 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Do Self-Supervised Methods Perform in Cross-Domain Few-Shot Learning?
Paper and Code
Feb 18, 2022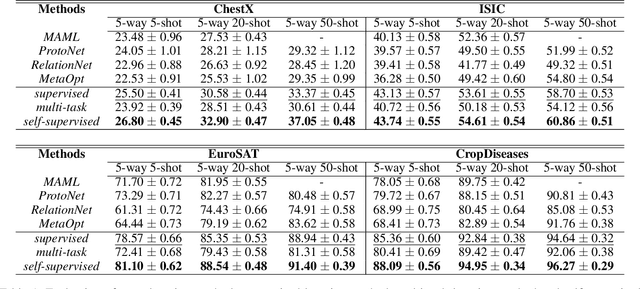
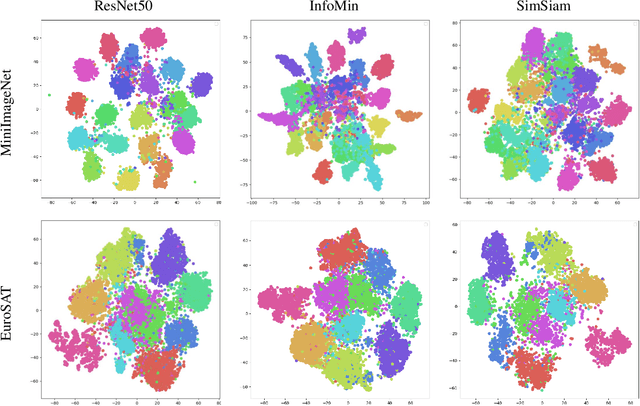
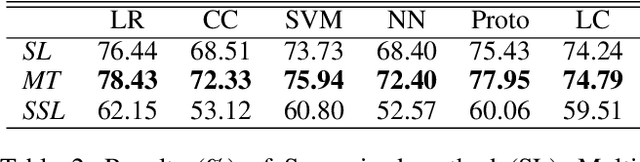
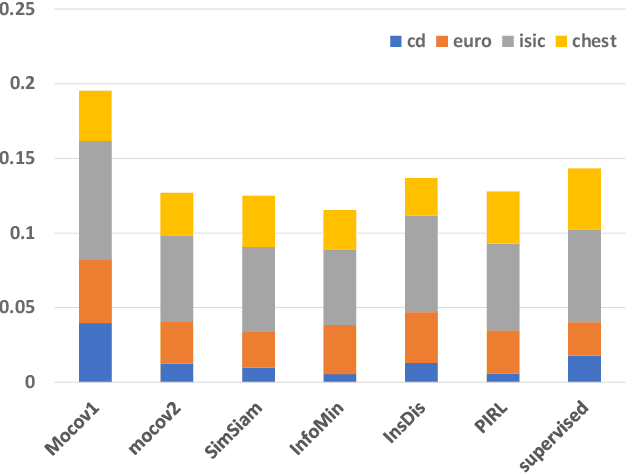
Cross-domain few-shot learning (CDFSL) remains a largely unsolved problem in the area of computer vision, while self-supervised learning presents a promising solution. Both learning methods attempt to alleviate the dependency of deep networks on the requirement of large-scale labeled data. Although self-supervised methods have recently advanced dramatically, their utility on CDFSL is relatively unexplored. In this paper, we investigate the role of self-supervised representation learning in the context of CDFSL via a thorough evaluation of existing methods. It comes as a surprise that even with shallow architectures or small training datasets, self-supervised methods can perform favorably compared to the existing SOTA methods. Nevertheless, no single self-supervised approach dominates all datasets indicating that existing self-supervised methods are not universally applicable. In addition, we find that representations extracted from self-supervised methods exhibit stronger robustness than the supervised method. Intriguingly, whether self-supervised representations perform well on the source domain has little correlation with their applicability on the target domain. As part of our study, we conduct an objective measurement of the performance for six kinds of representative classifiers. The results suggest Prototypical Classifier as the standard evaluation recipe for CDFSL.