://github.com/xtudbxk/FreCaS}}{https://github.com/xtudbxk/FreCaS}$.
Dense Multimodal Alignment for Open-Vocabulary 3D Scene Understanding
Jul 13, 2024



Recent vision-language pre-training models have exhibited remarkable generalization ability in zero-shot recognition tasks. Previous open-vocabulary 3D scene understanding methods mostly focus on training 3D models using either image or text supervision while neglecting the collective strength of all modalities. In this work, we propose a Dense Multimodal Alignment (DMA) framework to densely co-embed different modalities into a common space for maximizing their synergistic benefits. Instead of extracting coarse view- or region-level text prompts, we leverage large vision-language models to extract complete category information and scalable scene descriptions to build the text modality, and take image modality as the bridge to build dense point-pixel-text associations. Besides, in order to enhance the generalization ability of the 2D model for downstream 3D tasks without compromising the open-vocabulary capability, we employ a dual-path integration approach to combine frozen CLIP visual features and learnable mask features. Extensive experiments show that our DMA method produces highly competitive open-vocabulary segmentation performance on various indoor and outdoor tasks.
SyncNoise: Geometrically Consistent Noise Prediction for Text-based 3D Scene Editing
Jun 25, 2024Text-based 2D diffusion models have demonstrated impressive capabilities in image generation and editing. Meanwhile, the 2D diffusion models also exhibit substantial potentials for 3D editing tasks. However, how to achieve consistent edits across multiple viewpoints remains a challenge. While the iterative dataset update method is capable of achieving global consistency, it suffers from slow convergence and over-smoothed textures. We propose SyncNoise, a novel geometry-guided multi-view consistent noise editing approach for high-fidelity 3D scene editing. SyncNoise synchronously edits multiple views with 2D diffusion models while enforcing multi-view noise predictions to be geometrically consistent, which ensures global consistency in both semantic structure and low-frequency appearance. To further enhance local consistency in high-frequency details, we set a group of anchor views and propagate them to their neighboring frames through cross-view reprojection. To improve the reliability of multi-view correspondences, we introduce depth supervision during training to enhance the reconstruction of precise geometries. Our method achieves high-quality 3D editing results respecting the textual instructions, especially in scenes with complex textures, by enhancing geometric consistency at the noise and pixel levels.
Source Prompt Disentangled Inversion for Boosting Image Editability with Diffusion Models
Mar 17, 2024



Text-driven diffusion models have significantly advanced the image editing performance by using text prompts as inputs. One crucial step in text-driven image editing is to invert the original image into a latent noise code conditioned on the source prompt. While previous methods have achieved promising results by refactoring the image synthesizing process, the inverted latent noise code is tightly coupled with the source prompt, limiting the image editability by target text prompts. To address this issue, we propose a novel method called Source Prompt Disentangled Inversion (SPDInv), which aims at reducing the impact of source prompt, thereby enhancing the text-driven image editing performance by employing diffusion models. To make the inverted noise code be independent of the given source prompt as much as possible, we indicate that the iterative inversion process should satisfy a fixed-point constraint. Consequently, we transform the inversion problem into a searching problem to find the fixed-point solution, and utilize the pre-trained diffusion models to facilitate the searching process. The experimental results show that our proposed SPDInv method can effectively mitigate the conflicts between the target editing prompt and the source prompt, leading to a significant decrease in editing artifacts. In addition to text-driven image editing, with SPDInv we can easily adapt customized image generation models to localized editing tasks and produce promising performance. The source code are available at https://github.com/leeruibin/SPDInv.
ScatterFormer: Efficient Voxel Transformer with Scattered Linear Attention
Jan 01, 2024



Window-based transformers have demonstrated strong ability in large-scale point cloud understanding by capturing context-aware representations with affordable attention computation in a more localized manner. However, because of the sparse nature of point clouds, the number of voxels per window varies significantly. Current methods partition the voxels in each window into multiple subsets of equal size, which cost expensive overhead in sorting and padding the voxels, making them run slower than sparse convolution based methods. In this paper, we present ScatterFormer, which, for the first time to our best knowledge, could directly perform attention on voxel sets with variable length. The key of ScatterFormer lies in the innovative Scatter Linear Attention (SLA) module, which leverages the linear attention mechanism to process in parallel all voxels scattered in different windows. Harnessing the hierarchical computation units of the GPU and matrix blocking algorithm, we reduce the latency of the proposed SLA module to less than 1 ms on moderate GPUs. Besides, we develop a cross-window interaction module to simultaneously enhance the local representation and allow the information flow across windows, eliminating the need for window shifting. Our proposed ScatterFormer demonstrates 73 mAP (L2) on the large-scale Waymo Open Dataset and 70.5 NDS on the NuScenes dataset, running at an outstanding detection rate of 28 FPS. Code is available at https://github.com/skyhehe123/ScatterFormer