 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop 10 Open Challenges Steering the Future of Diffusion Language Model and Its Variants
Jan 20, 2026The paradigm of Large Language Models (LLMs) is currently defined by auto-regressive (AR) architectures, which generate text through a sequential ``brick-by-brick'' process. Despite their success, AR models are inherently constrained by a causal bottleneck that limits global structural foresight and iterative refinement. Diffusion Language Models (DLMs) offer a transformative alternative, conceptualizing text generation as a holistic, bidirectional denoising process akin to a sculptor refining a masterpiece. However, the potential of DLMs remains largely untapped as they are frequently confined within AR-legacy infrastructures and optimization frameworks. In this Perspective, we identify ten fundamental challenges ranging from architectural inertia and gradient sparsity to the limitations of linear reasoning that prevent DLMs from reaching their ``GPT-4 moment''. We propose a strategic roadmap organized into four pillars: foundational infrastructure, algorithmic optimization, cognitive reasoning, and unified multimodal intelligence. By shifting toward a diffusion-native ecosystem characterized by multi-scale tokenization, active remasking, and latent thinking, we can move beyond the constraints of the causal horizon. We argue that this transition is essential for developing next-generation AI capable of complex structural reasoning, dynamic self-correction, and seamless multimodal integration.
Towards Any-Quality Image Segmentation via Generative and Adaptive Latent Space Enhancement
Jan 05, 2026Segment Anything Models (SAMs), known for their exceptional zero-shot segmentation performance, have garnered significant attention in the research community. Nevertheless, their performance drops significantly on severely degraded, low-quality images, limiting their effectiveness in real-world scenarios. To address this, we propose GleSAM++, which utilizes Generative Latent space Enhancement to boost robustness on low-quality images, thus enabling generalization across various image qualities. Additionally, to improve compatibility between the pre-trained diffusion model and the segmentation framework, we introduce two techniques, i.e., Feature Distribution Alignment (FDA) and Channel Replication and Expansion (CRE). However, the above components lack explicit guidance regarding the degree of degradation. The model is forced to implicitly fit a complex noise distribution that spans conditions from mild noise to severe artifacts, which substantially increases the learning burden and leads to suboptimal reconstructions. To address this issue, we further introduce a Degradation-aware Adaptive Enhancement (DAE) mechanism. The key principle of DAE is to decouple the reconstruction process for arbitrary-quality features into two stages: degradation-level prediction and degradation-aware reconstruction. Our method can be applied to pre-trained SAM and SAM2 with only minimal additional learnable parameters, allowing for efficient optimization. Extensive experiments demonstrate that GleSAM++ significantly improves segmentation robustness on complex degradations while maintaining generalization to clear images. Furthermore, GleSAM++ also performs well on unseen degradations, underscoring the versatility of our approach and dataset.
Boosting Segment Anything Model to Generalize Visually Non-Salient Scenarios
Jan 02, 2026Segment Anything Model (SAM), known for its remarkable zero-shot segmentation capabilities, has garnered significant attention in the community. Nevertheless, its performance is challenged when dealing with what we refer to as visually non-salient scenarios, where there is low contrast between the foreground and background. In these cases, existing methods often cannot capture accurate contours and fail to produce promising segmentation results. In this paper, we propose Visually Non-Salient SAM (VNS-SAM), aiming to enhance SAM's perception of visually non-salient scenarios while preserving its original zero-shot generalizability. We achieve this by effectively exploiting SAM's low-level features through two designs: Mask-Edge Token Interactive decoder and Non-Salient Feature Mining module. These designs help the SAM decoder gain a deeper understanding of non-salient characteristics with only marginal parameter increments and computational requirements. The additional parameters of VNS-SAM can be optimized within 4 hours, demonstrating its feasibility and practicality. In terms of data, we established VNS-SEG, a unified dataset for various VNS scenarios, with more than 35K images, in contrast to previous single-task adaptations. It is designed to make the model learn more robust VNS features and comprehensively benchmark the model's segmentation performance and generalizability on VNS scenarios. Extensive experiments across various VNS segmentation tasks demonstrate the superior performance of VNS-SAM, particularly under zero-shot settings, highlighting its potential for broad real-world applications. Codes and datasets are publicly available at https://guangqian-guo.github.io/VNS-SAM.
In vivo 3D ultrasound computed tomography of musculoskeletal tissues with generative neural physics
Aug 17, 2025Ultrasound computed tomography (USCT) is a radiation-free, high-resolution modality but remains limited for musculoskeletal imaging due to conventional ray-based reconstructions that neglect strong scattering. We propose a generative neural physics framework that couples generative networks with physics-informed neural simulation for fast, high-fidelity 3D USCT. By learning a compact surrogate of ultrasonic wave propagation from only dozens of cross-modality images, our method merges the accuracy of wave modeling with the efficiency and stability of deep learning. This enables accurate quantitative imaging of in vivo musculoskeletal tissues, producing spatial maps of acoustic properties beyond reflection-mode images. On synthetic and in vivo data (breast, arm, leg), we reconstruct 3D maps of tissue parameters in under ten minutes, with sensitivity to biomechanical properties in muscle and bone and resolution comparable to MRI. By overcoming computational bottlenecks in strongly scattering regimes, this approach advances USCT toward routine clinical assessment of musculoskeletal disease.
Multi-resolution Score-Based Variational Graphical Diffusion for Causal Disaster System Modeling and Inference
Apr 05, 2025Complex systems with intricate causal dependencies challenge accurate prediction. Effective modeling requires precise physical process representation, integration of interdependent factors, and incorporation of multi-resolution observational data. These systems manifest in both static scenarios with instantaneous causal chains and temporal scenarios with evolving dynamics, complicating modeling efforts. Current methods struggle to simultaneously handle varying resolutions, capture physical relationships, model causal dependencies, and incorporate temporal dynamics, especially with inconsistently sampled data from diverse sources. We introduce Temporal-SVGDM: Score-based Variational Graphical Diffusion Model for Multi-resolution observations. Our framework constructs individual SDEs for each variable at its native resolution, then couples these SDEs through a causal score mechanism where parent nodes inform child nodes' evolution. This enables unified modeling of both immediate causal effects in static scenarios and evolving dependencies in temporal scenarios. In temporal models, state representations are processed through a sequence prediction model to predict future states based on historical patterns and causal relationships. Experiments on real-world datasets demonstrate improved prediction accuracy and causal understanding compared to existing methods, with robust performance under varying levels of background knowledge. Our model exhibits graceful degradation across different disaster types, successfully handling both static earthquake scenarios and temporal hurricane and wildfire scenarios, while maintaining superior performance even with limited data.
Spatially-Heterogeneous Causal Bayesian Networks for Seismic Multi-Hazard Estimation: A Variational Approach with Gaussian Processes and Normalizing Flows
Apr 05, 2025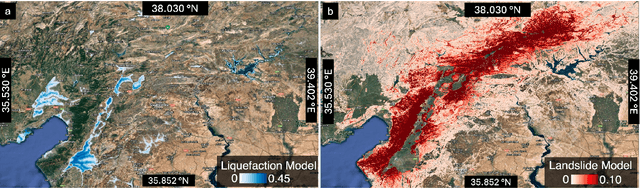



Post-earthquake hazard and impact estimation are critical for effective disaster response, yet current approaches face significant limitations. Traditional models employ fixed parameters regardless of geographical context, misrepresenting how seismic effects vary across diverse landscapes, while remote sensing technologies struggle to distinguish between co-located hazards. We address these challenges with a spatially-aware causal Bayesian network that decouples co-located hazards by modeling their causal relationships with location-specific parameters. Our framework integrates sensing observations, latent variables, and spatial heterogeneity through a novel combination of Gaussian Processes with normalizing flows, enabling us to capture how same earthquake produces different effects across varied geological and topographical features. Evaluations across three earthquakes demonstrate Spatial-VCBN achieves Area Under the Curve (AUC) improvements of up to 35.2% over existing methods. These results highlight the critical importance of modeling spatial heterogeneity in causal mechanisms for accurate disaster assessment, with direct implications for improving emergency response resource allocation.
TextCrafter: Accurately Rendering Multiple Texts in Complex Visual Scenes
Apr 01, 2025This paper explores the task of Complex Visual Text Generation (CVTG), which centers on generating intricate textual content distributed across diverse regions within visual images. In CVTG, image generation models often rendering distorted and blurred visual text or missing some visual text. To tackle these challenges, we propose TextCrafter, a novel multi-visual text rendering method. TextCrafter employs a progressive strategy to decompose complex visual text into distinct components while ensuring robust alignment between textual content and its visual carrier. Additionally, it incorporates a token focus enhancement mechanism to amplify the prominence of visual text during the generation process. TextCrafter effectively addresses key challenges in CVTG tasks, such as text confusion, omissions, and blurriness. Moreover, we present a new benchmark dataset, CVTG-2K, tailored to rigorously evaluate the performance of generative models on CVTG tasks. Extensive experiments demonstrate that our method surpasses state-of-the-art approaches.
Segment Any-Quality Images with Generative Latent Space Enhancement
Mar 16, 2025



Despite their success, Segment Anything Models (SAMs) experience significant performance drops on severely degraded, low-quality images, limiting their effectiveness in real-world scenarios. To address this, we propose GleSAM, which utilizes Generative Latent space Enhancement to boost robustness on low-quality images, thus enabling generalization across various image qualities. Specifically, we adapt the concept of latent diffusion to SAM-based segmentation frameworks and perform the generative diffusion process in the latent space of SAM to reconstruct high-quality representation, thereby improving segmentation. Additionally, we introduce two techniques to improve compatibility between the pre-trained diffusion model and the segmentation framework. Our method can be applied to pre-trained SAM and SAM2 with only minimal additional learnable parameters, allowing for efficient optimization. We also construct the LQSeg dataset with a greater diversity of degradation types and levels for training and evaluating the model. Extensive experiments demonstrate that GleSAM significantly improves segmentation robustness on complex degradations while maintaining generalization to clear images. Furthermore, GleSAM also performs well on unseen degradations, underscoring the versatility of our approach and dataset.
Less is More: On the Importance of Data Quality for Unit Test Generation
Feb 20, 2025Unit testing is crucial for software development and maintenance. Effective unit testing ensures and improves software quality, but writing unit tests is time-consuming and labor-intensive. Recent studies have proposed deep learning (DL) techniques or large language models (LLMs) to automate unit test generation. These models are usually trained or fine-tuned on large-scale datasets. Despite growing awareness of the importance of data quality, there has been limited research on the quality of datasets used for test generation. To bridge this gap, we systematically examine the impact of noise on the performance of learning-based test generation models. We first apply the open card sorting method to analyze the most popular and largest test generation dataset, Methods2Test, to categorize eight distinct types of noise. Further, we conduct detailed interviews with 17 domain experts to validate and assess the importance, reasonableness, and correctness of the noise taxonomy. Then, we propose CleanTest, an automated noise-cleaning framework designed to improve the quality of test generation datasets. CleanTest comprises three filters: a rule-based syntax filter, a rule-based relevance filter, and a model-based coverage filter. To evaluate its effectiveness, we apply CleanTest on two widely-used test generation datasets, i.e., Methods2Test and Atlas. Our findings indicate that 43.52% and 29.65% of datasets contain noise, highlighting its prevalence. Finally, we conduct comparative experiments using four LLMs (i.e., CodeBERT, AthenaTest, StarCoder, and CodeLlama7B) to assess the impact of noise on test generation performance. The results show that filtering noise positively influences the test generation ability of the models.
Challenges and recommendations for Electronic Health Records data extraction and preparation for dynamic prediction modelling in hospitalized patients -- a practical guide
Jan 17, 2025Dynamic predictive modeling using electronic health record (EHR) data has gained significant attention in recent years. The reliability and trustworthiness of such models depend heavily on the quality of the underlying data, which is largely determined by the stages preceding the model development: data extraction from EHR systems and data preparation. We list over forty challenges encountered during these stages and provide actionable recommendations for addressing them. These challenges are organized into four categories: cohort definition, outcome definition, feature engineering, and data cleaning. This list is designed to serve as a practical guide for data extraction engineers and researchers, supporting better practices and improving the quality and real-world applicability of dynamic prediction models in clinical settings.