 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolution-Inspired Sample Competition for Deep Neural Network Optimization
Apr 14, 2026Conventional deep network training generally optimizes all samples under a largely uniform learning paradigm, without explicitly modeling the heterogeneous competition among them. Such an oversimplified treatment can lead to several well-known issues, including bias under class imbalance, insufficient learning of hard samples, and the erroneous reinforcement of noisy samples. In this work, we present \textit{Natural Selection} (NS), a novel evolution-inspired optimization method that explicitly incorporates competitive interactions into deep network training. Unlike conventional sample reweighting strategies that rely mainly on predefined heuristics or static criteria, NS estimates the competitive status of each sample in a group-wise context and uses it to adaptively regulate its training contribution. Specifically, NS first assembles multiple samples into a composite image and rescales it to the original input size for model inference. Based on the resulting predictions, a natural selection score is computed for each sample to characterize its relative competitive variation within the constructed group. These scores are then used to dynamically reweight the sample-wise loss, thereby introducing an explicit competition-driven mechanism into the optimization process. In this way, NS provides a simple yet effective means of moving beyond uniform sample treatment and enables more adaptive and balanced model optimization. Extensive experiments on 12 public datasets across four image classification tasks demonstrate the effectiveness of the proposed method. Moreover, NS is compatible with diverse network architectures and does not depend on task-specific assumptions, indicating its strong generality and practical potential. The code will be made publicly available.
MetaTune: Adjoint-based Meta-tuning via Robotic Differentiable Dynamics
Mar 28, 2026Disturbance observer-based control has shown promise in robustifying robotic systems against uncertainties. However, tuning such systems remains challenging due to the strong coupling between controller gains and observer parameters. In this work, we propose MetaTune, a unified framework for joint auto-tuning of feedback controllers and disturbance observers through differentiable closed-loop meta-learning. MetaTune integrates a portable neural policy with physics-informed gradients derived from differentiable system dynamics, enabling adaptive gain across tasks and operating conditions. We develop an adjoint method that efficiently computes the meta-gradients with respect to adaptive gains backward in time to directly minimize the cost-to-go. Compared to existing forward methods, our approach reduces the computational complexity to be linear in the data horizon. Experimental results on quadrotor control show that MetaTune achieves consistent improvements over state-of-the-art differentiable tuning methods while reducing gradient computation time by more than 50 percent. In high-fidelity PX4-Gazebo hardware-in-the-loop simulation, the learned adaptive policy yields 15-20 percent average tracking error reduction at aggressive flight speeds and up to 40 percent improvement under strong disturbances, while demonstrating zero-shot sim-to-sim transfer without fine-tuning.
Fair Data Pre-Processing with Imperfect Attribute Space
Mar 27, 2026Fair data pre-processing is a widely used strategy for mitigating bias in machine learning. A promising line of research focuses on calibrating datasets to satisfy a designed fairness policy so that sensitive attributes influence outcomes only through clearly specified legitimate causal pathways. While effective on clean and information-rich data, these methods often break down in real-world scenarios with imperfect attribute spaces, where decision-relevant factors may be deemed unusable or even missing. To address this gap, we propose LatentPre, a novel framework that enables principled and robust fair data processing in practical settings. Instead of relying solely on observed attributes, LatentPre augments the fairness policy with latent attributes that capture essential but subtle signals, enabling the framework to operate as if the attribute space were perfect. These latent attributes are strategically introduced to guarantee identifiability and are estimated using a tailored expectation-maximization paradigm. The raw data is then carefully refined to conform to this latent-augmented policy, effectively removing biased patterns while preserving justifiable ones. Extensive experiments demonstrate that LatentPre consistently achieves strong fairness-utility trade-offs across diverse scenarios, advancing practical fairness-aware data management.
ProCal: Probability Calibration for Neighborhood-Guided Source-Free Domain Adaptation
Mar 19, 2026Source-Free Domain Adaptation (SFDA) adapts pre-trained models to unlabeled target domains without requiring access to source data. Although state-of-the-art methods leveraging local neighborhood structures show promise for SFDA, they tend to over-rely on prediction similarity among neighbors. This over-reliance accelerates the forgetting of source knowledge and increases susceptibility to local noise overfitting. To address these issues, we introduce ProCal, a probability calibration method that dynamically calibrates neighborhood-based predictions through a dual-model collaborative prediction mechanism. ProCal integrates the source model's initial predictions with the current model's online outputs to effectively calibrate neighbor probabilities. This strategy not only mitigates the interference of local noise but also preserves the discriminative information from the source model, thereby achieving a balance between knowledge retention and domain adaptation. Furthermore, we design a joint optimization objective that combines a soft supervision loss with a diversity loss to guide the target model. Our theoretical analysis shows that ProCal converges to an equilibrium where source knowledge and target information are effectively fused, reducing both knowledge forgetting and overfitting. We validate the effectiveness of our approach through extensive experiments on 31 cross-domain tasks across four public datasets. Our code is available at: https://github.com/zhengyinghit/ProCal.
CausalPre: Scalable and Effective Data Pre-processing for Causal Fairness
Sep 18, 2025



Causal fairness in databases is crucial to preventing biased and inaccurate outcomes in downstream tasks. While most prior work assumes a known causal model, recent efforts relax this assumption by enforcing additional constraints. However, these approaches often fail to capture broader attribute relationships that are critical to maintaining utility. This raises a fundamental question: Can we harness the benefits of causal reasoning to design efficient and effective fairness solutions without relying on strong assumptions about the underlying causal model? In this paper, we seek to answer this question by introducing CausalPre, a scalable and effective causality-guided data pre-processing framework that guarantees justifiable fairness, a strong causal notion of fairness. CausalPre extracts causally fair relationships by reformulating the originally complex and computationally infeasible extraction task into a tailored distribution estimation problem. To ensure scalability, CausalPre adopts a carefully crafted variant of low-dimensional marginal factorization to approximate the joint distribution, complemented by a heuristic algorithm that efficiently tackles the associated computational challenge. Extensive experiments on benchmark datasets demonstrate that CausalPre is both effective and scalable, challenging the conventional belief that achieving causal fairness requires trading off relationship coverage for relaxed model assumptions.
MEJO: MLLM-Engaged Surgical Triplet Recognition via Inter- and Intra-Task Joint Optimization
Sep 16, 2025Surgical triplet recognition, which involves identifying instrument, verb, target, and their combinations, is a complex surgical scene understanding challenge plagued by long-tailed data distribution. The mainstream multi-task learning paradigm benefiting from cross-task collaborative promotion has shown promising performance in identifying triples, but two key challenges remain: 1) inter-task optimization conflicts caused by entangling task-generic and task-specific representations; 2) intra-task optimization conflicts due to class-imbalanced training data. To overcome these difficulties, we propose the MLLM-Engaged Joint Optimization (MEJO) framework that empowers both inter- and intra-task optimization for surgical triplet recognition. For inter-task optimization, we introduce the Shared-Specific-Disentangled (S$^2$D) learning scheme that decomposes representations into task-shared and task-specific components. To enhance task-shared representations, we construct a Multimodal Large Language Model (MLLM) powered probabilistic prompt pool to dynamically augment visual features with expert-level semantic cues. Additionally, comprehensive task-specific cues are modeled via distinct task prompts covering the temporal-spatial dimensions, effectively mitigating inter-task ambiguities. To tackle intra-task optimization conflicts, we develop a Coordinated Gradient Learning (CGL) strategy, which dissects and rebalances the positive-negative gradients originating from head and tail classes for more coordinated learning behaviors. Extensive experiments on the CholecT45 and CholecT50 datasets demonstrate the superiority of our proposed framework, validating its effectiveness in handling optimization conflicts.
Cardiac-CLIP: A Vision-Language Foundation Model for 3D Cardiac CT Images
Jul 29, 2025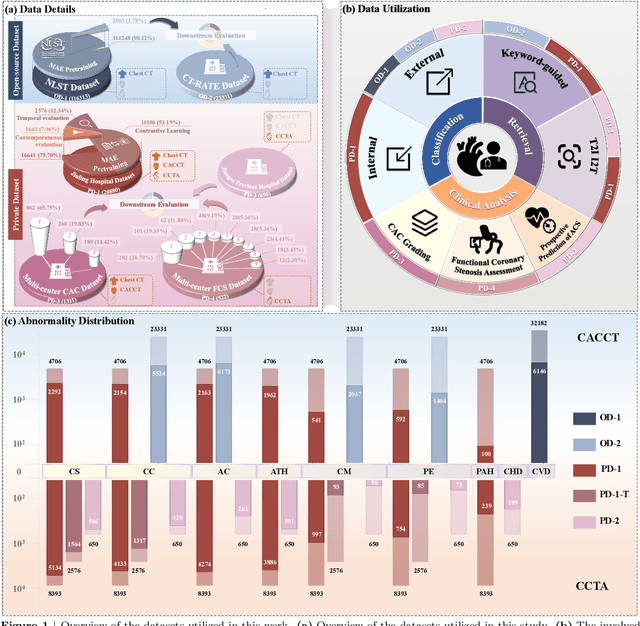
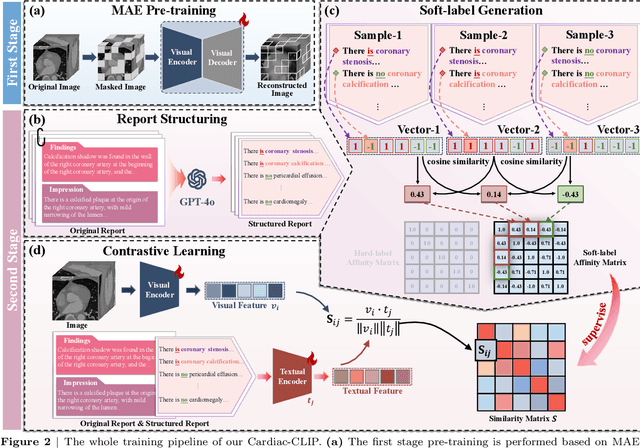
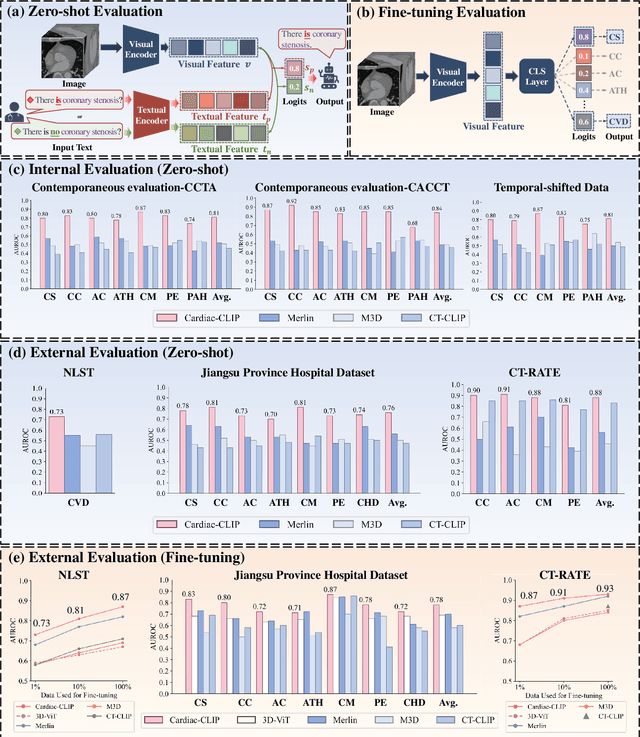
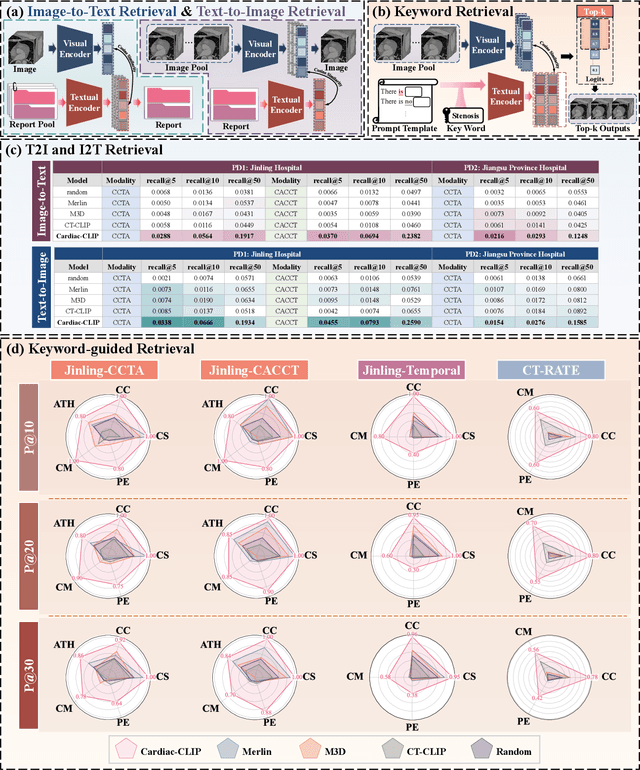
Foundation models have demonstrated remarkable potential in medical domain. However, their application to complex cardiovascular diagnostics remains underexplored. In this paper, we present Cardiac-CLIP, a multi-modal foundation model designed for 3D cardiac CT images. Cardiac-CLIP is developed through a two-stage pre-training strategy. The first stage employs a 3D masked autoencoder (MAE) to perform self-supervised representation learning from large-scale unlabeled volumetric data, enabling the visual encoder to capture rich anatomical and contextual features. In the second stage, contrastive learning is introduced to align visual and textual representations, facilitating cross-modal understanding. To support the pre-training, we collect 16641 real clinical CT scans, supplemented by 114k publicly available data. Meanwhile, we standardize free-text radiology reports into unified templates and construct the pathology vectors according to diagnostic attributes, based on which the soft-label matrix is generated to supervise the contrastive learning process. On the other hand, to comprehensively evaluate the effectiveness of Cardiac-CLIP, we collect 6,722 real-clinical data from 12 independent institutions, along with the open-source data to construct the evaluation dataset. Specifically, Cardiac-CLIP is comprehensively evaluated across multiple tasks, including cardiovascular abnormality classification, information retrieval and clinical analysis. Experimental results demonstrate that Cardiac-CLIP achieves state-of-the-art performance across various downstream tasks in both internal and external data. Particularly, Cardiac-CLIP exhibits great effectiveness in supporting complex clinical tasks such as the prospective prediction of acute coronary syndrome, which is notoriously difficult in real-world scenarios.
Fuzzy-aware Loss for Source-free Domain Adaptation in Visual Emotion Recognition
Jan 26, 2025

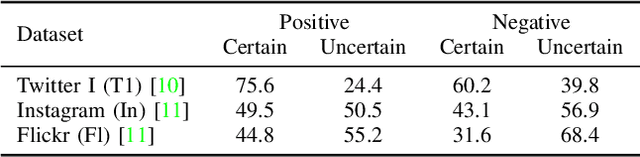

Source-free domain adaptation in visual emotion recognition (SFDA-VER) is a highly challenging task that requires adapting VER models to the target domain without relying on source data, which is of great significance for data privacy protection. However, due to the unignorable disparities between visual emotion data and traditional image classification data, existing SFDA methods perform poorly on this task. In this paper, we investigate the SFDA-VER task from a fuzzy perspective and identify two key issues: fuzzy emotion labels and fuzzy pseudo-labels. These issues arise from the inherent uncertainty of emotion annotations and the potential mispredictions in pseudo-labels. To address these issues, we propose a novel fuzzy-aware loss (FAL) to enable the VER model to better learn and adapt to new domains under fuzzy labels. Specifically, FAL modifies the standard cross entropy loss and focuses on adjusting the losses of non-predicted categories, which prevents a large number of uncertain or incorrect predictions from overwhelming the VER model during adaptation. In addition, we provide a theoretical analysis of FAL and prove its robustness in handling the noise in generated pseudo-labels. Extensive experiments on 26 domain adaptation sub-tasks across three benchmark datasets demonstrate the effectiveness of our method.
A Survey of Embodied Learning for Object-Centric Robotic Manipulation
Aug 21, 2024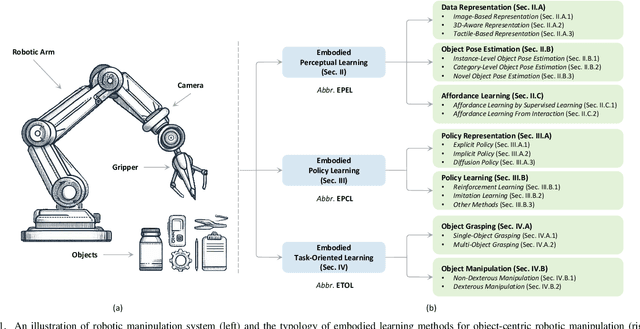
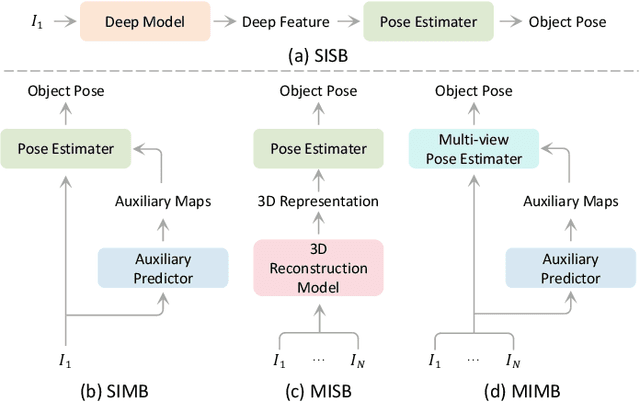
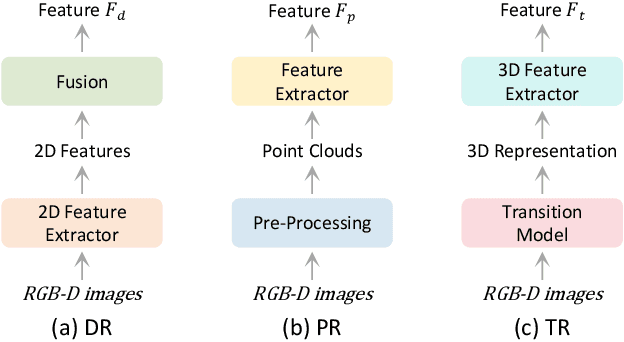
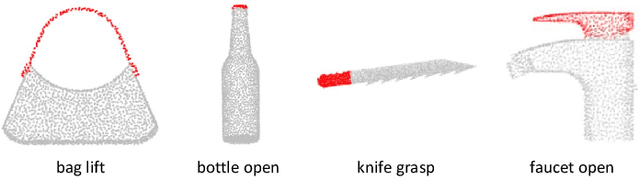
Embodied learning for object-centric robotic manipulation is a rapidly developing and challenging area in embodied AI. It is crucial for advancing next-generation intelligent robots and has garnered significant interest recently. Unlike data-driven machine learning methods, embodied learning focuses on robot learning through physical interaction with the environment and perceptual feedback, making it especially suitable for robotic manipulation. In this paper, we provide a comprehensive survey of the latest advancements in this field and categorize the existing work into three main branches: 1) Embodied perceptual learning, which aims to predict object pose and affordance through various data representations; 2) Embodied policy learning, which focuses on generating optimal robotic decisions using methods such as reinforcement learning and imitation learning; 3) Embodied task-oriented learning, designed to optimize the robot's performance based on the characteristics of different tasks in object grasping and manipulation. In addition, we offer an overview and discussion of public datasets, evaluation metrics, representative applications, current challenges, and potential future research directions. A project associated with this survey has been established at https://github.com/RayYoh/OCRM_survey.
Leaf Cultivar Identification via Prototype-enhanced Learning
May 05, 2023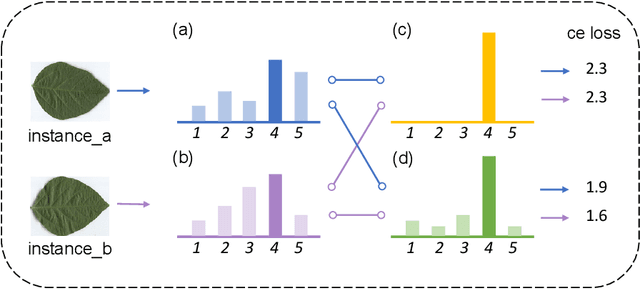
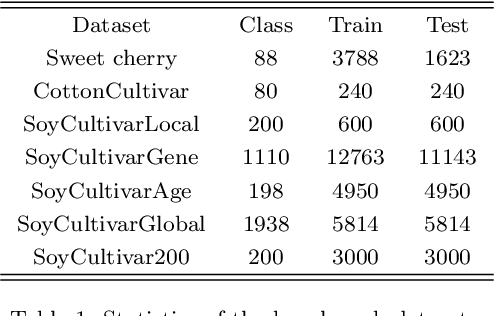
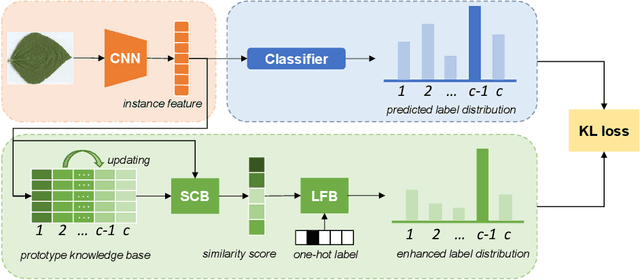
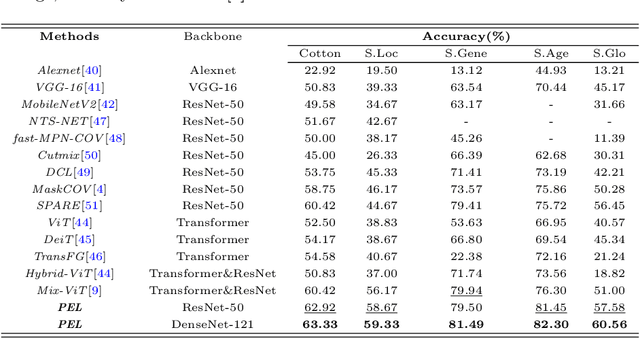
Plant leaf identification is crucial for biodiversity protection and conservation and has gradually attracted the attention of academia in recent years. Due to the high similarity among different varieties, leaf cultivar recognition is also considered to be an ultra-fine-grained visual classification (UFGVC) task, which is facing a huge challenge. In practice, an instance may be related to multiple varieties to varying degrees, especially in the UFGVC datasets. However, deep learning methods trained on one-hot labels fail to reflect patterns shared across categories and thus perform poorly on this task. To address this issue, we generate soft targets integrated with inter-class similarity information. Specifically, we continuously update the prototypical features for each category and then capture the similarity scores between instances and prototypes accordingly. Original one-hot labels and the similarity scores are incorporated to yield enhanced labels. Prototype-enhanced soft labels not only contain original one-hot label information, but also introduce rich inter-category semantic association information, thus providing more effective supervision for deep model training. Extensive experimental results on public datasets show that our method can significantly improve the performance on the UFGVC task of leaf cultivar identification.