 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOFA-VTON: More Fashion Possibilities with Fine-Grained Adaptations in Virtual Try-On
Jun 09, 2026Virtual try-on aims to fit an in-shop clothing image onto a specific human body. An optimal virtual try-on method should provide diverse and flexible dressing options, accurately reflecting the varied wearing styles encountered in real-life scenarios, tailored to individual preferences and fashion aspirations. However, current methods predominantly perform a direct replacement of the original clothing with the target clothing, following the same dressing pattern. This limited control over clothing adaptation may result in fixed and monotonous try-on outputs. To delve into More Fashion Possibilities with Fine-Grained Adaptations in Virtual Try-On, we propose a novel virtual try-on method, termed MOFA-VTON, which allows adjustment for clothing adaptations in try-on results through simple sketches by users. Specifically, we first design a mask construction strategy that transforms user-drawn curve sketches into a dual-region mask, replacing the traditional clothing-agnostic mask and providing fine-grained layout guidance for the subsequent generation process. Further, we propose layout adjustment blocks that utilize the cross-attention mechanism to independently learn layout correspondences for upper and lower regions of the human body, refining the spatial arrangement of the two regions. With these implementations, our method enables flexible and fine-grained adaptations of target clothing, overcoming the constraints of a fixed layout. Extensive experiments on VITON-HD and DressCode datasets demonstrate that our proposed MOFA-VTON outperforms previous state-of-the-art methods and provides more fashion possibilities for virtual try-on.
TapSampling: Inference-Time Sampling with a Task-Progress-Understanding Verifier for Robotic Manipulation
May 25, 2026Existing embodied control research demonstrates remarkable performance improvements by scaling training data and model size. We instead explore inference-time strategy as an alternative axis. Non-deterministic generative models, such as diffusion and autoregressive models, have been widely adopted in the field of embodied control. However, the single-shot inference paradigm limits their performance. In this paper, we propose \textbf{TapSampling}, a plug-and-play framework for inference-time sampling. First, we introduce an Action-VAE that represents actions in a low-dimensional latent space by mapping policy-generated initial actions into a compressed posterior distribution, from which any number of latent samples can be drawn and decoded into candidate actions that approximate the true action distribution. Second, we formulate action verification as task-progress outcome prediction, using the intrinsic sequential structure of robotic datasets to train a semantically grounded verifier for interpretable action selection. Furthermore, TapSampling is a policy-agnostic framework. Extensive experiments in both simulated and real-world environments demonstrate that our method substantially improves multiple generalist policies without further policy finetuning. Code and models are available at the project page.
Towards Universal Modal Tracking with Online Dense Temporal Token Learning
Jul 27, 2025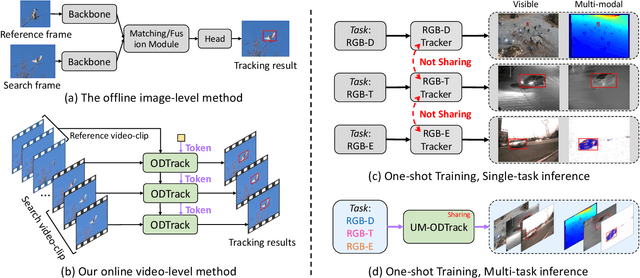


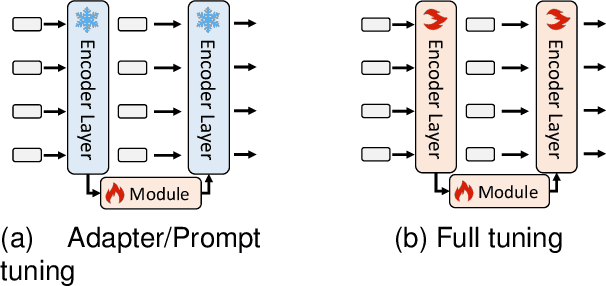
We propose a universal video-level modality-awareness tracking model with online dense temporal token learning (called {\modaltracker}). It is designed to support various tracking tasks, including RGB, RGB+Thermal, RGB+Depth, and RGB+Event, utilizing the same model architecture and parameters. Specifically, our model is designed with three core goals: \textbf{Video-level Sampling}. We expand the model's inputs to a video sequence level, aiming to see a richer video context from an near-global perspective. \textbf{Video-level Association}. Furthermore, we introduce two simple yet effective online dense temporal token association mechanisms to propagate the appearance and motion trajectory information of target via a video stream manner. \textbf{Modality Scalable}. We propose two novel gated perceivers that adaptively learn cross-modal representations via a gated attention mechanism, and subsequently compress them into the same set of model parameters via a one-shot training manner for multi-task inference. This new solution brings the following benefits: (i) The purified token sequences can serve as temporal prompts for the inference in the next video frames, whereby previous information is leveraged to guide future inference. (ii) Unlike multi-modal trackers that require independent training, our one-shot training scheme not only alleviates the training burden, but also improves model representation. Extensive experiments on visible and multi-modal benchmarks show that our {\modaltracker} achieves a new \textit{SOTA} performance. The code will be available at https://github.com/GXNU-ZhongLab/ODTrack.
Generalizable and Relightable Gaussian Splatting for Human Novel View Synthesis
May 27, 2025We propose GRGS, a generalizable and relightable 3D Gaussian framework for high-fidelity human novel view synthesis under diverse lighting conditions. Unlike existing methods that rely on per-character optimization or ignore physical constraints, GRGS adopts a feed-forward, fully supervised strategy that projects geometry, material, and illumination cues from multi-view 2D observations into 3D Gaussian representations. Specifically, to reconstruct lighting-invariant geometry, we introduce a Lighting-aware Geometry Refinement (LGR) module trained on synthetically relit data to predict accurate depth and surface normals. Based on the high-quality geometry, a Physically Grounded Neural Rendering (PGNR) module is further proposed to integrate neural prediction with physics-based shading, supporting editable relighting with shadows and indirect illumination. Besides, we design a 2D-to-3D projection training scheme that leverages differentiable supervision from ambient occlusion, direct, and indirect lighting maps, which alleviates the computational cost of explicit ray tracing. Extensive experiments demonstrate that GRGS achieves superior visual quality, geometric consistency, and generalization across characters and lighting conditions.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Limb-Aware Virtual Try-On Network with Progressive Clothing Warping
Mar 18, 2025
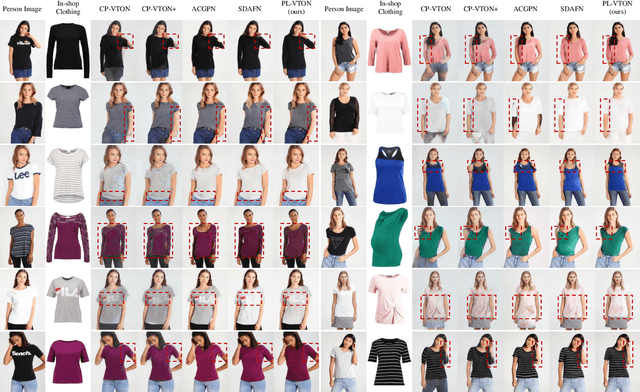


Image-based virtual try-on aims to transfer an in-shop clothing image to a person image. Most existing methods adopt a single global deformation to perform clothing warping directly, which lacks fine-grained modeling of in-shop clothing and leads to distorted clothing appearance. In addition, existing methods usually fail to generate limb details well because they are limited by the used clothing-agnostic person representation without referring to the limb textures of the person image. To address these problems, we propose Limb-aware Virtual Try-on Network named PL-VTON, which performs fine-grained clothing warping progressively and generates high-quality try-on results with realistic limb details. Specifically, we present Progressive Clothing Warping (PCW) that explicitly models the location and size of in-shop clothing and utilizes a two-stage alignment strategy to progressively align the in-shop clothing with the human body. Moreover, a novel gravity-aware loss that considers the fit of the person wearing clothing is adopted to better handle the clothing edges. Then, we design Person Parsing Estimator (PPE) with a non-limb target parsing map to semantically divide the person into various regions, which provides structural constraints on the human body and therefore alleviates texture bleeding between clothing and body regions. Finally, we introduce Limb-aware Texture Fusion (LTF) that focuses on generating realistic details in limb regions, where a coarse try-on result is first generated by fusing the warped clothing image with the person image, then limb textures are further fused with the coarse result under limb-aware guidance to refine limb details. Extensive experiments demonstrate that our PL-VTON outperforms the state-of-the-art methods both qualitatively and quantitatively.
* Accepted by IEEE Transactions on Multimedia (TMM). The code is available at https://github.com/aipixel/PL-VTONv2
Progressive Limb-Aware Virtual Try-On
Mar 16, 2025Existing image-based virtual try-on methods directly transfer specific clothing to a human image without utilizing clothing attributes to refine the transferred clothing geometry and textures, which causes incomplete and blurred clothing appearances. In addition, these methods usually mask the limb textures of the input for the clothing-agnostic person representation, which results in inaccurate predictions for human limb regions (i.e., the exposed arm skin), especially when transforming between long-sleeved and short-sleeved garments. To address these problems, we present a progressive virtual try-on framework, named PL-VTON, which performs pixel-level clothing warping based on multiple attributes of clothing and embeds explicit limb-aware features to generate photo-realistic try-on results. Specifically, we design a Multi-attribute Clothing Warping (MCW) module that adopts a two-stage alignment strategy based on multiple attributes to progressively estimate pixel-level clothing displacements. A Human Parsing Estimator (HPE) is then introduced to semantically divide the person into various regions, which provides structural constraints on the human body and therefore alleviates texture bleeding between clothing and limb regions. Finally, we propose a Limb-aware Texture Fusion (LTF) module to estimate high-quality details in limb regions by fusing textures of the clothing and the human body with the guidance of explicit limb-aware features. Extensive experiments demonstrate that our proposed method outperforms the state-of-the-art virtual try-on methods both qualitatively and quantitatively. The code is available at https://github.com/xyhanHIT/PL-VTON.
Path-Adaptive Matting for Efficient Inference Under Various Computational Cost Constraints
Mar 05, 2025



In this paper, we explore a novel image matting task aimed at achieving efficient inference under various computational cost constraints, specifically FLOP limitations, using a single matting network. Existing matting methods which have not explored scalable architectures or path-learning strategies, fail to tackle this challenge. To overcome these limitations, we introduce Path-Adaptive Matting (PAM), a framework that dynamically adjusts network paths based on image contexts and computational cost constraints. We formulate the training of the computational cost-constrained matting network as a bilevel optimization problem, jointly optimizing the matting network and the path estimator. Building on this formalization, we design a path-adaptive matting architecture by incorporating path selection layers and learnable connect layers to estimate optimal paths and perform efficient inference within a unified network. Furthermore, we propose a performance-aware path-learning strategy to generate path labels online by evaluating a few paths sampled from the prior distribution of optimal paths and network estimations, enabling robust and efficient online path learning. Experiments on five image matting datasets demonstrate that the proposed PAM framework achieves competitive performance across a range of computational cost constraints.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Tele-Aloha: A Low-budget and High-authenticity Telepresence System Using Sparse RGB Cameras
May 23, 2024
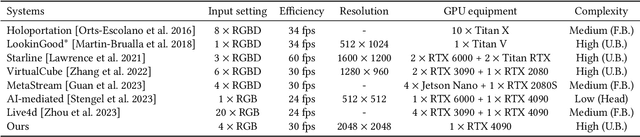

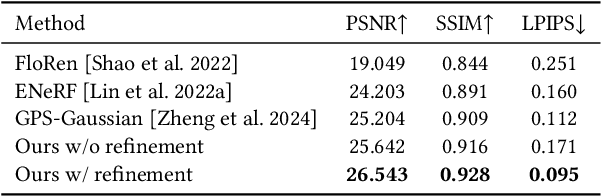
In this paper, we present a low-budget and high-authenticity bidirectional telepresence system, Tele-Aloha, targeting peer-to-peer communication scenarios. Compared to previous systems, Tele-Aloha utilizes only four sparse RGB cameras, one consumer-grade GPU, and one autostereoscopic screen to achieve high-resolution (2048x2048), real-time (30 fps), low-latency (less than 150ms) and robust distant communication. As the core of Tele-Aloha, we propose an efficient novel view synthesis algorithm for upper-body. Firstly, we design a cascaded disparity estimator for obtaining a robust geometry cue. Additionally a neural rasterizer via Gaussian Splatting is introduced to project latent features onto target view and to decode them into a reduced resolution. Further, given the high-quality captured data, we leverage weighted blending mechanism to refine the decoded image into the final resolution of 2K. Exploiting world-leading autostereoscopic display and low-latency iris tracking, users are able to experience a strong three-dimensional sense even without any wearable head-mounted display device. Altogether, our telepresence system demonstrates the sense of co-presence in real-life experiments, inspiring the next generation of communication.