 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFGTBT: Frequency-Guided Task-Balancing Transformer for Unified Facial Landmark Detection
Jan 19, 2026Recently, deep learning based facial landmark detection (FLD) methods have achieved considerable success. However, in challenging scenarios such as large pose variations, illumination changes, and facial expression variations, they still struggle to accurately capture the geometric structure of the face, resulting in performance degradation. Moreover, the limited size and diversity of existing FLD datasets hinder robust model training, leading to reduced detection accuracy. To address these challenges, we propose a Frequency-Guided Task-Balancing Transformer (FGTBT), which enhances facial structure perception through frequency-domain modeling and multi-dataset unified training. Specifically, we propose a novel Fine-Grained Multi-Task Balancing loss (FMB-loss), which moves beyond coarse task-level balancing by assigning weights to individual landmarks based on their occurrence across datasets. This enables more effective unified training and mitigates the issue of inconsistent gradient magnitudes. Additionally, a Frequency-Guided Structure-Aware (FGSA) model is designed to utilize frequency-guided structure injection and regularization to help learn facial structure constraints. Extensive experimental results on popular benchmark datasets demonstrate that the integration of the proposed FMB-loss and FGSA model into our FGTBT framework achieves performance comparable to state-of-the-art methods. The code is available at https://github.com/Xi0ngxinyu/FGTBT.
SAM2-UNet: Segment Anything 2 Makes Strong Encoder for Natural and Medical Image Segmentation
Aug 16, 2024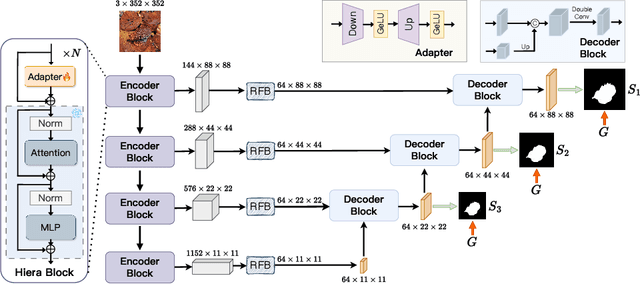



Image segmentation plays an important role in vision understanding. Recently, the emerging vision foundation models continuously achieved superior performance on various tasks. Following such success, in this paper, we prove that the Segment Anything Model 2 (SAM2) can be a strong encoder for U-shaped segmentation models. We propose a simple but effective framework, termed SAM2-UNet, for versatile image segmentation. Specifically, SAM2-UNet adopts the Hiera backbone of SAM2 as the encoder, while the decoder uses the classic U-shaped design. Additionally, adapters are inserted into the encoder to allow parameter-efficient fine-tuning. Preliminary experiments on various downstream tasks, such as camouflaged object detection, salient object detection, marine animal segmentation, mirror detection, and polyp segmentation, demonstrate that our SAM2-UNet can simply beat existing specialized state-of-the-art methods without bells and whistles. Project page: \url{https://github.com/WZH0120/SAM2-UNet}.
TP-DRSeg: Improving Diabetic Retinopathy Lesion Segmentation with Explicit Text-Prompts Assisted SAM
Jun 22, 2024



Recent advances in large foundation models, such as the Segment Anything Model (SAM), have demonstrated considerable promise across various tasks. Despite their progress, these models still encounter challenges in specialized medical image analysis, especially in recognizing subtle inter-class differences in Diabetic Retinopathy (DR) lesion segmentation. In this paper, we propose a novel framework that customizes SAM for text-prompted DR lesion segmentation, termed TP-DRSeg. Our core idea involves exploiting language cues to inject medical prior knowledge into the vision-only segmentation network, thereby combining the advantages of different foundation models and enhancing the credibility of segmentation. Specifically, to unleash the potential of vision-language models in the recognition of medical concepts, we propose an explicit prior encoder that transfers implicit medical concepts into explicit prior knowledge, providing explainable clues to excavate low-level features associated with lesions. Furthermore, we design a prior-aligned injector to inject explicit priors into the segmentation process, which can facilitate knowledge sharing across multi-modality features and allow our framework to be trained in a parameter-efficient fashion. Experimental results demonstrate the superiority of our framework over other traditional models and foundation model variants.
AlignSAM: Aligning Segment Anything Model to Open Context via Reinforcement Learning
Jun 01, 2024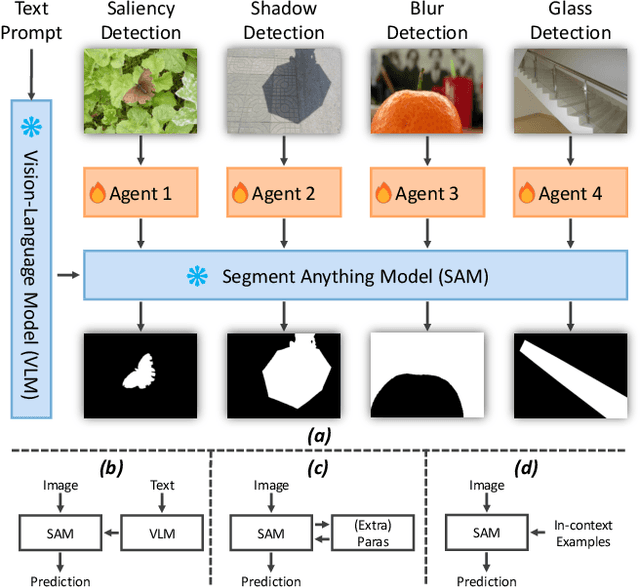


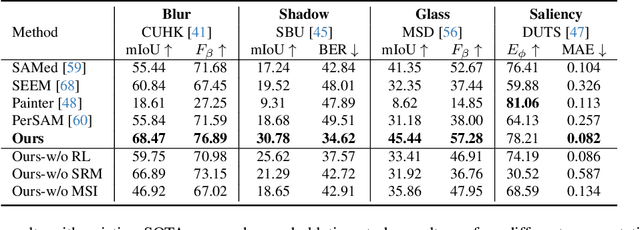
Powered by massive curated training data, Segment Anything Model (SAM) has demonstrated its impressive generalization capabilities in open-world scenarios with the guidance of prompts. However, the vanilla SAM is class agnostic and heavily relies on user-provided prompts to segment objects of interest. Adapting this method to diverse tasks is crucial for accurate target identification and to avoid suboptimal segmentation results. In this paper, we propose a novel framework, termed AlignSAM, designed for automatic prompting for aligning SAM to an open context through reinforcement learning. Anchored by an agent, AlignSAM enables the generality of the SAM model across diverse downstream tasks while keeping its parameters frozen. Specifically, AlignSAM initiates a prompting agent to iteratively refine segmentation predictions by interacting with the foundational model. It integrates a reinforcement learning policy network to provide informative prompts to the foundational models. Additionally, a semantic recalibration module is introduced to provide fine-grained labels of prompts, enhancing the model's proficiency in handling tasks encompassing explicit and implicit semantics. Experiments conducted on various challenging segmentation tasks among existing foundation models demonstrate the superiority of the proposed AlignSAM over state-of-the-art approaches. Project page: \url{https://github.com/Duojun-Huang/AlignSAM-CVPR2024}.
Annotation-Efficient Polyp Segmentation via Active Learning
Mar 21, 2024Deep learning-based techniques have proven effective in polyp segmentation tasks when provided with sufficient pixel-wise labeled data. However, the high cost of manual annotation has created a bottleneck for model generalization. To minimize annotation costs, we propose a deep active learning framework for annotation-efficient polyp segmentation. In practice, we measure the uncertainty of each sample by examining the similarity between features masked by the prediction map of the polyp and the background area. Since the segmentation model tends to perform weak in samples with indistinguishable features of foreground and background areas, uncertainty sampling facilitates the fitting of under-learning data. Furthermore, clustering image-level features weighted by uncertainty identify samples that are both uncertain and representative. To enhance the selectivity of the active selection strategy, we propose a novel unsupervised feature discrepancy learning mechanism. The selection strategy and feature optimization work in tandem to achieve optimal performance with a limited annotation budget. Extensive experimental results have demonstrated that our proposed method achieved state-of-the-art performance compared to other competitors on both a public dataset and a large-scale in-house dataset.
Semi- and Weakly-Supervised Learning for Mammogram Mass Segmentation with Limited Annotations
Mar 14, 2024



Accurate identification of breast masses is crucial in diagnosing breast cancer; however, it can be challenging due to their small size and being camouflaged in surrounding normal glands. Worse still, it is also expensive in clinical practice to obtain adequate pixel-wise annotations for training deep neural networks. To overcome these two difficulties with one stone, we propose a semi- and weakly-supervised learning framework for mass segmentation that utilizes limited strongly-labeled samples and sufficient weakly-labeled samples to achieve satisfactory performance. The framework consists of an auxiliary branch to exclude lesion-irrelevant background areas, a segmentation branch for final prediction, and a spatial prompting module to integrate the complementary information of the two branches. We further disentangle encoded obscure features into lesion-related and others to boost performance. Experiments on CBIS-DDSM and INbreast datasets demonstrate the effectiveness of our method.
Long-term Wind Power Forecasting with Hierarchical Spatial-Temporal Transformer
May 30, 2023Wind power is attracting increasing attention around the world due to its renewable, pollution-free, and other advantages. However, safely and stably integrating the high permeability intermittent power energy into electric power systems remains challenging. Accurate wind power forecasting (WPF) can effectively reduce power fluctuations in power system operations. Existing methods are mainly designed for short-term predictions and lack effective spatial-temporal feature augmentation. In this work, we propose a novel end-to-end wind power forecasting model named Hierarchical Spatial-Temporal Transformer Network (HSTTN) to address the long-term WPF problems. Specifically, we construct an hourglass-shaped encoder-decoder framework with skip-connections to jointly model representations aggregated in hierarchical temporal scales, which benefits long-term forecasting. Based on this framework, we capture the inter-scale long-range temporal dependencies and global spatial correlations with two parallel Transformer skeletons and strengthen the intra-scale connections with downsampling and upsampling operations. Moreover, the complementary information from spatial and temporal features is fused and propagated in each other via Contextual Fusion Blocks (CFBs) to promote the prediction further. Extensive experimental results on two large-scale real-world datasets demonstrate the superior performance of our HSTTN over existing solutions.