 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraspView: Active Perception Scoring and Best-View Optimization for Robotic Grasping in Cluttered Environments
Nov 06, 2025Robotic grasping is a fundamental capability for autonomous manipulation, yet remains highly challenging in cluttered environments where occlusion, poor perception quality, and inconsistent 3D reconstructions often lead to unstable or failed grasps. Conventional pipelines have widely relied on RGB-D cameras to provide geometric information, which fail on transparent or glossy objects and degrade at close range. We present GraspView, an RGB-only robotic grasping pipeline that achieves accurate manipulation in cluttered environments without depth sensors. Our framework integrates three key components: (i) global perception scene reconstruction, which provides locally consistent, up-to-scale geometry from a single RGB view and fuses multi-view projections into a coherent global 3D scene; (ii) a render-and-score active perception strategy, which dynamically selects next-best-views to reveal occluded regions; and (iii) an online metric alignment module that calibrates VGGT predictions against robot kinematics to ensure physical scale consistency. Building on these tailor-designed modules, GraspView performs best-view global grasping, fusing multi-view reconstructions and leveraging GraspNet for robust execution. Experiments on diverse tabletop objects demonstrate that GraspView significantly outperforms both RGB-D and single-view RGB baselines, especially under heavy occlusion, near-field sensing, and with transparent objects. These results highlight GraspView as a practical and versatile alternative to RGB-D pipelines, enabling reliable grasping in unstructured real-world environments.
Learning to See and Act: Task-Aware View Planning for Robotic Manipulation
Aug 07, 2025Recent vision-language-action (VLA) models for multi-task robotic manipulation commonly rely on static viewpoints and shared visual encoders, which limit 3D perception and cause task interference, hindering robustness and generalization. In this work, we propose Task-Aware View Planning (TAVP), a framework designed to overcome these challenges by integrating active view planning with task-specific representation learning. TAVP employs an efficient exploration policy, accelerated by a novel pseudo-environment, to actively acquire informative views. Furthermore, we introduce a Mixture-of-Experts (MoE) visual encoder to disentangle features across different tasks, boosting both representation fidelity and task generalization. By learning to see the world in a task-aware way, TAVP generates more complete and discriminative visual representations, demonstrating significantly enhanced action prediction across a wide array of manipulation challenges. Extensive experiments on RLBench tasks show that our proposed TAVP model achieves superior performance over state-of-the-art fixed-view approaches. Visual results and code are provided at: https://hcplab-sysu.github.io/TAVP.
Prohibited Items Segmentation via Occlusion-aware Bilayer Modeling
Jun 13, 2025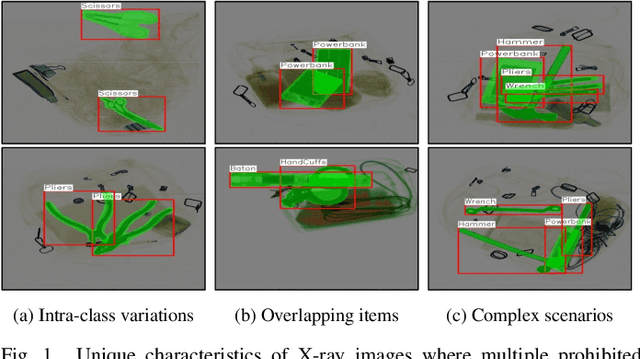
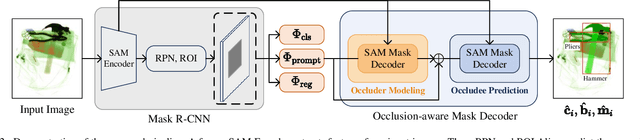
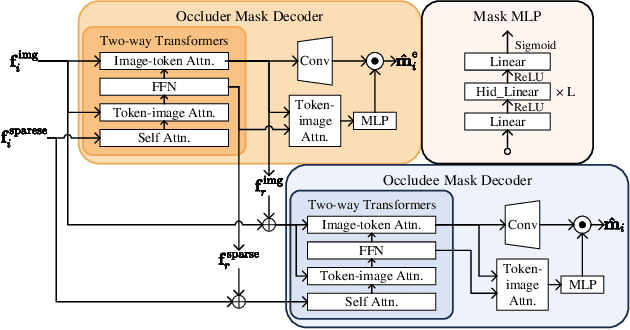

Instance segmentation of prohibited items in security X-ray images is a critical yet challenging task. This is mainly caused by the significant appearance gap between prohibited items in X-ray images and natural objects, as well as the severe overlapping among objects in X-ray images. To address these issues, we propose an occlusion-aware instance segmentation pipeline designed to identify prohibited items in X-ray images. Specifically, to bridge the representation gap, we integrate the Segment Anything Model (SAM) into our pipeline, taking advantage of its rich priors and zero-shot generalization capabilities. To address the overlap between prohibited items, we design an occlusion-aware bilayer mask decoder module that explicitly models the occlusion relationships. To supervise occlusion estimation, we manually annotated occlusion areas of prohibited items in two large-scale X-ray image segmentation datasets, PIDray and PIXray. We then reorganized these additional annotations together with the original information as two occlusion-annotated datasets, PIDray-A and PIXray-A. Extensive experimental results on these occlusion-annotated datasets demonstrate the effectiveness of our proposed method. The datasets and codes are available at: https://github.com/Ryh1218/Occ
Global Public Sentiment on Decentralized Finance: A Spatiotemporal Analysis of Geo-tagged Tweets from 150 Countries
Sep 01, 2024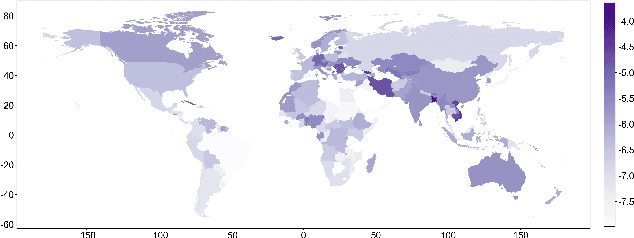
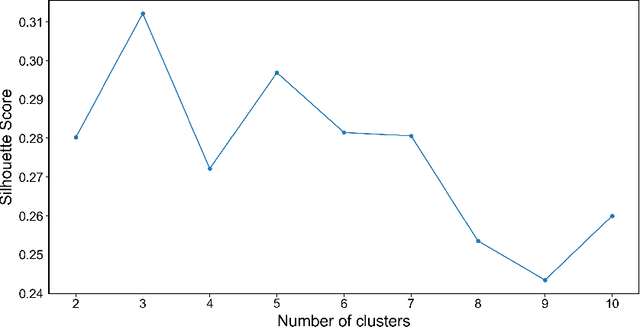
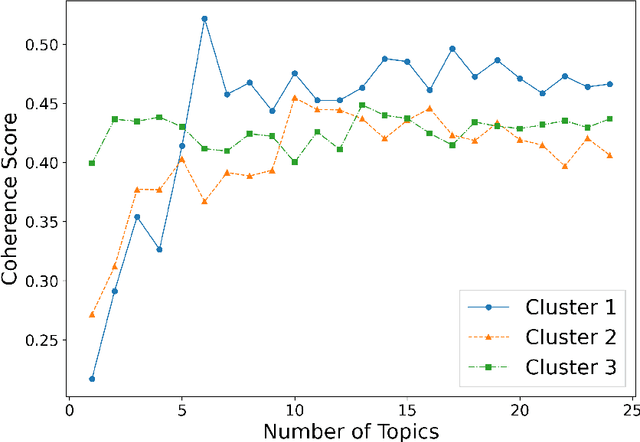
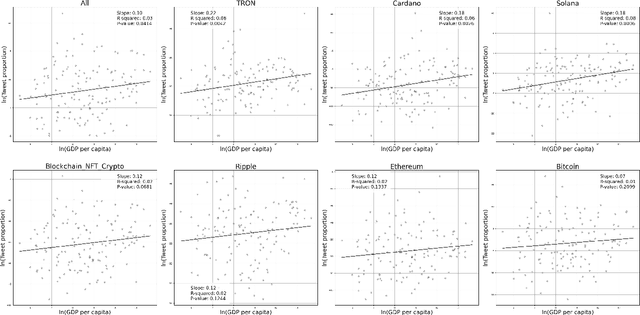
In the digital era, blockchain technology, cryptocurrencies, and non-fungible tokens (NFTs) have transformed financial and decentralized systems. However, existing research often neglects the spatiotemporal variations in public sentiment toward these technologies, limiting macro-level insights into their global impact. This study leverages Twitter data to explore public attention and sentiment across 150 countries, analyzing over 150 million geotagged tweets from 2012 to 2022. Sentiment scores were derived using a BERT-based multilingual sentiment model trained on 7.4 billion tweets. The analysis integrates global cryptocurrency regulations and economic indicators from the World Development Indicators database. Results reveal significant global sentiment variations influenced by economic factors, with more developed nations engaging more in discussions, while less developed countries show higher sentiment levels. Geographically weighted regression indicates that GDP-tweet engagement correlation intensifies following Bitcoin price surges. Topic modeling shows that countries within similar economic clusters share discussion trends, while different clusters focus on distinct topics. This study highlights global disparities in sentiment toward decentralized finance, shaped by economic and regional factors, with implications for poverty alleviation, cryptocurrency crime, and sustainable development. The dataset and code are publicly available on GitHub.
MoPE: Parameter-Efficient and Scalable Multimodal Fusion via Mixture of Prompt Experts
Mar 14, 2024Prompt-tuning has demonstrated parameter-efficiency in fusing unimodal foundation models for multimodal tasks. However, its limited adaptivity and expressiveness lead to suboptimal performance when compared with other tuning methods. In this paper, we address this issue by disentangling the vanilla prompts to adaptively capture dataset-level and instance-level features. Building upon this disentanglement, we introduce the mixture of prompt experts (MoPE) technique to enhance expressiveness. MoPE leverages multimodal pairing priors to route the most effective prompt on a per-instance basis. Compared to vanilla prompting, our MoPE-based conditional prompting exhibits greater expressiveness for multimodal fusion, scaling better with the training data and the overall number of trainable parameters. We also study a regularization term for expert routing, leading to emergent expert specialization, where different experts focus on different concepts, enabling interpretable soft prompting. Extensive experiments across three multimodal datasets demonstrate that our method achieves state-of-the-art results, matching or even surpassing the performance of fine-tuning, while requiring only 0.8% of the trainable parameters. Code will be released: https://github.com/songrise/MoPE.
An Ensemble Framework for Explainable Geospatial Machine Learning Models
Mar 05, 2024



Analyzing spatial varying effect is pivotal in geographic analysis. Yet, accurately capturing and interpreting this variability is challenging due to the complexity and non-linearity of geospatial data. Herein, we introduce an integrated framework that merges local spatial weighting scheme, Explainable Artificial Intelligence (XAI), and cutting-edge machine learning technologies to bridge the gap between traditional geographic analysis models and general machine learning approaches. Through tests on synthetic datasets, this framework is verified to enhance the interpretability and accuracy of predictions in both geographic regression and classification by elucidating spatial variability. It significantly boosts prediction precision, offering a novel approach to understanding spatial phenomena.
Conditional Prompt Tuning for Multimodal Fusion
Nov 28, 2023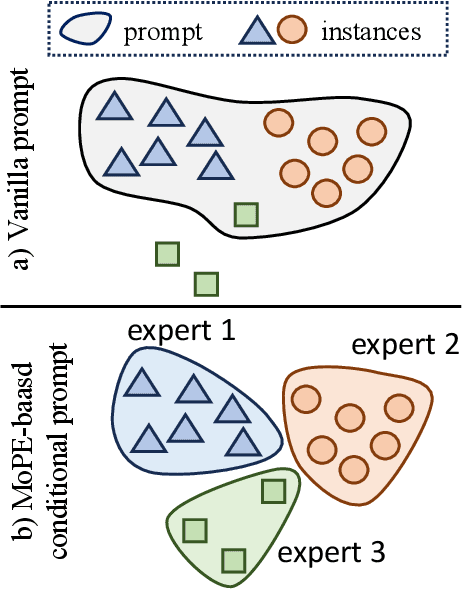
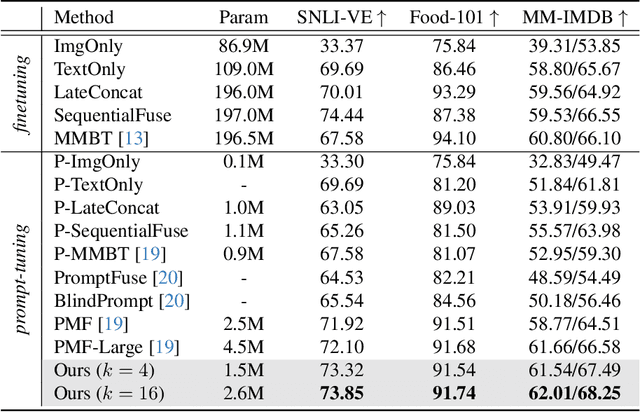
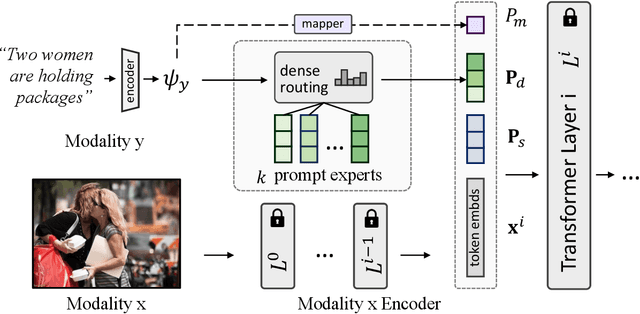
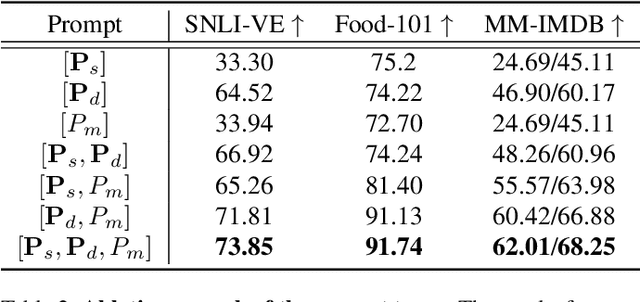
We show that the representation of one modality can effectively guide the prompting of another modality for parameter-efficient multimodal fusion. Specifically, we first encode one modality and use its representation as a prior to conditionally prompt all frozen layers of the other modality. This is achieved by disentangling the vanilla prompt vectors into three types of specialized prompts that adaptively capture global-level and instance-level features. To better produce the instance-wise prompt, we introduce the mixture of prompt experts (MoPE) to dynamically route each instance to the most suitable prompt experts for encoding. We further study a regularization term to avoid degenerated prompt expert routing. Thanks to our design, our method can effectively transfer the pretrained knowledge in unimodal encoders for downstream multimodal tasks. Compared with vanilla prompting, we show that our MoPE-based conditional prompting is more expressive, thereby scales better with training data and the total number of prompts. We also demonstrate that our prompt tuning is architecture-agnostic, thereby offering high modularity. Extensive experiments over three multimodal datasets demonstrate state-of-the-art results, matching or surpassing the performance achieved through fine-tuning, while only necessitating 0.7% of the trainable parameters. Code will be released: https://github.com/songrise/ConditionalPrompt.
SQLNet: Scale-Modulated Query and Localization Network for Few-Shot Class-Agnostic Counting
Nov 16, 2023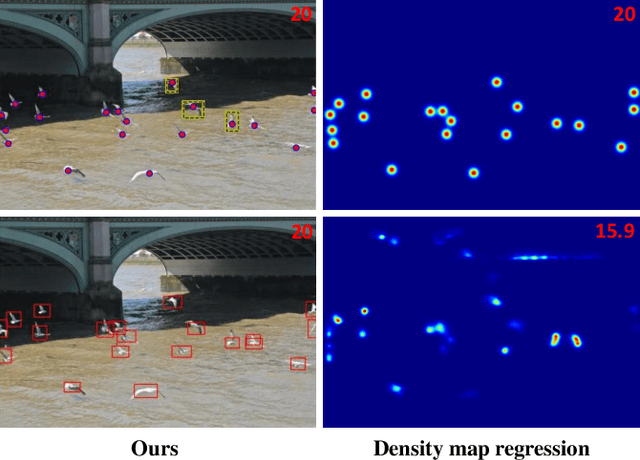
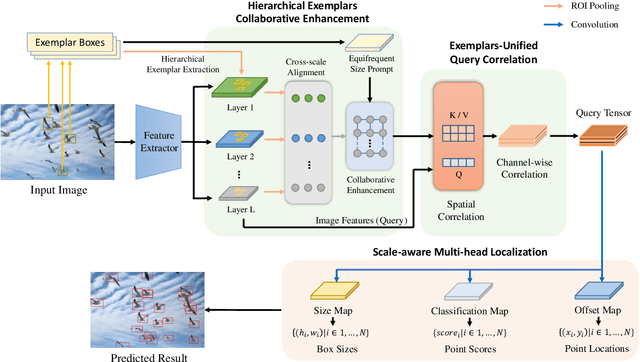
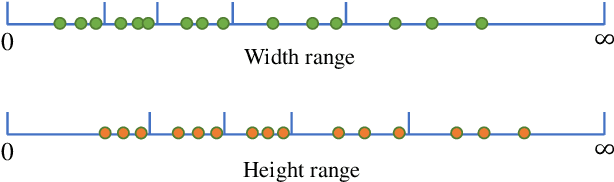
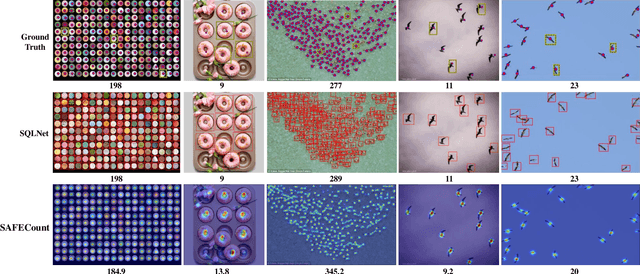
The class-agnostic counting (CAC) task has recently been proposed to solve the problem of counting all objects of an arbitrary class with several exemplars given in the input image. To address this challenging task, existing leading methods all resort to density map regression, which renders them impractical for downstream tasks that require object locations and restricts their ability to well explore the scale information of exemplars for supervision. To address the limitations, we propose a novel localization-based CAC approach, termed Scale-modulated Query and Localization Network (SQLNet). It fully explores the scales of exemplars in both the query and localization stages and achieves effective counting by accurately locating each object and predicting its approximate size. Specifically, during the query stage, rich discriminative representations of the target class are acquired by the Hierarchical Exemplars Collaborative Enhancement (HECE) module from the few exemplars through multi-scale exemplar cooperation with equifrequent size prompt embedding. These representations are then fed into the Exemplars-Unified Query Correlation (EUQC) module to interact with the query features in a unified manner and produce the correlated query tensor. In the localization stage, the Scale-aware Multi-head Localization (SAML) module utilizes the query tensor to predict the confidence, location, and size of each potential object. Moreover, a scale-aware localization loss is introduced, which exploits flexible location associations and exemplar scales for supervision to optimize the model performance. Extensive experiments demonstrate that SQLNet outperforms state-of-the-art methods on popular CAC benchmarks, achieving excellent performance not only in counting accuracy but also in localization and bounding box generation. Our codes will be available at https://github.com/HCPLab-SYSU/SQLNet
Spatio-Temporal Graph Neural Point Process for Traffic Congestion Event Prediction
Nov 15, 2023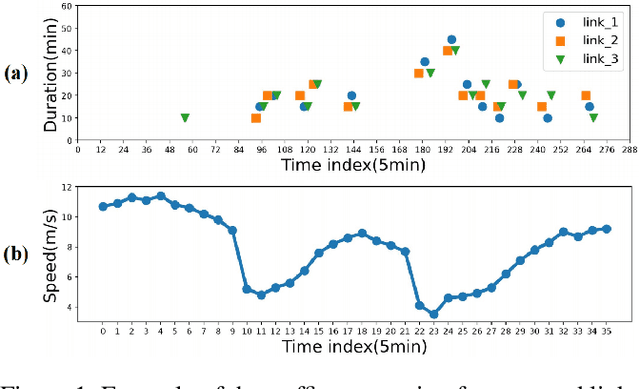

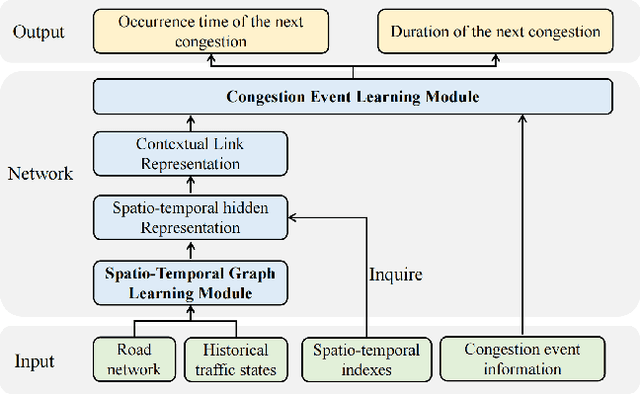
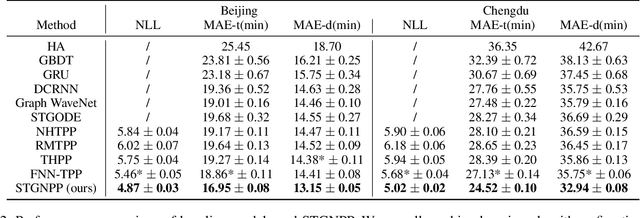
Traffic congestion event prediction is an important yet challenging task in intelligent transportation systems. Many existing works about traffic prediction integrate various temporal encoders and graph convolution networks (GCNs), called spatio-temporal graph-based neural networks, which focus on predicting dense variables such as flow, speed and demand in time snapshots, but they can hardly forecast the traffic congestion events that are sparsely distributed on the continuous time axis. In recent years, neural point process (NPP) has emerged as an appropriate framework for event prediction in continuous time scenarios. However, most conventional works about NPP cannot model the complex spatio-temporal dependencies and congestion evolution patterns. To address these limitations, we propose a spatio-temporal graph neural point process framework, named STGNPP for traffic congestion event prediction. Specifically, we first design the spatio-temporal graph learning module to fully capture the long-range spatio-temporal dependencies from the historical traffic state data along with the road network. The extracted spatio-temporal hidden representation and congestion event information are then fed into a continuous gated recurrent unit to model the congestion evolution patterns. In particular, to fully exploit the periodic information, we also improve the intensity function calculation of the point process with a periodic gated mechanism. Finally, our model simultaneously predicts the occurrence time and duration of the next congestion. Extensive experiments on two real-world datasets demonstrate that our method achieves superior performance in comparison to existing state-of-the-art approaches.
STEERER: Resolving Scale Variations for Counting and Localization via Selective Inheritance Learning
Aug 21, 2023Scale variation is a deep-rooted problem in object counting, which has not been effectively addressed by existing scale-aware algorithms. An important factor is that they typically involve cooperative learning across multi-resolutions, which could be suboptimal for learning the most discriminative features from each scale. In this paper, we propose a novel method termed STEERER (\textbf{S}elec\textbf{T}iv\textbf{E} inh\textbf{ER}itance l\textbf{E}a\textbf{R}ning) that addresses the issue of scale variations in object counting. STEERER selects the most suitable scale for patch objects to boost feature extraction and only inherits discriminative features from lower to higher resolution progressively. The main insights of STEERER are a dedicated Feature Selection and Inheritance Adaptor (FSIA), which selectively forwards scale-customized features at each scale, and a Masked Selection and Inheritance Loss (MSIL) that helps to achieve high-quality density maps across all scales. Our experimental results on nine datasets with counting and localization tasks demonstrate the unprecedented scale generalization ability of STEERER. Code is available at \url{https://github.com/taohan10200/STEERER}.