 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakeRadar: Probing Forgery Outliers to Detect Unknown Deepfake Videos
Dec 16, 2025In this paper, we propose FakeRadar, a novel deepfake video detection framework designed to address the challenges of cross-domain generalization in real-world scenarios. Existing detection methods typically rely on manipulation-specific cues, performing well on known forgery types but exhibiting severe limitations against emerging manipulation techniques. This poor generalization stems from their inability to adapt effectively to unseen forgery patterns. To overcome this, we leverage large-scale pretrained models (e.g. CLIP) to proactively probe the feature space, explicitly highlighting distributional gaps between real videos, known forgeries, and unseen manipulations. Specifically, FakeRadar introduces Forgery Outlier Probing, which employs dynamic subcluster modeling and cluster-conditional outlier generation to synthesize outlier samples near boundaries of estimated subclusters, simulating novel forgery artifacts beyond known manipulation types. Additionally, we design Outlier-Guided Tri-Training, which optimizes the detector to distinguish real, fake, and outlier samples using proposed outlier-driven contrastive learning and outlier-conditioned cross-entropy losses. Experiments show that FakeRadar outperforms existing methods across various benchmark datasets for deepfake video detection, particularly in cross-domain evaluations, by handling the variety of emerging manipulation techniques.
Mobile-Agent-RAG: Driving Smart Multi-Agent Coordination with Contextual Knowledge Empowerment for Long-Horizon Mobile Automation
Nov 15, 2025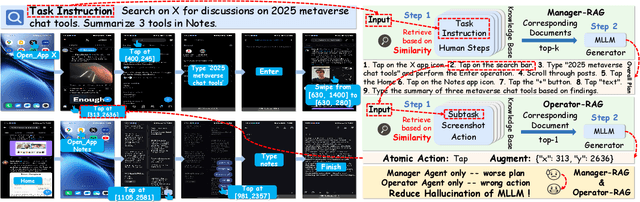
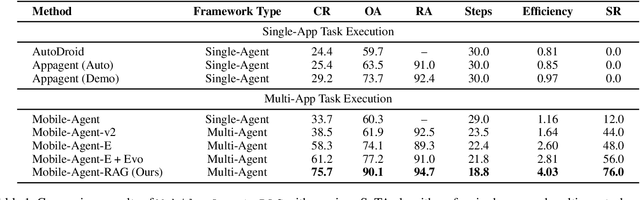
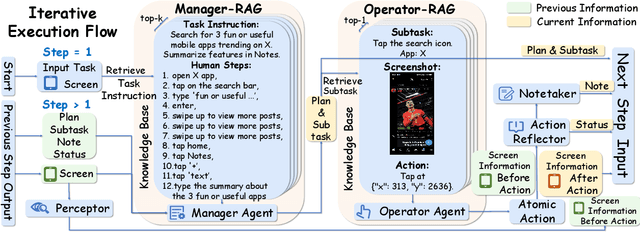
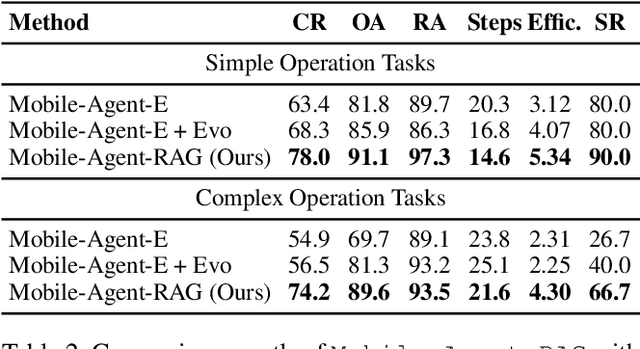
Mobile agents show immense potential, yet current state-of-the-art (SoTA) agents exhibit inadequate success rates on real-world, long-horizon, cross-application tasks. We attribute this bottleneck to the agents' excessive reliance on static, internal knowledge within MLLMs, which leads to two critical failure points: 1) strategic hallucinations in high-level planning and 2) operational errors during low-level execution on user interfaces (UI). The core insight of this paper is that high-level planning and low-level UI operations require fundamentally distinct types of knowledge. Planning demands high-level, strategy-oriented experiences, whereas operations necessitate low-level, precise instructions closely tied to specific app UIs. Motivated by these insights, we propose Mobile-Agent-RAG, a novel hierarchical multi-agent framework that innovatively integrates dual-level retrieval augmentation. At the planning stage, we introduce Manager-RAG to reduce strategic hallucinations by retrieving human-validated comprehensive task plans that provide high-level guidance. At the execution stage, we develop Operator-RAG to improve execution accuracy by retrieving the most precise low-level guidance for accurate atomic actions, aligned with the current app and subtask. To accurately deliver these knowledge types, we construct two specialized retrieval-oriented knowledge bases. Furthermore, we introduce Mobile-Eval-RAG, a challenging benchmark for evaluating such agents on realistic multi-app, long-horizon tasks. Extensive experiments demonstrate that Mobile-Agent-RAG significantly outperforms SoTA baselines, improving task completion rate by 11.0% and step efficiency by 10.2%, establishing a robust paradigm for context-aware, reliable multi-agent mobile automation.
Style-Preserving Lip Sync via Audio-Aware Style Reference
Aug 10, 2024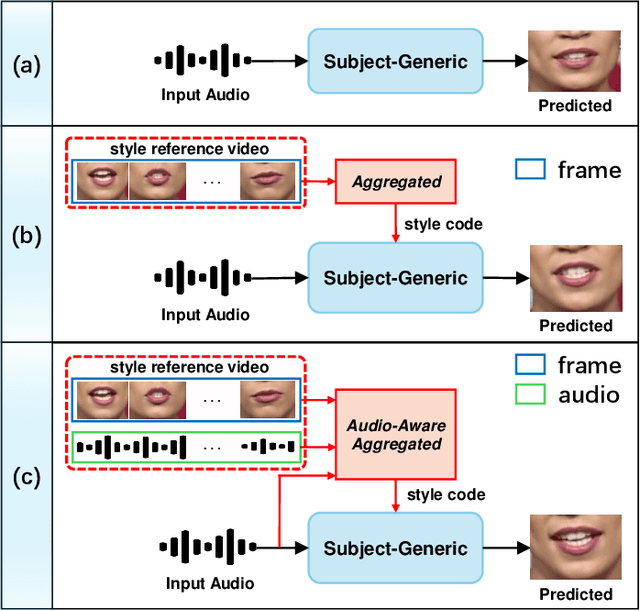
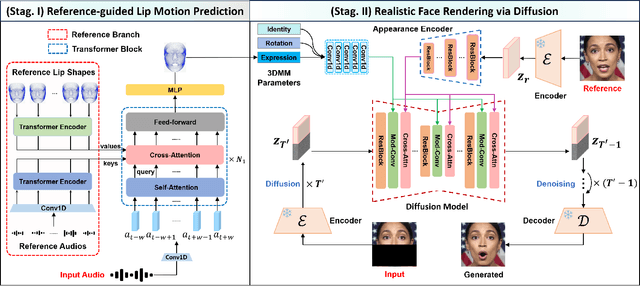

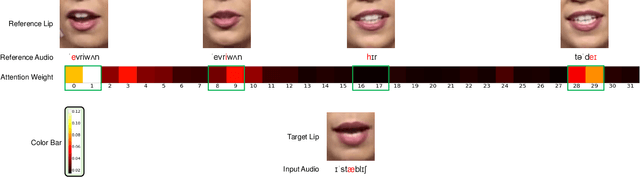
Audio-driven lip sync has recently drawn significant attention due to its widespread application in the multimedia domain. Individuals exhibit distinct lip shapes when speaking the same utterance, attributed to the unique speaking styles of individuals, posing a notable challenge for audio-driven lip sync. Earlier methods for such task often bypassed the modeling of personalized speaking styles, resulting in sub-optimal lip sync conforming to the general styles. Recent lip sync techniques attempt to guide the lip sync for arbitrary audio by aggregating information from a style reference video, yet they can not preserve the speaking styles well due to their inaccuracy in style aggregation. This work proposes an innovative audio-aware style reference scheme that effectively leverages the relationships between input audio and reference audio from style reference video to address the style-preserving audio-driven lip sync. Specifically, we first develop an advanced Transformer-based model adept at predicting lip motion corresponding to the input audio, augmented by the style information aggregated through cross-attention layers from style reference video. Afterwards, to better render the lip motion into realistic talking face video, we devise a conditional latent diffusion model, integrating lip motion through modulated convolutional layers and fusing reference facial images via spatial cross-attention layers. Extensive experiments validate the efficacy of the proposed approach in achieving precise lip sync, preserving speaking styles, and generating high-fidelity, realistic talking face videos.
Learning Background Prompts to Discover Implicit Knowledge for Open Vocabulary Object Detection
Jun 01, 2024Open vocabulary object detection (OVD) aims at seeking an optimal object detector capable of recognizing objects from both base and novel categories. Recent advances leverage knowledge distillation to transfer insightful knowledge from pre-trained large-scale vision-language models to the task of object detection, significantly generalizing the powerful capabilities of the detector to identify more unknown object categories. However, these methods face significant challenges in background interpretation and model overfitting and thus often result in the loss of crucial background knowledge, giving rise to sub-optimal inference performance of the detector. To mitigate these issues, we present a novel OVD framework termed LBP to propose learning background prompts to harness explored implicit background knowledge, thus enhancing the detection performance w.r.t. base and novel categories. Specifically, we devise three modules: Background Category-specific Prompt, Background Object Discovery, and Inference Probability Rectification, to empower the detector to discover, represent, and leverage implicit object knowledge explored from background proposals. Evaluation on two benchmark datasets, OV-COCO and OV-LVIS, demonstrates the superiority of our proposed method over existing state-of-the-art approaches in handling the OVD tasks.
AlignSAM: Aligning Segment Anything Model to Open Context via Reinforcement Learning
Jun 01, 2024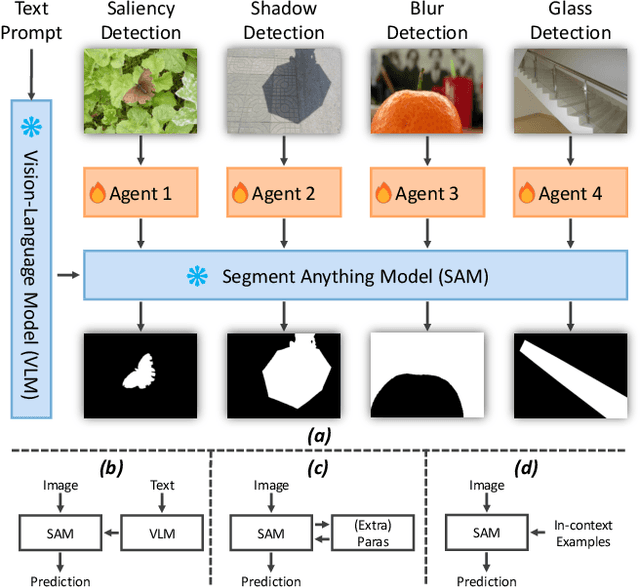


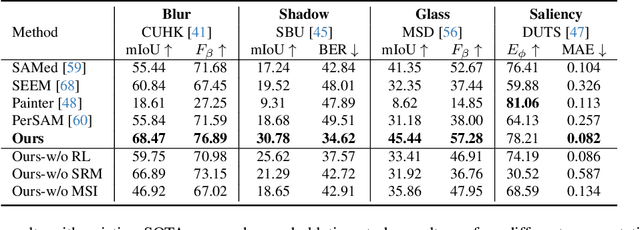
Powered by massive curated training data, Segment Anything Model (SAM) has demonstrated its impressive generalization capabilities in open-world scenarios with the guidance of prompts. However, the vanilla SAM is class agnostic and heavily relies on user-provided prompts to segment objects of interest. Adapting this method to diverse tasks is crucial for accurate target identification and to avoid suboptimal segmentation results. In this paper, we propose a novel framework, termed AlignSAM, designed for automatic prompting for aligning SAM to an open context through reinforcement learning. Anchored by an agent, AlignSAM enables the generality of the SAM model across diverse downstream tasks while keeping its parameters frozen. Specifically, AlignSAM initiates a prompting agent to iteratively refine segmentation predictions by interacting with the foundational model. It integrates a reinforcement learning policy network to provide informative prompts to the foundational models. Additionally, a semantic recalibration module is introduced to provide fine-grained labels of prompts, enhancing the model's proficiency in handling tasks encompassing explicit and implicit semantics. Experiments conducted on various challenging segmentation tasks among existing foundation models demonstrate the superiority of the proposed AlignSAM over state-of-the-art approaches. Project page: \url{https://github.com/Duojun-Huang/AlignSAM-CVPR2024}.
Adaptive Betweenness Clustering for Semi-Supervised Domain Adaptation
Jan 21, 2024Compared to unsupervised domain adaptation, semi-supervised domain adaptation (SSDA) aims to significantly improve the classification performance and generalization capability of the model by leveraging the presence of a small amount of labeled data from the target domain. Several SSDA approaches have been developed to enable semantic-aligned feature confusion between labeled (or pseudo labeled) samples across domains; nevertheless, owing to the scarcity of semantic label information of the target domain, they were arduous to fully realize their potential. In this study, we propose a novel SSDA approach named Graph-based Adaptive Betweenness Clustering (G-ABC) for achieving categorical domain alignment, which enables cross-domain semantic alignment by mandating semantic transfer from labeled data of both the source and target domains to unlabeled target samples. In particular, a heterogeneous graph is initially constructed to reflect the pairwise relationships between labeled samples from both domains and unlabeled ones of the target domain. Then, to degrade the noisy connectivity in the graph, connectivity refinement is conducted by introducing two strategies, namely Confidence Uncertainty based Node Removal and Prediction Dissimilarity based Edge Pruning. Once the graph has been refined, Adaptive Betweenness Clustering is introduced to facilitate semantic transfer by using across-domain betweenness clustering and within-domain betweenness clustering, thereby propagating semantic label information from labeled samples across domains to unlabeled target data. Extensive experiments on three standard benchmark datasets, namely DomainNet, Office-Home, and Office-31, indicated that our method outperforms previous state-of-the-art SSDA approaches, demonstrating the superiority of the proposed G-ABC algorithm.
* 16 pages, 9 figures, published to IEEE TIP
Inter-Domain Mixup for Semi-Supervised Domain Adaptation
Jan 21, 2024Semi-supervised domain adaptation (SSDA) aims to bridge source and target domain distributions, with a small number of target labels available, achieving better classification performance than unsupervised domain adaptation (UDA). However, existing SSDA work fails to make full use of label information from both source and target domains for feature alignment across domains, resulting in label mismatch in the label space during model testing. This paper presents a novel SSDA approach, Inter-domain Mixup with Neighborhood Expansion (IDMNE), to tackle this issue. Firstly, we introduce a cross-domain feature alignment strategy, Inter-domain Mixup, that incorporates label information into model adaptation. Specifically, we employ sample-level and manifold-level data mixing to generate compatible training samples. These newly established samples, combined with reliable and actual label information, display diversity and compatibility across domains, while such extra supervision thus facilitates cross-domain feature alignment and mitigates label mismatch. Additionally, we utilize Neighborhood Expansion to leverage high-confidence pseudo-labeled samples in the target domain, diversifying the label information of the target domain and thereby further increasing the performance of the adaptation model. Accordingly, the proposed approach outperforms existing state-of-the-art methods, achieving significant accuracy improvements on popular SSDA benchmarks, including DomainNet, Office-Home, and Office-31.
FedDiv: Collaborative Noise Filtering for Federated Learning with Noisy Labels
Dec 20, 2023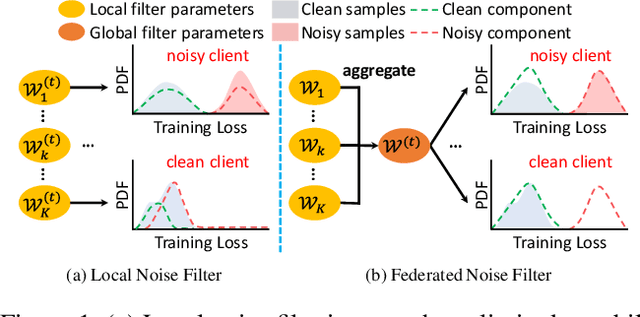
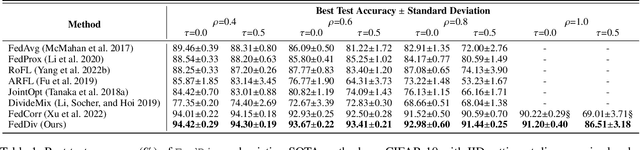
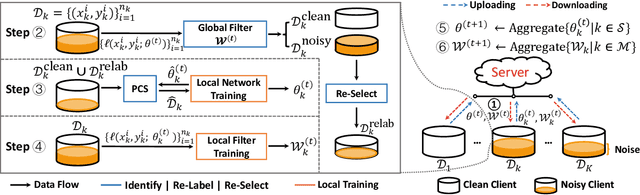
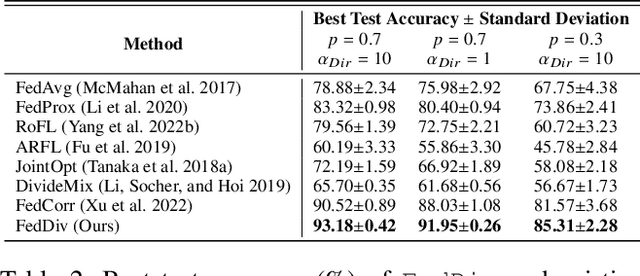
Federated learning with noisy labels (F-LNL) aims at seeking an optimal server model via collaborative distributed learning by aggregating multiple client models trained with local noisy or clean samples. On the basis of a federated learning framework, recent advances primarily adopt label noise filtering to separate clean samples from noisy ones on each client, thereby mitigating the negative impact of label noise. However, these prior methods do not learn noise filters by exploiting knowledge across all clients, leading to sub-optimal and inferior noise filtering performance and thus damaging training stability. In this paper, we present FedDiv to tackle the challenges of F-LNL. Specifically, we propose a global noise filter called Federated Noise Filter for effectively identifying samples with noisy labels on every client, thereby raising stability during local training sessions. Without sacrificing data privacy, this is achieved by modeling the global distribution of label noise across all clients. Then, in an effort to make the global model achieve higher performance, we introduce a Predictive Consistency based Sampler to identify more credible local data for local model training, thus preventing noise memorization and further boosting the training stability. Extensive experiments on CIFAR-10, CIFAR-100, and Clothing1M demonstrate that \texttt{FedDiv} achieves superior performance over state-of-the-art F-LNL methods under different label noise settings for both IID and non-IID data partitions. Source code is publicly available at https://github.com/lijichang/FLNL-FedDiv.
Divide and Adapt: Active Domain Adaptation via Customized Learning
Jul 21, 2023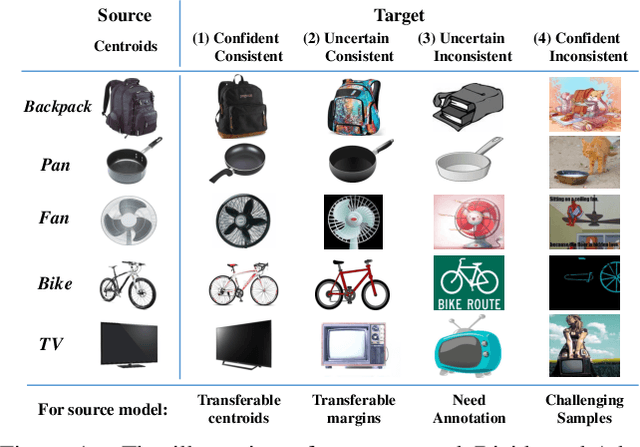
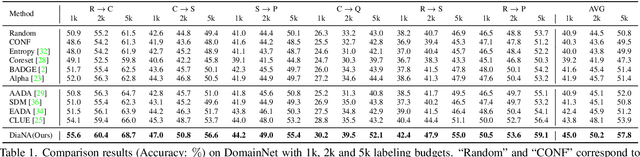
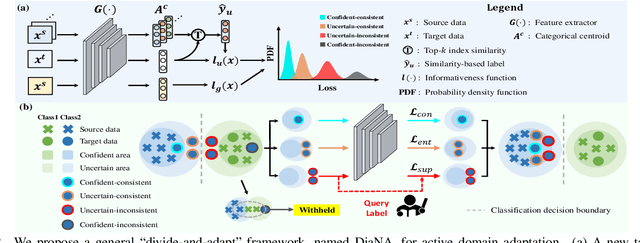
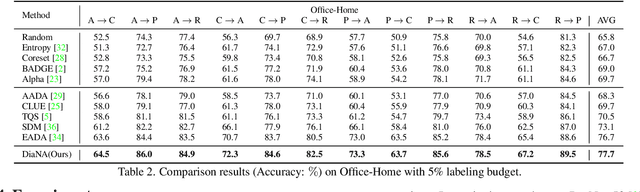
Active domain adaptation (ADA) aims to improve the model adaptation performance by incorporating active learning (AL) techniques to label a maximally-informative subset of target samples. Conventional AL methods do not consider the existence of domain shift, and hence, fail to identify the truly valuable samples in the context of domain adaptation. To accommodate active learning and domain adaption, the two naturally different tasks, in a collaborative framework, we advocate that a customized learning strategy for the target data is the key to the success of ADA solutions. We present Divide-and-Adapt (DiaNA), a new ADA framework that partitions the target instances into four categories with stratified transferable properties. With a novel data subdivision protocol based on uncertainty and domainness, DiaNA can accurately recognize the most gainful samples. While sending the informative instances for annotation, DiaNA employs tailored learning strategies for the remaining categories. Furthermore, we propose an informativeness score that unifies the data partitioning criteria. This enables the use of a Gaussian mixture model (GMM) to automatically sample unlabeled data into the proposed four categories. Thanks to the "divideand-adapt" spirit, DiaNA can handle data with large variations of domain gap. In addition, we show that DiaNA can generalize to different domain adaptation settings, such as unsupervised domain adaptation (UDA), semi-supervised domain adaptation (SSDA), source-free domain adaptation (SFDA), etc.
Neighborhood Collective Estimation for Noisy Label Identification and Correction
Aug 05, 2022Learning with noisy labels (LNL) aims at designing strategies to improve model performance and generalization by mitigating the effects of model overfitting to noisy labels. The key success of LNL lies in identifying as many clean samples as possible from massive noisy data, while rectifying the wrongly assigned noisy labels. Recent advances employ the predicted label distributions of individual samples to perform noise verification and noisy label correction, easily giving rise to confirmation bias. To mitigate this issue, we propose Neighborhood Collective Estimation, in which the predictive reliability of a candidate sample is re-estimated by contrasting it against its feature-space nearest neighbors. Specifically, our method is divided into two steps: 1) Neighborhood Collective Noise Verification to separate all training samples into a clean or noisy subset, 2) Neighborhood Collective Label Correction to relabel noisy samples, and then auxiliary techniques are used to assist further model optimization. Extensive experiments on four commonly used benchmark datasets, i.e., CIFAR-10, CIFAR-100, Clothing-1M and Webvision-1.0, demonstrate that our proposed method considerably outperforms state-of-the-art methods.