 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextCrafter: Accurately Rendering Multiple Texts in Complex Visual Scenes
Apr 01, 2025This paper explores the task of Complex Visual Text Generation (CVTG), which centers on generating intricate textual content distributed across diverse regions within visual images. In CVTG, image generation models often rendering distorted and blurred visual text or missing some visual text. To tackle these challenges, we propose TextCrafter, a novel multi-visual text rendering method. TextCrafter employs a progressive strategy to decompose complex visual text into distinct components while ensuring robust alignment between textual content and its visual carrier. Additionally, it incorporates a token focus enhancement mechanism to amplify the prominence of visual text during the generation process. TextCrafter effectively addresses key challenges in CVTG tasks, such as text confusion, omissions, and blurriness. Moreover, we present a new benchmark dataset, CVTG-2K, tailored to rigorously evaluate the performance of generative models on CVTG tasks. Extensive experiments demonstrate that our method surpasses state-of-the-art approaches.
Region-Aware Text-to-Image Generation via Hard Binding and Soft Refinement
Nov 15, 2024



Regional prompting, or compositional generation, which enables fine-grained spatial control, has gained increasing attention for its practicality in real-world applications. However, previous methods either introduce additional trainable modules, thus only applicable to specific models, or manipulate on score maps within cross-attention layers using attention masks, resulting in limited control strength when the number of regions increases. To handle these limitations, we present RAG, a Regional-Aware text-to-image Generation method conditioned on regional descriptions for precise layout composition. RAG decouple the multi-region generation into two sub-tasks, the construction of individual region (Regional Hard Binding) that ensures the regional prompt is properly executed, and the overall detail refinement (Regional Soft Refinement) over regions that dismiss the visual boundaries and enhance adjacent interactions. Furthermore, RAG novelly makes repainting feasible, where users can modify specific unsatisfied regions in the last generation while keeping all other regions unchanged, without relying on additional inpainting models. Our approach is tuning-free and applicable to other frameworks as an enhancement to the prompt following property. Quantitative and qualitative experiments demonstrate that RAG achieves superior performance over attribute binding and object relationship than previous tuning-free methods.
Adaptive Guidance Learning for Camouflaged Object Detection
May 07, 2024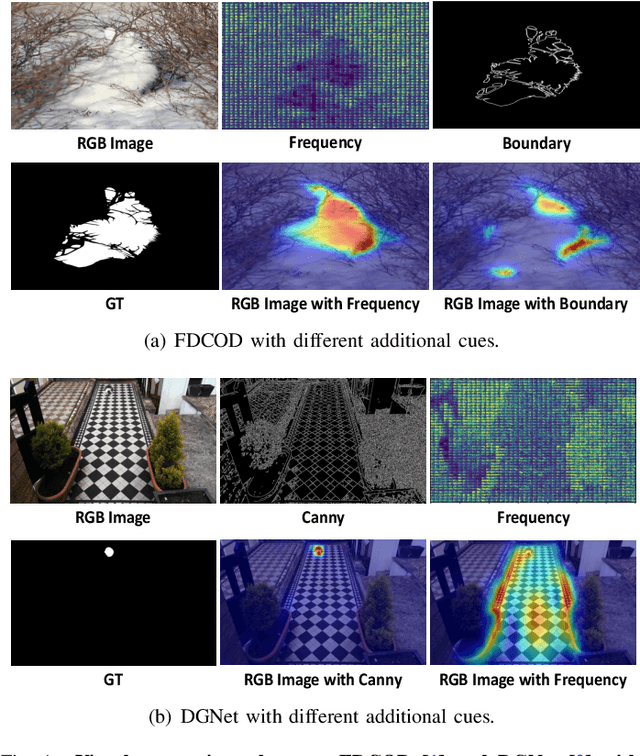

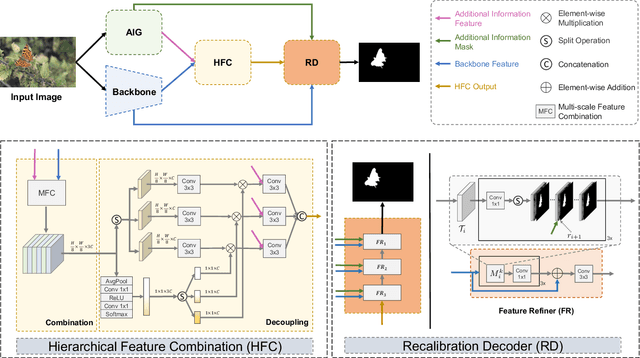
Camouflaged object detection (COD) aims to segment objects visually embedded in their surroundings, which is a very challenging task due to the high similarity between the objects and the background. To address it, most methods often incorporate additional information (e.g., boundary, texture, and frequency clues) to guide feature learning for better detecting camouflaged objects from the background. Although progress has been made, these methods are basically individually tailored to specific auxiliary cues, thus lacking adaptability and not consistently achieving high segmentation performance. To this end, this paper proposes an adaptive guidance learning network, dubbed \textit{AGLNet}, which is a unified end-to-end learnable model for exploring and adapting different additional cues in CNN models to guide accurate camouflaged feature learning. Specifically, we first design a straightforward additional information generation (AIG) module to learn additional camouflaged object cues, which can be adapted for the exploration of effective camouflaged features. Then we present a hierarchical feature combination (HFC) module to deeply integrate additional cues and image features to guide camouflaged feature learning in a multi-level fusion manner.Followed by a recalibration decoder (RD), different features are further aggregated and refined for accurate object prediction. Extensive experiments on three widely used COD benchmark datasets demonstrate that the proposed method achieves significant performance improvements under different additional cues, and outperforms the recent 20 state-of-the-art methods by a large margin. Our code will be made publicly available at: \textcolor{blue}{{https://github.com/ZNan-Chen/AGLNet}}.
Diffusion Model for Camouflaged Object Detection
Aug 05, 2023



Camouflaged object detection is a challenging task that aims to identify objects that are highly similar to their background. Due to the powerful noise-to-image denoising capability of denoising diffusion models, in this paper, we propose a diffusion-based framework for camouflaged object detection, termed diffCOD, a new framework that considers the camouflaged object segmentation task as a denoising diffusion process from noisy masks to object masks. Specifically, the object mask diffuses from the ground-truth masks to a random distribution, and the designed model learns to reverse this noising process. To strengthen the denoising learning, the input image prior is encoded and integrated into the denoising diffusion model to guide the diffusion process. Furthermore, we design an injection attention module (IAM) to interact conditional semantic features extracted from the image with the diffusion noise embedding via the cross-attention mechanism to enhance denoising learning. Extensive experiments on four widely used COD benchmark datasets demonstrate that the proposed method achieves favorable performance compared to the existing 11 state-of-the-art methods, especially in the detailed texture segmentation of camouflaged objects. Our code will be made publicly available at: https://github.com/ZNan-Chen/diffCOD.