 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Query-based Paradigm for Camouflaged Instance Segmentation
Aug 29, 2023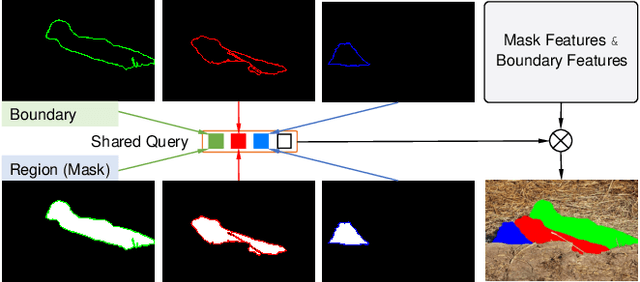
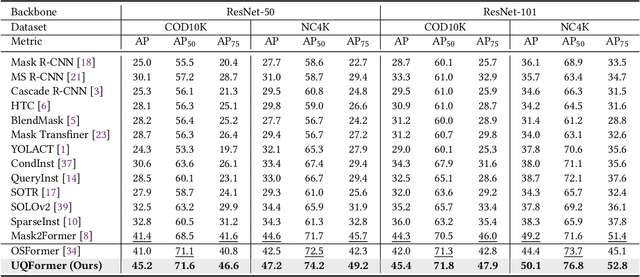
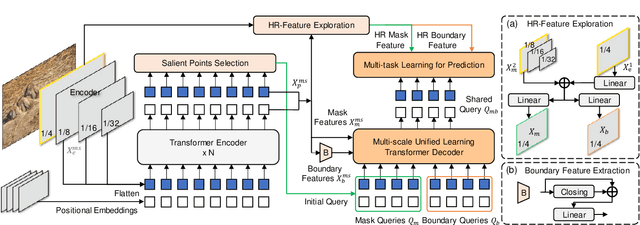

Due to the high similarity between camouflaged instances and the background, the recently proposed camouflaged instance segmentation (CIS) faces challenges in accurate localization and instance segmentation. To this end, inspired by query-based transformers, we propose a unified query-based multi-task learning framework for camouflaged instance segmentation, termed UQFormer, which builds a set of mask queries and a set of boundary queries to learn a shared composed query representation and efficiently integrates global camouflaged object region and boundary cues, for simultaneous instance segmentation and instance boundary detection in camouflaged scenarios. Specifically, we design a composed query learning paradigm that learns a shared representation to capture object region and boundary features by the cross-attention interaction of mask queries and boundary queries in the designed multi-scale unified learning transformer decoder. Then, we present a transformer-based multi-task learning framework for simultaneous camouflaged instance segmentation and camouflaged instance boundary detection based on the learned composed query representation, which also forces the model to learn a strong instance-level query representation. Notably, our model views the instance segmentation as a query-based direct set prediction problem, without other post-processing such as non-maximal suppression. Compared with 14 state-of-the-art approaches, our UQFormer significantly improves the performance of camouflaged instance segmentation. Our code will be available at https://github.com/dongbo811/UQFormer.
Diffusion Model for Camouflaged Object Detection
Aug 05, 2023



Camouflaged object detection is a challenging task that aims to identify objects that are highly similar to their background. Due to the powerful noise-to-image denoising capability of denoising diffusion models, in this paper, we propose a diffusion-based framework for camouflaged object detection, termed diffCOD, a new framework that considers the camouflaged object segmentation task as a denoising diffusion process from noisy masks to object masks. Specifically, the object mask diffuses from the ground-truth masks to a random distribution, and the designed model learns to reverse this noising process. To strengthen the denoising learning, the input image prior is encoded and integrated into the denoising diffusion model to guide the diffusion process. Furthermore, we design an injection attention module (IAM) to interact conditional semantic features extracted from the image with the diffusion noise embedding via the cross-attention mechanism to enhance denoising learning. Extensive experiments on four widely used COD benchmark datasets demonstrate that the proposed method achieves favorable performance compared to the existing 11 state-of-the-art methods, especially in the detailed texture segmentation of camouflaged objects. Our code will be made publicly available at: https://github.com/ZNan-Chen/diffCOD.
Joint Depth and Normal Estimation from Real-world Time-of-flight Raw Data
Aug 08, 2021



We present a novel approach to joint depth and normal estimation for time-of-flight (ToF) sensors. Our model learns to predict the high-quality depth and normal maps jointly from ToF raw sensor data. To achieve this, we meticulously constructed the first large-scale dataset (named ToF-100) with paired raw ToF data and ground-truth high-resolution depth maps provided by an industrial depth camera. In addition, we also design a simple but effective framework for joint depth and normal estimation, applying a robust Chamfer loss via jittering to improve the performance of our model. Our experiments demonstrate that our proposed method can efficiently reconstruct high-resolution depth and normal maps and significantly outperforms state-of-the-art approaches. Our code and data will be available at \url{https://github.com/hkustVisionRr/JointlyDepthNormalEstimation}
Future Video Synthesis with Object Motion Prediction
Apr 15, 2020
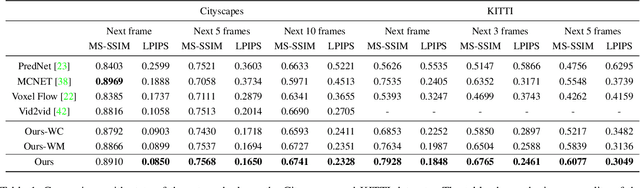
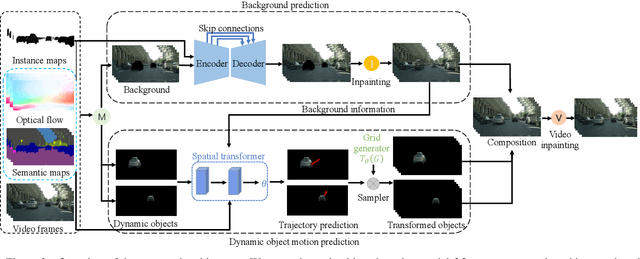
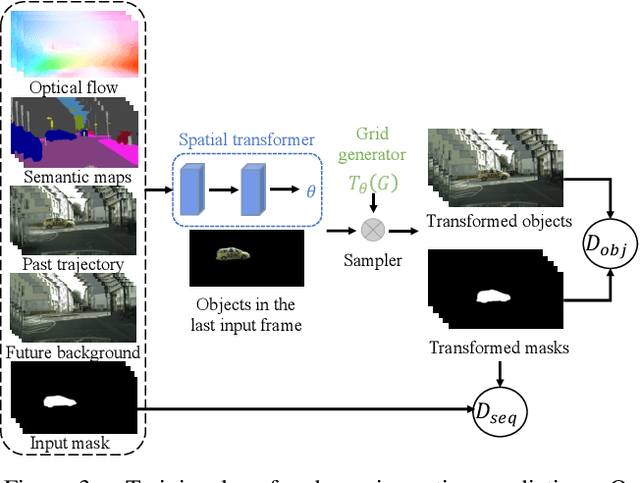
We present an approach to predict future video frames given a sequence of continuous video frames in the past. Instead of synthesizing images directly, our approach is designed to understand the complex scene dynamics by decoupling the background scene and moving objects. The appearance of the scene components in the future is predicted by non-rigid deformation of the background and affine transformation of moving objects. The anticipated appearances are combined to create a reasonable video in the future. With this procedure, our method exhibits much less tearing or distortion artifact compared to other approaches. Experimental results on the Cityscapes and KITTI datasets show that our model outperforms the state-of-the-art in terms of visual quality and accuracy.