 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Limb-Aware Virtual Try-On Network with Progressive Clothing Warping
Mar 18, 2025
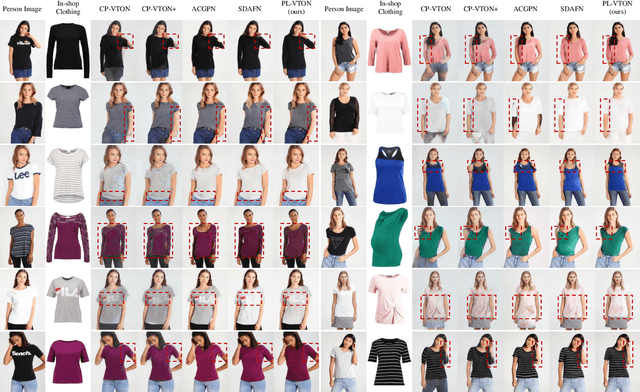


Image-based virtual try-on aims to transfer an in-shop clothing image to a person image. Most existing methods adopt a single global deformation to perform clothing warping directly, which lacks fine-grained modeling of in-shop clothing and leads to distorted clothing appearance. In addition, existing methods usually fail to generate limb details well because they are limited by the used clothing-agnostic person representation without referring to the limb textures of the person image. To address these problems, we propose Limb-aware Virtual Try-on Network named PL-VTON, which performs fine-grained clothing warping progressively and generates high-quality try-on results with realistic limb details. Specifically, we present Progressive Clothing Warping (PCW) that explicitly models the location and size of in-shop clothing and utilizes a two-stage alignment strategy to progressively align the in-shop clothing with the human body. Moreover, a novel gravity-aware loss that considers the fit of the person wearing clothing is adopted to better handle the clothing edges. Then, we design Person Parsing Estimator (PPE) with a non-limb target parsing map to semantically divide the person into various regions, which provides structural constraints on the human body and therefore alleviates texture bleeding between clothing and body regions. Finally, we introduce Limb-aware Texture Fusion (LTF) that focuses on generating realistic details in limb regions, where a coarse try-on result is first generated by fusing the warped clothing image with the person image, then limb textures are further fused with the coarse result under limb-aware guidance to refine limb details. Extensive experiments demonstrate that our PL-VTON outperforms the state-of-the-art methods both qualitatively and quantitatively.
* Accepted by IEEE Transactions on Multimedia (TMM). The code is available at https://github.com/aipixel/PL-VTONv2
AdaPPA: Adaptive Position Pre-Fill Jailbreak Attack Approach Targeting LLMs
Sep 11, 2024



Jailbreak vulnerabilities in Large Language Models (LLMs) refer to methods that extract malicious content from the model by carefully crafting prompts or suffixes, which has garnered significant attention from the research community. However, traditional attack methods, which primarily focus on the semantic level, are easily detected by the model. These methods overlook the difference in the model's alignment protection capabilities at different output stages. To address this issue, we propose an adaptive position pre-fill jailbreak attack approach for executing jailbreak attacks on LLMs. Our method leverages the model's instruction-following capabilities to first output pre-filled safe content, then exploits its narrative-shifting abilities to generate harmful content. Extensive black-box experiments demonstrate our method can improve the attack success rate by 47% on the widely recognized secure model (Llama2) compared to existing approaches. Our code can be found at: https://github.com/Yummy416/AdaPPA.
Uncertainty-boosted Robust Video Activity Anticipation
Apr 29, 2024



Video activity anticipation aims to predict what will happen in the future, embracing a broad application prospect ranging from robot vision and autonomous driving. Despite the recent progress, the data uncertainty issue, reflected as the content evolution process and dynamic correlation in event labels, has been somehow ignored. This reduces the model generalization ability and deep understanding on video content, leading to serious error accumulation and degraded performance. In this paper, we address the uncertainty learning problem and propose an uncertainty-boosted robust video activity anticipation framework, which generates uncertainty values to indicate the credibility of the anticipation results. The uncertainty value is used to derive a temperature parameter in the softmax function to modulate the predicted target activity distribution. To guarantee the distribution adjustment, we construct a reasonable target activity label representation by incorporating the activity evolution from the temporal class correlation and the semantic relationship. Moreover, we quantify the uncertainty into relative values by comparing the uncertainty among sample pairs and their temporal-lengths. This relative strategy provides a more accessible way in uncertainty modeling than quantifying the absolute uncertainty values on the whole dataset. Experiments on multiple backbones and benchmarks show our framework achieves promising performance and better robustness/interpretability. Source codes are available at https://github.com/qzhb/UbRV2A.
Bias-Conflict Sample Synthesis and Adversarial Removal Debias Strategy for Temporal Sentence Grounding in Video
Jan 19, 2024Temporal Sentence Grounding in Video (TSGV) is troubled by dataset bias issue, which is caused by the uneven temporal distribution of the target moments for samples with similar semantic components in input videos or query texts. Existing methods resort to utilizing prior knowledge about bias to artificially break this uneven distribution, which only removes a limited amount of significant language biases. In this work, we propose the bias-conflict sample synthesis and adversarial removal debias strategy (BSSARD), which dynamically generates bias-conflict samples by explicitly leveraging potentially spurious correlations between single-modality features and the temporal position of the target moments. Through adversarial training, its bias generators continuously introduce biases and generate bias-conflict samples to deceive its grounding model. Meanwhile, the grounding model continuously eliminates the introduced biases, which requires it to model multi-modality alignment information. BSSARD will cover most kinds of coupling relationships and disrupt language and visual biases simultaneously. Extensive experiments on Charades-CD and ActivityNet-CD demonstrate the promising debiasing capability of BSSARD. Source codes are available at https://github.com/qzhb/BSSARD.
Progressive Multi-resolution Loss for Crowd Counting
Dec 08, 2022



Crowd counting is usually handled in a density map regression fashion, which is supervised via a L2 loss between the predicted density map and ground truth. To effectively regulate models, various improved L2 loss functions have been proposed to find a better correspondence between predicted density and annotation positions. In this paper, we propose to predict the density map at one resolution but measure the density map at multiple resolutions. By maximizing the posterior probability in such a setting, we obtain a log-formed multi-resolution L2-difference loss, where the traditional single-resolution L2 loss is its particular case. We mathematically prove it is superior to a single-resolution L2 loss. Without bells and whistles, the proposed loss substantially improves several baselines and performs favorably compared to state-of-the-art methods on four crowd counting datasets, ShanghaiTech A & B, UCF-QNRF, and JHU-Crowd++.
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis
Nov 23, 2021
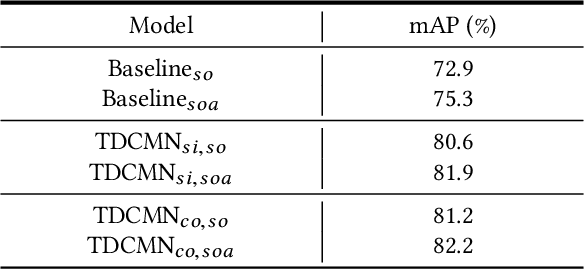
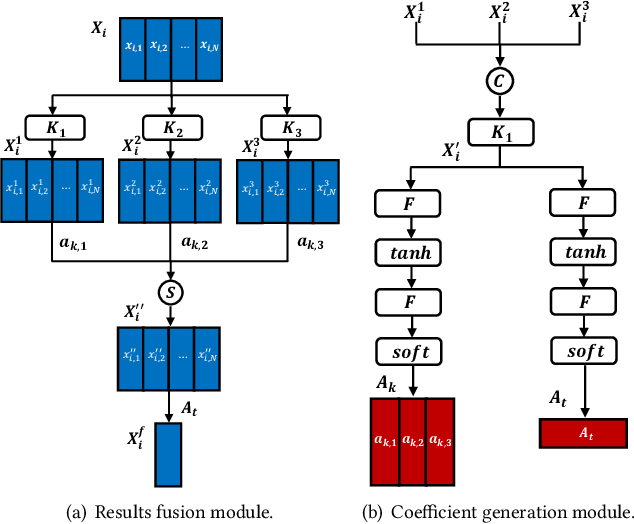
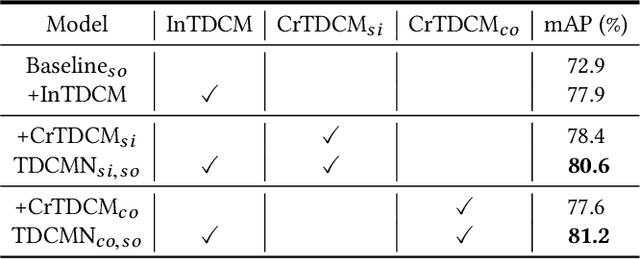
Event analysis in untrimmed videos has attracted increasing attention due to the application of cutting-edge techniques such as CNN. As a well studied property for CNN-based models, the receptive field is a measurement for measuring the spatial range covered by a single feature response, which is crucial in improving the image categorization accuracy. In video domain, video event semantics are actually described by complex interaction among different concepts, while their behaviors vary drastically from one video to another, leading to the difficulty in concept-based analytics for accurate event categorization. To model the concept behavior, we study temporal concept receptive field of concept-based event representation, which encodes the temporal occurrence pattern of different mid-level concepts. Accordingly, we introduce temporal dynamic convolution (TDC) to give stronger flexibility to concept-based event analytics. TDC can adjust the temporal concept receptive field size dynamically according to different inputs. Notably, a set of coefficients are learned to fuse the results of multiple convolutions with different kernel widths that provide various temporal concept receptive field sizes. Different coefficients can generate appropriate and accurate temporal concept receptive field size according to input videos and highlight crucial concepts. Based on TDC, we propose the temporal dynamic concept modeling network (TDCMN) to learn an accurate and complete concept representation for efficient untrimmed video analysis. Experiment results on FCVID and ActivityNet show that TDCMN demonstrates adaptive event recognition ability conditioned on different inputs, and improve the event recognition performance of Concept-based methods by a large margin. Code is available at https://github.com/qzhb/TDCMN.
The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking
Mar 26, 2018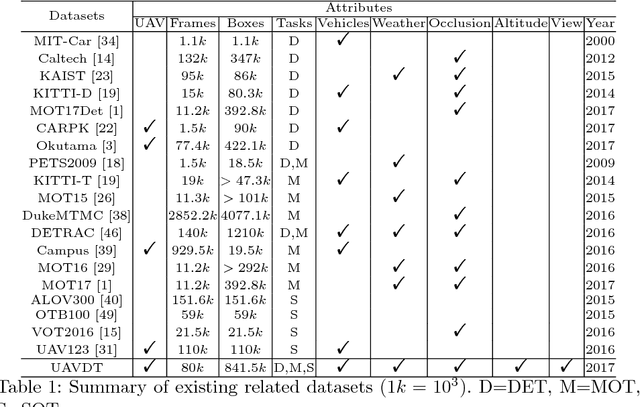
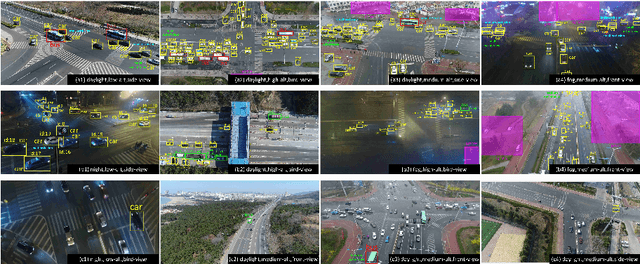
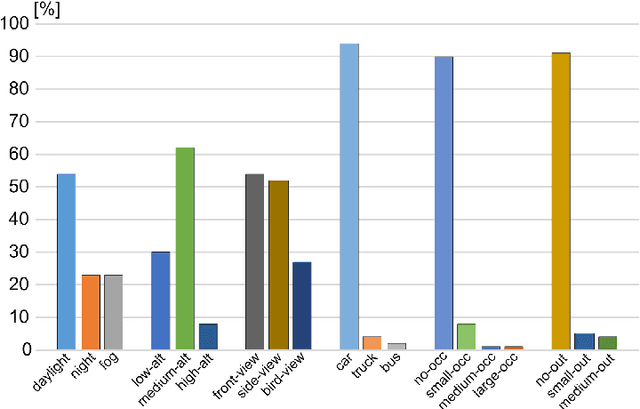
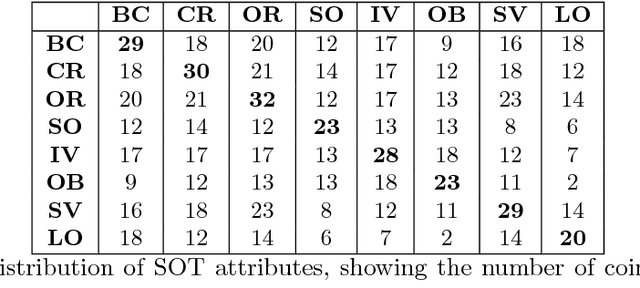
With the advantage of high mobility, Unmanned Aerial Vehicles (UAVs) are used to fuel numerous important applications in computer vision, delivering more efficiency and convenience than surveillance cameras with fixed camera angle, scale and view. However, very limited UAV datasets are proposed, and they focus only on a specific task such as visual tracking or object detection in relatively constrained scenarios. Consequently, it is of great importance to develop an unconstrained UAV benchmark to boost related researches. In this paper, we construct a new UAV benchmark focusing on complex scenarios with new level challenges. Selected from 10 hours raw videos, about 80,000 representative frames are fully annotated with bounding boxes as well as up to 14 kinds of attributes (e.g., weather condition, flying altitude, camera view, vehicle category, and occlusion) for three fundamental computer vision tasks: object detection, single object tracking, and multiple object tracking. Then, a detailed quantitative study is performed using most recent state-of-the-art algorithms for each task. Experimental results show that the current state-of-the-art methods perform relative worse on our dataset, due to the new challenges appeared in UAV based real scenes, e.g., high density, small object, and camera motion. To our knowledge, our work is the first time to explore such issues in unconstrained scenes comprehensively.
Less Is More: Picking Informative Frames for Video Captioning
Mar 05, 2018
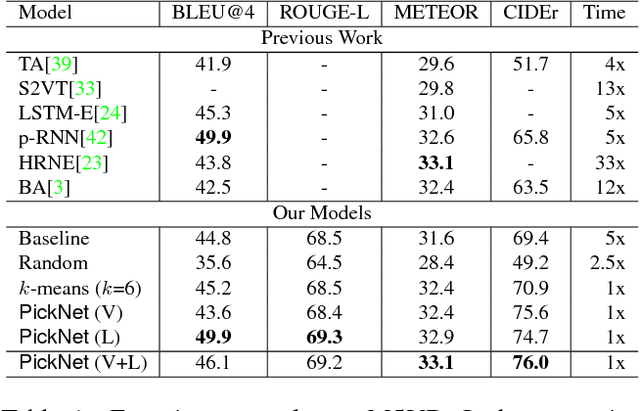
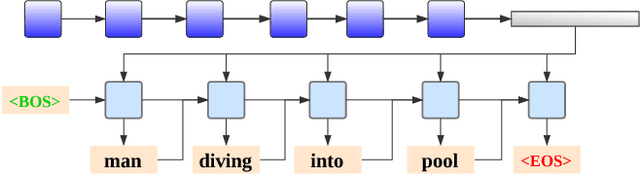
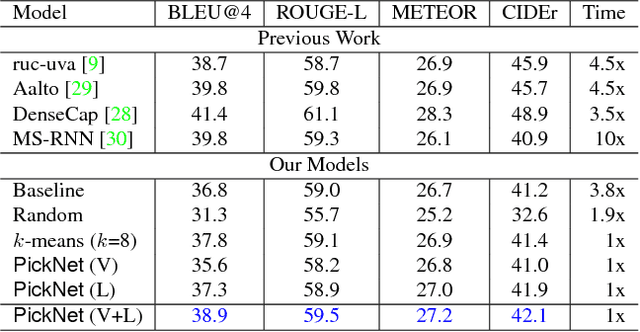
In video captioning task, the best practice has been achieved by attention-based models which associate salient visual components with sentences in the video. However, existing study follows a common procedure which includes a frame-level appearance modeling and motion modeling on equal interval frame sampling, which may bring about redundant visual information, sensitivity to content noise and unnecessary computation cost. We propose a plug-and-play PickNet to perform informative frame picking in video captioning. Based on a standard Encoder-Decoder framework, we develop a reinforcement-learning-based procedure to train the network sequentially, where the reward of each frame picking action is designed by maximizing visual diversity and minimizing textual discrepancy. If the candidate is rewarded, it will be selected and the corresponding latent representation of Encoder-Decoder will be updated for future trials. This procedure goes on until the end of the video sequence. Consequently, a compact frame subset can be selected to represent the visual information and perform video captioning without performance degradation. Experiment results shows that our model can use 6-8 frames to achieve competitive performance across popular benchmarks.