 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOFA-VTON: More Fashion Possibilities with Fine-Grained Adaptations in Virtual Try-On
Jun 09, 2026Virtual try-on aims to fit an in-shop clothing image onto a specific human body. An optimal virtual try-on method should provide diverse and flexible dressing options, accurately reflecting the varied wearing styles encountered in real-life scenarios, tailored to individual preferences and fashion aspirations. However, current methods predominantly perform a direct replacement of the original clothing with the target clothing, following the same dressing pattern. This limited control over clothing adaptation may result in fixed and monotonous try-on outputs. To delve into More Fashion Possibilities with Fine-Grained Adaptations in Virtual Try-On, we propose a novel virtual try-on method, termed MOFA-VTON, which allows adjustment for clothing adaptations in try-on results through simple sketches by users. Specifically, we first design a mask construction strategy that transforms user-drawn curve sketches into a dual-region mask, replacing the traditional clothing-agnostic mask and providing fine-grained layout guidance for the subsequent generation process. Further, we propose layout adjustment blocks that utilize the cross-attention mechanism to independently learn layout correspondences for upper and lower regions of the human body, refining the spatial arrangement of the two regions. With these implementations, our method enables flexible and fine-grained adaptations of target clothing, overcoming the constraints of a fixed layout. Extensive experiments on VITON-HD and DressCode datasets demonstrate that our proposed MOFA-VTON outperforms previous state-of-the-art methods and provides more fashion possibilities for virtual try-on.
Shape-Guided Clothing Warping for Virtual Try-On
Apr 21, 2025Image-based virtual try-on aims to seamlessly fit in-shop clothing to a person image while maintaining pose consistency. Existing methods commonly employ the thin plate spline (TPS) transformation or appearance flow to deform in-shop clothing for aligning with the person's body. Despite their promising performance, these methods often lack precise control over fine details, leading to inconsistencies in shape between clothing and the person's body as well as distortions in exposed limb regions. To tackle these challenges, we propose a novel shape-guided clothing warping method for virtual try-on, dubbed SCW-VTON, which incorporates global shape constraints and additional limb textures to enhance the realism and consistency of the warped clothing and try-on results. To integrate global shape constraints for clothing warping, we devise a dual-path clothing warping module comprising a shape path and a flow path. The former path captures the clothing shape aligned with the person's body, while the latter path leverages the mapping between the pre- and post-deformation of the clothing shape to guide the estimation of appearance flow. Furthermore, to alleviate distortions in limb regions of try-on results, we integrate detailed limb guidance by developing a limb reconstruction network based on masked image modeling. Through the utilization of SCW-VTON, we are able to generate try-on results with enhanced clothing shape consistency and precise control over details. Extensive experiments demonstrate the superiority of our approach over state-of-the-art methods both qualitatively and quantitatively. The code is available at https://github.com/xyhanHIT/SCW-VTON.
End-to-End Human Instance Matting
Mar 03, 2024



Human instance matting aims to estimate an alpha matte for each human instance in an image, which is extremely challenging and has rarely been studied so far. Despite some efforts to use instance segmentation to generate a trimap for each instance and apply trimap-based matting methods, the resulting alpha mattes are often inaccurate due to inaccurate segmentation. In addition, this approach is computationally inefficient due to multiple executions of the matting method. To address these problems, this paper proposes a novel End-to-End Human Instance Matting (E2E-HIM) framework for simultaneous multiple instance matting in a more efficient manner. Specifically, a general perception network first extracts image features and decodes instance contexts into latent codes. Then, a united guidance network exploits spatial attention and semantics embedding to generate united semantics guidance, which encodes the locations and semantic correspondences of all instances. Finally, an instance matting network decodes the image features and united semantics guidance to predict all instance-level alpha mattes. In addition, we construct a large-scale human instance matting dataset (HIM-100K) comprising over 100,000 human images with instance alpha matte labels. Experiments on HIM-100K demonstrate the proposed E2E-HIM outperforms the existing methods on human instance matting with 50% lower errors and 5X faster speed (6 instances in a 640X640 image). Experiments on the PPM-100, RWP-636, and P3M datasets demonstrate that E2E-HIM also achieves competitive performance on traditional human matting.
Rethinking Context Aggregation in Natural Image Matting
Apr 03, 2023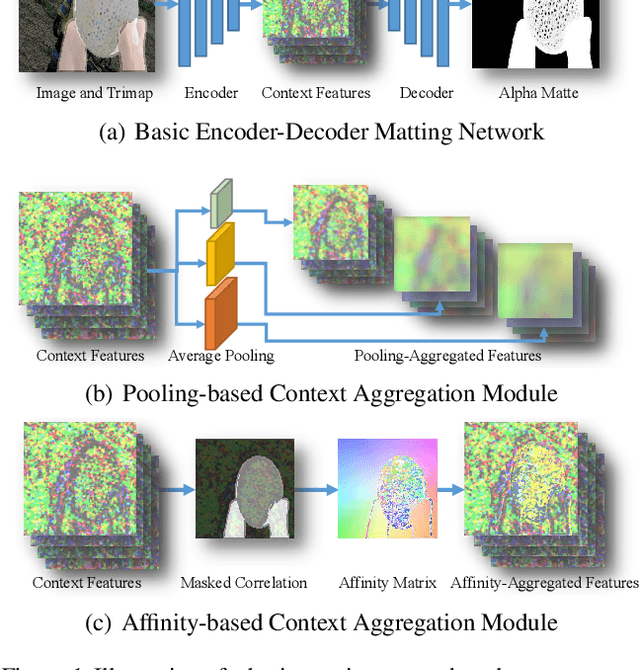
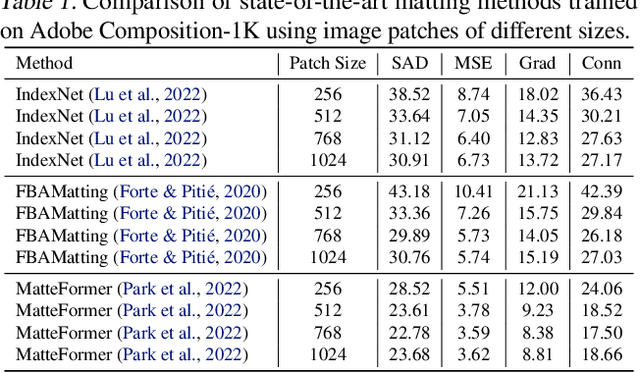
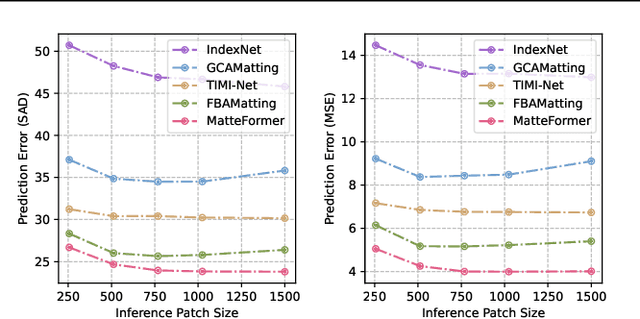
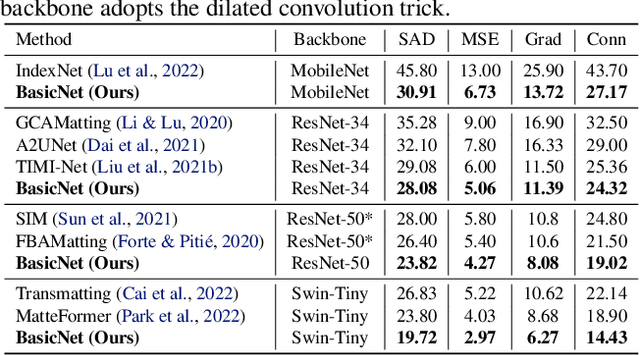
For natural image matting, context information plays a crucial role in estimating alpha mattes especially when it is challenging to distinguish foreground from its background. Exiting deep learning-based methods exploit specifically designed context aggregation modules to refine encoder features. However, the effectiveness of these modules has not been thoroughly explored. In this paper, we conduct extensive experiments to reveal that the context aggregation modules are actually not as effective as expected. We also demonstrate that when learned on large image patches, basic encoder-decoder networks with a larger receptive field can effectively aggregate context to achieve better performance.Upon the above findings, we propose a simple yet effective matting network, named AEMatter, which enlarges the receptive field by incorporating an appearance-enhanced axis-wise learning block into the encoder and adopting a hybrid-transformer decoder. Experimental results on four datasets demonstrate that our AEMatter significantly outperforms state-of-the-art matting methods (e.g., on the Adobe Composition-1K dataset, \textbf{25\%} and \textbf{40\%} reduction in terms of SAD and MSE, respectively, compared against MatteFormer). The code and model are available at \url{https://github.com/QLYoo/AEMatter}.