 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFakeRadar: Probing Forgery Outliers to Detect Unknown Deepfake Videos
Dec 16, 2025In this paper, we propose FakeRadar, a novel deepfake video detection framework designed to address the challenges of cross-domain generalization in real-world scenarios. Existing detection methods typically rely on manipulation-specific cues, performing well on known forgery types but exhibiting severe limitations against emerging manipulation techniques. This poor generalization stems from their inability to adapt effectively to unseen forgery patterns. To overcome this, we leverage large-scale pretrained models (e.g. CLIP) to proactively probe the feature space, explicitly highlighting distributional gaps between real videos, known forgeries, and unseen manipulations. Specifically, FakeRadar introduces Forgery Outlier Probing, which employs dynamic subcluster modeling and cluster-conditional outlier generation to synthesize outlier samples near boundaries of estimated subclusters, simulating novel forgery artifacts beyond known manipulation types. Additionally, we design Outlier-Guided Tri-Training, which optimizes the detector to distinguish real, fake, and outlier samples using proposed outlier-driven contrastive learning and outlier-conditioned cross-entropy losses. Experiments show that FakeRadar outperforms existing methods across various benchmark datasets for deepfake video detection, particularly in cross-domain evaluations, by handling the variety of emerging manipulation techniques.
Style-Preserving Lip Sync via Audio-Aware Style Reference
Aug 10, 2024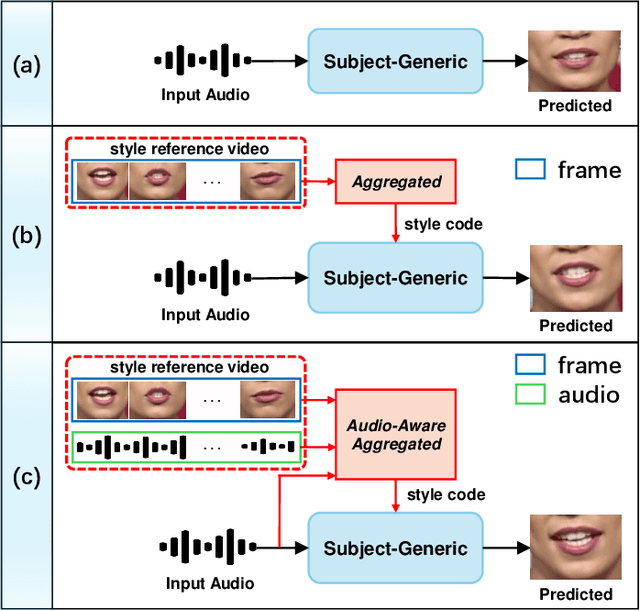
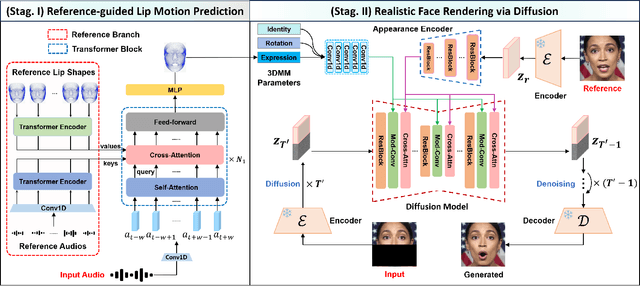

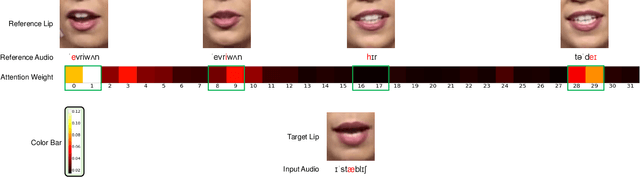
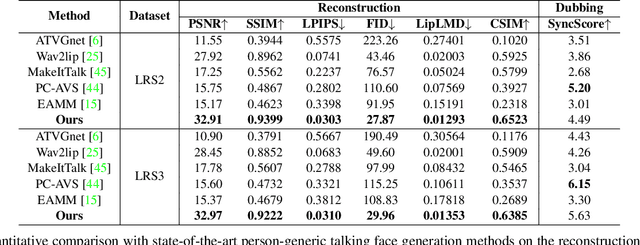
Audio-driven lip sync has recently drawn significant attention due to its widespread application in the multimedia domain. Individuals exhibit distinct lip shapes when speaking the same utterance, attributed to the unique speaking styles of individuals, posing a notable challenge for audio-driven lip sync. Earlier methods for such task often bypassed the modeling of personalized speaking styles, resulting in sub-optimal lip sync conforming to the general styles. Recent lip sync techniques attempt to guide the lip sync for arbitrary audio by aggregating information from a style reference video, yet they can not preserve the speaking styles well due to their inaccuracy in style aggregation. This work proposes an innovative audio-aware style reference scheme that effectively leverages the relationships between input audio and reference audio from style reference video to address the style-preserving audio-driven lip sync. Specifically, we first develop an advanced Transformer-based model adept at predicting lip motion corresponding to the input audio, augmented by the style information aggregated through cross-attention layers from style reference video. Afterwards, to better render the lip motion into realistic talking face video, we devise a conditional latent diffusion model, integrating lip motion through modulated convolutional layers and fusing reference facial images via spatial cross-attention layers. Extensive experiments validate the efficacy of the proposed approach in achieving precise lip sync, preserving speaking styles, and generating high-fidelity, realistic talking face videos.
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
May 15, 2023
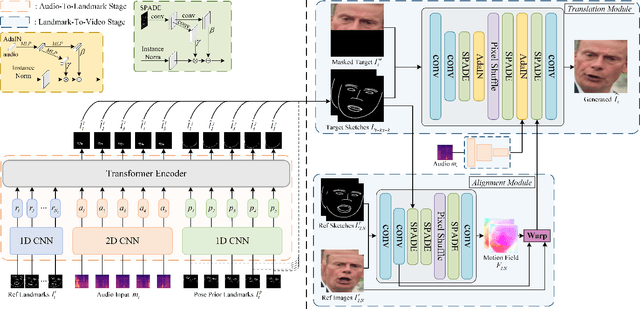
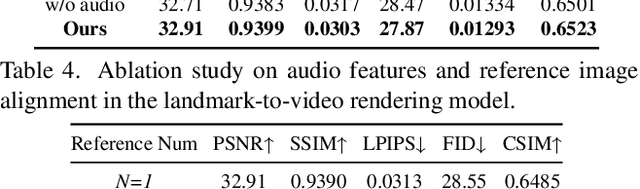
Generating talking face videos from audio attracts lots of research interest. A few person-specific methods can generate vivid videos but require the target speaker's videos for training or fine-tuning. Existing person-generic methods have difficulty in generating realistic and lip-synced videos while preserving identity information. To tackle this problem, we propose a two-stage framework consisting of audio-to-landmark generation and landmark-to-video rendering procedures. First, we devise a novel Transformer-based landmark generator to infer lip and jaw landmarks from the audio. Prior landmark characteristics of the speaker's face are employed to make the generated landmarks coincide with the facial outline of the speaker. Then, a video rendering model is built to translate the generated landmarks into face images. During this stage, prior appearance information is extracted from the lower-half occluded target face and static reference images, which helps generate realistic and identity-preserving visual content. For effectively exploring the prior information of static reference images, we align static reference images with the target face's pose and expression based on motion fields. Moreover, auditory features are reused to guarantee that the generated face images are well synchronized with the audio. Extensive experiments demonstrate that our method can produce more realistic, lip-synced, and identity-preserving videos than existing person-generic talking face generation methods.