 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreoperative-to-intraoperative Liver Registration for Laparoscopic Surgery via Latent-Grounded Correspondence Constraints
Mar 02, 2026In laparoscopic liver surgery, augmented reality technology enhances intraoperative anatomical guidance by overlaying 3D liver models from preoperative CT/MRI onto laparoscopic 2D views. However, existing registration methods lack explicit modeling of reliable 2D-3D geometric correspondences supported by latent evidence, leading to limited interpretability and potentially unstable alignment in clinical scenarios. In this work, we introduce Land-Reg, a correspondence-driven deformable registration framework that explicitly learns latent-grounded 2D-3D landmark correspondences as an interpretable intermediate representation to bridge cross-modal alignment. For rigid registration, Land-Reg embraces a Cross-modal Latent Alignment module to map multi-modal features into a unified latent space. Further, an Uncertainty-enhanced Overlap Landmark Detector with similarity matching is proposed to robustly estimate explicit 2D-3D landmark correspondences. For non-rigid registration, we design a novel shape-constrained supervision strategy that anchors shape deformation to matched landmarks through reprojection consistency and incorporates local-isometric regularization to alleviate inherent 2D-3D depth ambiguity, while a rendered-mask alignment enforces global shape consistency. Experimental results on the P2ILF dataset demonstrate the superiority of our method on both rigid pose estimation and non-rigid deformation. Our code will be available at https://github.com/cuiruize/Land-Reg.
MEJO: MLLM-Engaged Surgical Triplet Recognition via Inter- and Intra-Task Joint Optimization
Sep 16, 2025Surgical triplet recognition, which involves identifying instrument, verb, target, and their combinations, is a complex surgical scene understanding challenge plagued by long-tailed data distribution. The mainstream multi-task learning paradigm benefiting from cross-task collaborative promotion has shown promising performance in identifying triples, but two key challenges remain: 1) inter-task optimization conflicts caused by entangling task-generic and task-specific representations; 2) intra-task optimization conflicts due to class-imbalanced training data. To overcome these difficulties, we propose the MLLM-Engaged Joint Optimization (MEJO) framework that empowers both inter- and intra-task optimization for surgical triplet recognition. For inter-task optimization, we introduce the Shared-Specific-Disentangled (S$^2$D) learning scheme that decomposes representations into task-shared and task-specific components. To enhance task-shared representations, we construct a Multimodal Large Language Model (MLLM) powered probabilistic prompt pool to dynamically augment visual features with expert-level semantic cues. Additionally, comprehensive task-specific cues are modeled via distinct task prompts covering the temporal-spatial dimensions, effectively mitigating inter-task ambiguities. To tackle intra-task optimization conflicts, we develop a Coordinated Gradient Learning (CGL) strategy, which dissects and rebalances the positive-negative gradients originating from head and tail classes for more coordinated learning behaviors. Extensive experiments on the CholecT45 and CholecT50 datasets demonstrate the superiority of our proposed framework, validating its effectiveness in handling optimization conflicts.
Toward Reliable AR-Guided Surgical Navigation: Interactive Deformation Modeling with Data-Driven Biomechanics and Prompts
Jun 11, 2025In augmented reality (AR)-guided surgical navigation, preoperative organ models are superimposed onto the patient's intraoperative anatomy to visualize critical structures such as vessels and tumors. Accurate deformation modeling is essential to maintain the reliability of AR overlays by ensuring alignment between preoperative models and the dynamically changing anatomy. Although the finite element method (FEM) offers physically plausible modeling, its high computational cost limits intraoperative applicability. Moreover, existing algorithms often fail to handle large anatomical changes, such as those induced by pneumoperitoneum or ligament dissection, leading to inaccurate anatomical correspondences and compromised AR guidance. To address these challenges, we propose a data-driven biomechanics algorithm that preserves FEM-level accuracy while improving computational efficiency. In addition, we introduce a novel human-in-the-loop mechanism into the deformation modeling process. This enables surgeons to interactively provide prompts to correct anatomical misalignments, thereby incorporating clinical expertise and allowing the model to adapt dynamically to complex surgical scenarios. Experiments on a publicly available dataset demonstrate that our algorithm achieves a mean target registration error of 3.42 mm. Incorporating surgeon prompts through the interactive framework further reduces the error to 2.78 mm, surpassing state-of-the-art methods in volumetric accuracy. These results highlight the ability of our framework to deliver efficient and accurate deformation modeling while enhancing surgeon-algorithm collaboration, paving the way for safer and more reliable computer-assisted surgeries.
Benchmarking Laparoscopic Surgical Image Restoration and Beyond
May 25, 2025In laparoscopic surgery, a clear and high-quality visual field is critical for surgeons to make accurate intraoperative decisions. However, persistent visual degradation, including smoke generated by energy devices, lens fogging from thermal gradients, and lens contamination due to blood or tissue fluid splashes during surgical procedures, severely impair visual clarity. These degenerations can seriously hinder surgical workflow and pose risks to patient safety. To systematically investigate and address various forms of surgical scene degradation, we introduce a real-world open-source surgical image restoration dataset covering laparoscopic environments, called SurgClean, which involves multi-type image restoration tasks, e.g., desmoking, defogging, and desplashing. SurgClean comprises 1,020 images with diverse degradation types and corresponding paired reference labels. Based on SurgClean, we establish a standardized evaluation benchmark and provide performance for 22 representative generic task-specific image restoration approaches, including 12 generic and 10 task-specific image restoration approaches. Experimental results reveal substantial performance gaps relative to clinical requirements, highlighting a critical opportunity for algorithm advancements in intelligent surgical restoration. Furthermore, we explore the degradation discrepancies between surgical and natural scenes from structural perception and semantic understanding perspectives, providing fundamental insights for domain-specific image restoration research. Our work aims to empower the capabilities of restoration algorithms to increase surgical environments and improve the efficiency of clinical procedures.
U2-BENCH: Benchmarking Large Vision-Language Models on Ultrasound Understanding
May 23, 2025Ultrasound is a widely-used imaging modality critical to global healthcare, yet its interpretation remains challenging due to its varying image quality on operators, noises, and anatomical structures. Although large vision-language models (LVLMs) have demonstrated impressive multimodal capabilities across natural and medical domains, their performance on ultrasound remains largely unexplored. We introduce U2-BENCH, the first comprehensive benchmark to evaluate LVLMs on ultrasound understanding across classification, detection, regression, and text generation tasks. U2-BENCH aggregates 7,241 cases spanning 15 anatomical regions and defines 8 clinically inspired tasks, such as diagnosis, view recognition, lesion localization, clinical value estimation, and report generation, across 50 ultrasound application scenarios. We evaluate 20 state-of-the-art LVLMs, both open- and closed-source, general-purpose and medical-specific. Our results reveal strong performance on image-level classification, but persistent challenges in spatial reasoning and clinical language generation. U2-BENCH establishes a rigorous and unified testbed to assess and accelerate LVLM research in the uniquely multimodal domain of medical ultrasound imaging.
Landmark-Free Preoperative-to-Intraoperative Registration in Laparoscopic Liver Resection
Apr 21, 2025Liver registration by overlaying preoperative 3D models onto intraoperative 2D frames can assist surgeons in perceiving the spatial anatomy of the liver clearly for a higher surgical success rate. Existing registration methods rely heavily on anatomical landmark-based workflows, which encounter two major limitations: 1) ambiguous landmark definitions fail to provide efficient markers for registration; 2) insufficient integration of intraoperative liver visual information in shape deformation modeling. To address these challenges, in this paper, we propose a landmark-free preoperative-to-intraoperative registration framework utilizing effective self-supervised learning, termed \ourmodel. This framework transforms the conventional 3D-2D workflow into a 3D-3D registration pipeline, which is then decoupled into rigid and non-rigid registration subtasks. \ourmodel~first introduces a feature-disentangled transformer to learn robust correspondences for recovering rigid transformations. Further, a structure-regularized deformation network is designed to adjust the preoperative model to align with the intraoperative liver surface. This network captures structural correlations through geometry similarity modeling in a low-rank transformer network. To facilitate the validation of the registration performance, we also construct an in-vivo registration dataset containing liver resection videos of 21 patients, called \emph{P2I-LReg}, which contains 346 keyframes that provide a global view of the liver together with liver mask annotations and calibrated camera intrinsic parameters. Extensive experiments and user studies on both synthetic and in-vivo datasets demonstrate the superiority and potential clinical applicability of our method.
Synergistic Bleeding Region and Point Detection in Surgical Videos
Mar 28, 2025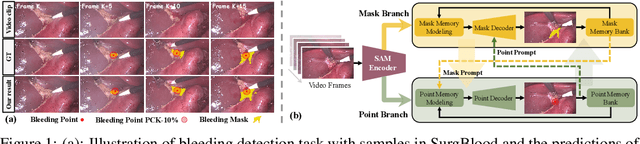
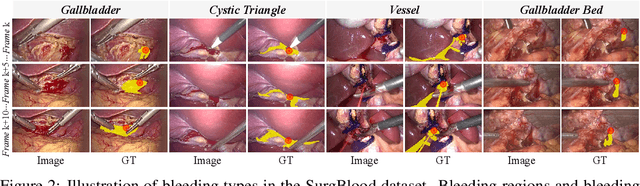
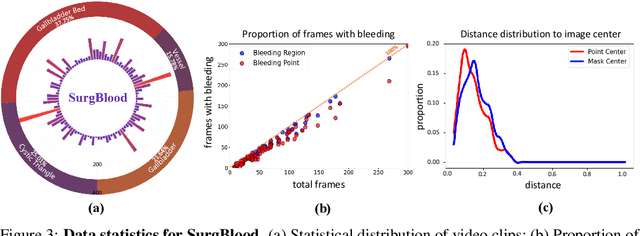
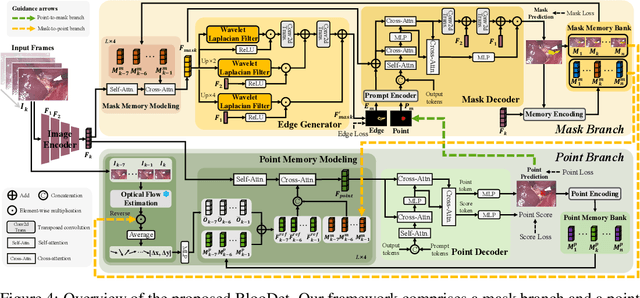
Intraoperative bleeding in laparoscopic surgery causes rapid obscuration of the operative field to hinder the surgical process. Intelligent detection of bleeding regions can quantify the blood loss to assist decision-making, while locating the bleeding point helps surgeons quickly identify the source of bleeding and achieve hemostasis in time. In this study, we first construct a real-world surgical bleeding detection dataset, named SurgBlood, comprising 5,330 frames from 95 surgical video clips with bleeding region and point annotations. Accordingly, we develop a dual-task synergistic online detector called BlooDet, designed to perform simultaneous detection of bleeding regions and points in surgical videos. Our framework embraces a dual-branch bidirectional guidance design based on Segment Anything Model 2 (SAM 2). The mask branch detects bleeding regions through adaptive edge and point prompt embeddings, while the point branch leverages mask memory to induce bleeding point memory modeling and captures the direction of bleed point movement through inter-frame optical flow. By interactive guidance and prompts, the two branches explore potential spatial-temporal relationships while leveraging memory modeling from previous frames to infer the current bleeding condition. Extensive experiments demonstrate that our approach outperforms other counterparts on SurgBlood in both bleeding region and point detection tasks, e.g., achieving 64.88% IoU for bleeding region detection and 83.69% PCK-10% for bleeding point detection.
Unconstrained Salient and Camouflaged Object Detection
Dec 14, 2024



Visual Salient Object Detection (SOD) and Camouflaged Object Detection (COD) are two interrelated yet distinct tasks. Both tasks model the human visual system's ability to perceive the presence of objects. The traditional SOD datasets and methods are designed for scenes where only salient objects are present, similarly, COD datasets and methods are designed for scenes where only camouflaged objects are present. However, scenes where both salient and camouflaged objects coexist, or where neither is present, are not considered. This simplifies the existing research on SOD and COD. In this paper, to explore a more generalized approach to SOD and COD, we introduce a benchmark called Unconstrained Salient and Camouflaged Object Detection (USCOD), which supports the simultaneous detection of salient and camouflaged objects in unconstrained scenes, regardless of their presence. Towards this, we construct a large-scale dataset, CS12K, that encompasses a variety of scenes, including four distinct types: only salient objects, only camouflaged objects, both, and neither. In our benchmark experiments, we identify a major challenge in USCOD: distinguishing between salient and camouflaged objects within the same scene. To address this challenge, we propose USCNet, a baseline model for USCOD that decouples the learning of attribute distinction from mask reconstruction. The model incorporates an APG module, which learns both sample-generic and sample-specific features to enhance the attribute differentiation between salient and camouflaged objects. Furthermore, to evaluate models' ability to distinguish between salient and camouflaged objects, we design a metric called Camouflage-Saliency Confusion Score (CSCS). The proposed method achieves state-of-the-art performance on the newly introduced USCOD task. The code and dataset will be publicly available.
Evaluation Study on SAM 2 for Class-agnostic Instance-level Segmentation
Sep 04, 2024



Segment Anything Model (SAM) has demonstrated powerful zero-shot segmentation performance in natural scenes. The recently released Segment Anything Model 2 (SAM2) has further heightened researchers' expectations towards image segmentation capabilities. To evaluate the performance of SAM2 on class-agnostic instance-level segmentation tasks, we adopt different prompt strategies for SAM2 to cope with instance-level tasks for three relevant scenarios: Salient Instance Segmentation (SIS), Camouflaged Instance Segmentation (CIS), and Shadow Instance Detection (SID). In addition, to further explore the effectiveness of SAM2 in segmenting granular object structures, we also conduct detailed tests on the high-resolution Dichotomous Image Segmentation (DIS) benchmark to assess the fine-grained segmentation capability. Qualitative and quantitative experimental results indicate that the performance of SAM2 varies significantly across different scenarios. Besides, SAM2 is not particularly sensitive to segmenting high-resolution fine details. We hope this technique report can drive the emergence of SAM2-based adapters, aiming to enhance the performance ceiling of large vision models on class-agnostic instance segmentation tasks.
Surgical Workflow Recognition and Blocking Effectiveness Detection in Laparoscopic Liver Resections with Pringle Maneuver
Aug 21, 2024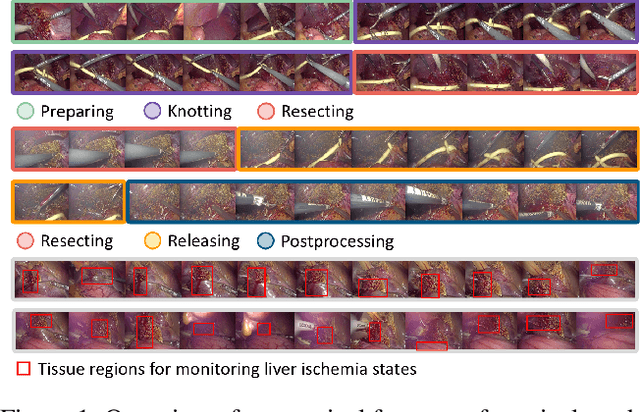



Pringle maneuver (PM) in laparoscopic liver resection aims to reduce blood loss and provide a clear surgical view by intermittently blocking blood inflow of the liver, whereas prolonged PM may cause ischemic injury. To comprehensively monitor this surgical procedure and provide timely warnings of ineffective and prolonged blocking, we suggest two complementary AI-assisted surgical monitoring tasks: workflow recognition and blocking effectiveness detection in liver resections. The former presents challenges in real-time capturing of short-term PM, while the latter involves the intraoperative discrimination of long-term liver ischemia states. To address these challenges, we meticulously collect a novel dataset, called PmLR50, consisting of 25,037 video frames covering various surgical phases from 50 laparoscopic liver resection procedures. Additionally, we develop an online baseline for PmLR50, termed PmNet. This model embraces Masked Temporal Encoding (MTE) and Compressed Sequence Modeling (CSM) for efficient short-term and long-term temporal information modeling, and embeds Contrastive Prototype Separation (CPS) to enhance action discrimination between similar intraoperative operations. Experimental results demonstrate that PmNet outperforms existing state-of-the-art surgical workflow recognition methods on the PmLR50 benchmark. Our research offers potential clinical applications for the laparoscopic liver surgery community. Source code and data will be publicly available.