 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Perceptual Artifacts: A Fine-Grained Benchmark for Interpretable AI-Generated Image Detection
Jan 27, 2026Current AI-Generated Image (AIGI) detection approaches predominantly rely on binary classification to distinguish real from synthetic images, often lacking interpretable or convincing evidence to substantiate their decisions. This limitation stems from existing AIGI detection benchmarks, which, despite featuring a broad collection of synthetic images, remain restricted in their coverage of artifact diversity and lack detailed, localized annotations. To bridge this gap, we introduce a fine-grained benchmark towards eXplainable AI-Generated image Detection, named X-AIGD, which provides pixel-level, categorized annotations of perceptual artifacts, spanning low-level distortions, high-level semantics, and cognitive-level counterfactuals. These comprehensive annotations facilitate fine-grained interpretability evaluation and deeper insight into model decision-making processes. Our extensive investigation using X-AIGD provides several key insights: (1) Existing AIGI detectors demonstrate negligible reliance on perceptual artifacts, even at the most basic distortion level. (2) While AIGI detectors can be trained to identify specific artifacts, they still substantially base their judgment on uninterpretable features. (3) Explicitly aligning model attention with artifact regions can increase the interpretability and generalization of detectors. The data and code are available at: https://github.com/Coxy7/X-AIGD.
Thinking Before You Speak: A Proactive Test-time Scaling Approach
Aug 27, 2025
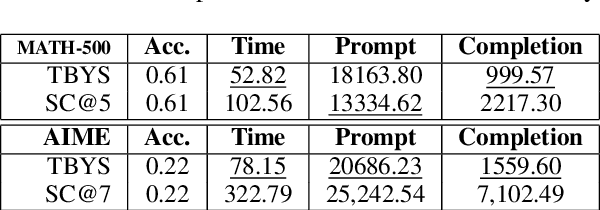
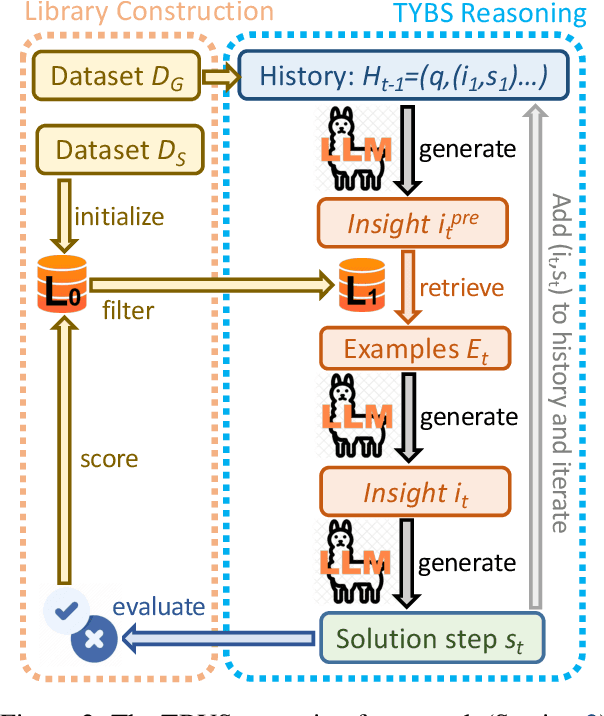
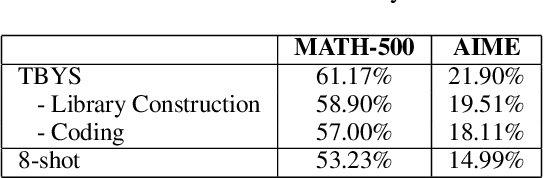
Large Language Models (LLMs) often exhibit deficiencies with complex reasoning tasks, such as maths, which we attribute to the discrepancy between human reasoning patterns and those presented in the LLMs' training data. When dealing with complex problems, humans tend to think carefully before expressing solutions. However, they often do not articulate their inner thoughts, including their intentions and chosen methodologies. Consequently, critical insights essential for bridging reasoning steps may be absent in training data collected from human sources. To bridge this gap, we proposes inserting \emph{insight}s between consecutive reasoning steps, which review the status and initiate the next reasoning steps. Unlike prior prompting strategies that rely on a single or a workflow of static prompts to facilitate reasoning, \emph{insight}s are \emph{proactively} generated to guide reasoning processes. We implement our idea as a reasoning framework, named \emph{Thinking Before You Speak} (TBYS), and design a pipeline for automatically collecting and filtering in-context examples for the generation of \emph{insight}s, which alleviates human labeling efforts and fine-tuning overheads. Experiments on challenging mathematical datasets verify the effectiveness of TBYS. Project website: https://gitee.com/jswrt/TBYS
Can We Achieve Efficient Diffusion without Self-Attention? Distilling Self-Attention into Convolutions
Apr 30, 2025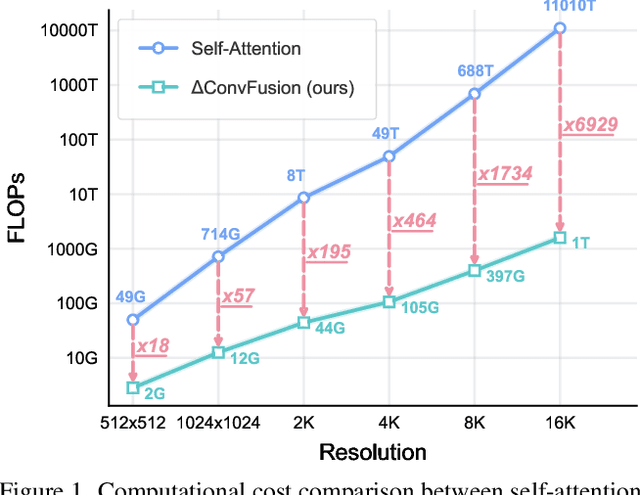
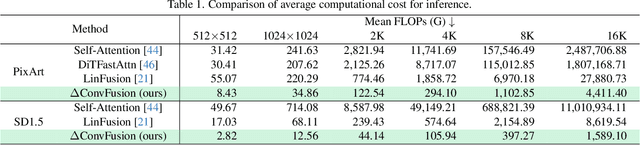

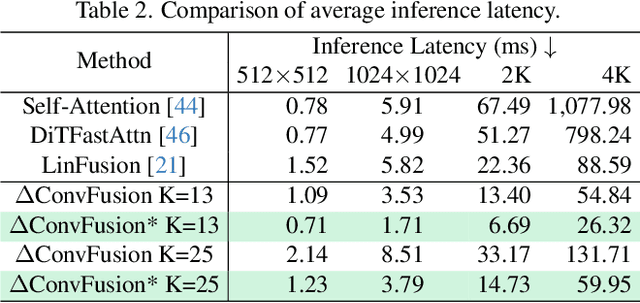
Contemporary diffusion models built upon U-Net or Diffusion Transformer (DiT) architectures have revolutionized image generation through transformer-based attention mechanisms. The prevailing paradigm has commonly employed self-attention with quadratic computational complexity to handle global spatial relationships in complex images, thereby synthesizing high-fidelity images with coherent visual semantics.Contrary to conventional wisdom, our systematic layer-wise analysis reveals an interesting discrepancy: self-attention in pre-trained diffusion models predominantly exhibits localized attention patterns, closely resembling convolutional inductive biases. This suggests that global interactions in self-attention may be less critical than commonly assumed.Driven by this, we propose \(\Delta\)ConvFusion to replace conventional self-attention modules with Pyramid Convolution Blocks (\(\Delta\)ConvBlocks).By distilling attention patterns into localized convolutional operations while keeping other components frozen, \(\Delta\)ConvFusion achieves performance comparable to transformer-based counterparts while reducing computational cost by 6929$\times$ and surpassing LinFusion by 5.42$\times$ in efficiency--all without compromising generative fidelity.
Decoder-Only LLMs are Better Controllers for Diffusion Models
Feb 06, 2025Groundbreaking advancements in text-to-image generation have recently been achieved with the emergence of diffusion models. These models exhibit a remarkable ability to generate highly artistic and intricately detailed images based on textual prompts. However, obtaining desired generation outcomes often necessitates repetitive trials of manipulating text prompts just like casting spells on a magic mirror, and the reason behind that is the limited capability of semantic understanding inherent in current image generation models. Specifically, existing diffusion models encode the text prompt input with a pre-trained encoder structure, which is usually trained on a limited number of image-caption pairs. The state-of-the-art large language models (LLMs) based on the decoder-only structure have shown a powerful semantic understanding capability as their architectures are more suitable for training on very large-scale unlabeled data. In this work, we propose to enhance text-to-image diffusion models by borrowing the strength of semantic understanding from large language models, and devise a simple yet effective adapter to allow the diffusion models to be compatible with the decoder-only structure. Meanwhile, we also provide a supporting theoretical analysis with various architectures (e.g., encoder-only, encoder-decoder, and decoder-only), and conduct extensive empirical evaluations to verify its effectiveness. The experimental results show that the enhanced models with our adapter module are superior to the stat-of-the-art models in terms of text-to-image generation quality and reliability.
SAM-COD: SAM-guided Unified Framework for Weakly-Supervised Camouflaged Object Detection
Aug 20, 2024



Most Camouflaged Object Detection (COD) methods heavily rely on mask annotations, which are time-consuming and labor-intensive to acquire. Existing weakly-supervised COD approaches exhibit significantly inferior performance compared to fully-supervised methods and struggle to simultaneously support all the existing types of camouflaged object labels, including scribbles, bounding boxes, and points. Even for Segment Anything Model (SAM), it is still problematic to handle the weakly-supervised COD and it typically encounters challenges of prompt compatibility of the scribble labels, extreme response, semantically erroneous response, and unstable feature representations, producing unsatisfactory results in camouflaged scenes. To mitigate these issues, we propose a unified COD framework in this paper, termed SAM-COD, which is capable of supporting arbitrary weakly-supervised labels. Our SAM-COD employs a prompt adapter to handle scribbles as prompts based on SAM. Meanwhile, we introduce response filter and semantic matcher modules to improve the quality of the masks obtained by SAM under COD prompts. To alleviate the negative impacts of inaccurate mask predictions, a new strategy of prompt-adaptive knowledge distillation is utilized to ensure a reliable feature representation. To validate the effectiveness of our approach, we have conducted extensive empirical experiments on three mainstream COD benchmarks. The results demonstrate the superiority of our method against state-of-the-art weakly-supervised and even fully-supervised methods.
Diff-Mosaic: Augmenting Realistic Representations in Infrared Small Target Detection via Diffusion Prior
Jun 02, 2024Recently, researchers have proposed various deep learning methods to accurately detect infrared targets with the characteristics of indistinct shape and texture. Due to the limited variety of infrared datasets, training deep learning models with good generalization poses a challenge. To augment the infrared dataset, researchers employ data augmentation techniques, which often involve generating new images by combining images from different datasets. However, these methods are lacking in two respects. In terms of realism, the images generated by mixup-based methods lack realism and are difficult to effectively simulate complex real-world scenarios. In terms of diversity, compared with real-world scenes, borrowing knowledge from another dataset inherently has a limited diversity. Currently, the diffusion model stands out as an innovative generative approach. Large-scale trained diffusion models have a strong generative prior that enables real-world modeling of images to generate diverse and realistic images. In this paper, we propose Diff-Mosaic, a data augmentation method based on the diffusion model. This model effectively alleviates the challenge of diversity and realism of data augmentation methods via diffusion prior. Specifically, our method consists of two stages. Firstly, we introduce an enhancement network called Pixel-Prior, which generates highly coordinated and realistic Mosaic images by harmonizing pixels. In the second stage, we propose an image enhancement strategy named Diff-Prior. This strategy utilizes diffusion priors to model images in the real-world scene, further enhancing the diversity and realism of the images. Extensive experiments have demonstrated that our approach significantly improves the performance of the detection network. The code is available at https://github.com/YupeiLin2388/Diff-Mosaic
Towards Better Adversarial Purification via Adversarial Denoising Diffusion Training
Apr 22, 2024

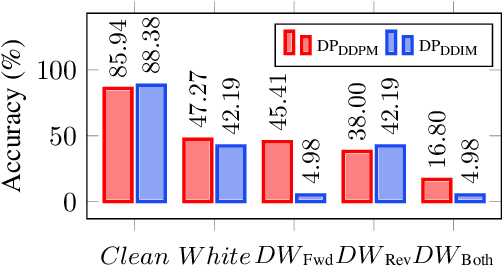

Recently, diffusion-based purification (DBP) has emerged as a promising approach for defending against adversarial attacks. However, previous studies have used questionable methods to evaluate the robustness of DBP models, their explanations of DBP robustness also lack experimental support. We re-examine DBP robustness using precise gradient, and discuss the impact of stochasticity on DBP robustness. To better explain DBP robustness, we assess DBP robustness under a novel attack setting, Deterministic White-box, and pinpoint stochasticity as the main factor in DBP robustness. Our results suggest that DBP models rely on stochasticity to evade the most effective attack direction, rather than directly countering adversarial perturbations. To improve the robustness of DBP models, we propose Adversarial Denoising Diffusion Training (ADDT). This technique uses Classifier-Guided Perturbation Optimization (CGPO) to generate adversarial perturbation through guidance from a pre-trained classifier, and uses Rank-Based Gaussian Mapping (RBGM) to convert adversarial pertubation into a normal Gaussian distribution. Empirical results show that ADDT improves the robustness of DBP models. Further experiments confirm that ADDT equips DBP models with the ability to directly counter adversarial perturbations.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024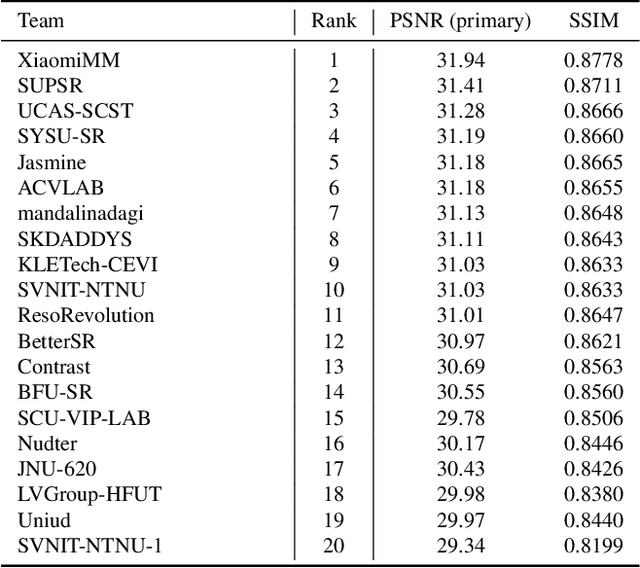
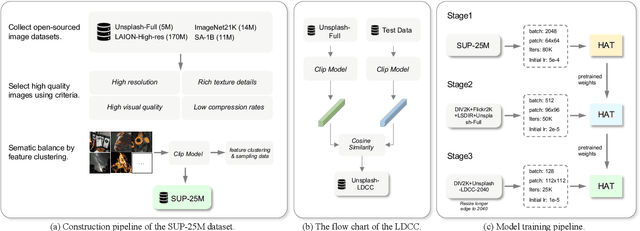
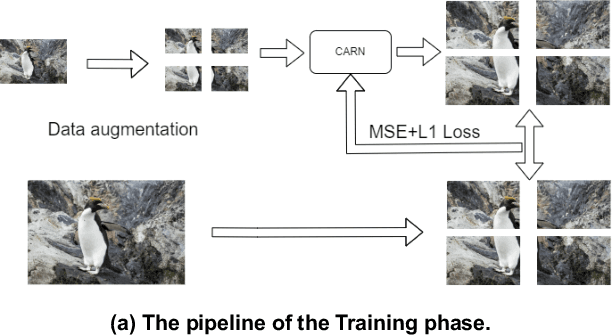
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
IDF-CR: Iterative Diffusion Process for Divide-and-Conquer Cloud Removal in Remote-sensing Images
Mar 18, 2024



Deep learning technologies have demonstrated their effectiveness in removing cloud cover from optical remote-sensing images. Convolutional Neural Networks (CNNs) exert dominance in the cloud removal tasks. However, constrained by the inherent limitations of convolutional operations, CNNs can address only a modest fraction of cloud occlusion. In recent years, diffusion models have achieved state-of-the-art (SOTA) proficiency in image generation and reconstruction due to their formidable generative capabilities. Inspired by the rapid development of diffusion models, we first present an iterative diffusion process for cloud removal (IDF-CR), which exhibits a strong generative capabilities to achieve component divide-and-conquer cloud removal. IDF-CR consists of a pixel space cloud removal module (Pixel-CR) and a latent space iterative noise diffusion network (IND). Specifically, IDF-CR is divided into two-stage models that address pixel space and latent space. The two-stage model facilitates a strategic transition from preliminary cloud reduction to meticulous detail refinement. In the pixel space stage, Pixel-CR initiates the processing of cloudy images, yielding a suboptimal cloud removal prior to providing the diffusion model with prior cloud removal knowledge. In the latent space stage, the diffusion model transforms low-quality cloud removal into high-quality clean output. We refine the Stable Diffusion by implementing ControlNet. In addition, an unsupervised iterative noise refinement (INR) module is introduced for diffusion model to optimize the distribution of the predicted noise, thereby enhancing advanced detail recovery. Our model performs best with other SOTA methods, including image reconstruction and optical remote-sensing cloud removal on the optical remote-sensing datasets.
Image Restoration Through Generalized Ornstein-Uhlenbeck Bridge
Dec 16, 2023


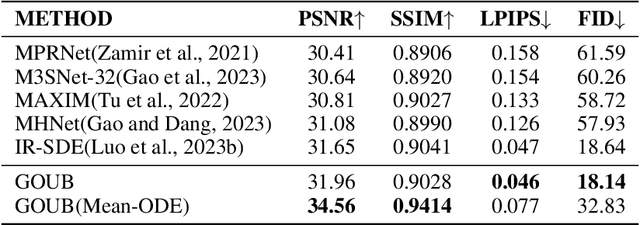
Diffusion models possess powerful generative capabilities enabling the mapping of noise to data using reverse stochastic differential equations. However, in image restoration tasks, the focus is on the mapping relationship from low-quality images to high-quality images. To address this, we introduced the Generalized Ornstein-Uhlenbeck Bridge (GOUB) model. By leveraging the natural mean-reverting property of the generalized OU process and further adjusting the variance of its steady-state distribution through the Doob's h-transform, we achieve diffusion mappings from point to point with minimal cost. This allows for end-to-end training, enabling the recovery of high-quality images from low-quality ones. Additionally, we uncovered the mathematical essence of some bridge models, all of which are special cases of the GOUB and empirically demonstrated the optimality of our proposed models. Furthermore, benefiting from our distinctive parameterization mechanism, we proposed the Mean-ODE model that is better at capturing pixel-level information and structural perceptions. Experimental results show that both models achieved state-of-the-art results in various tasks, including inpainting, deraining, and super-resolution. Code is available at https://github.com/Hammour-steak/GOUB.