 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgraph Stationary Hardware-Software Inference Co-Design
Jun 21, 2023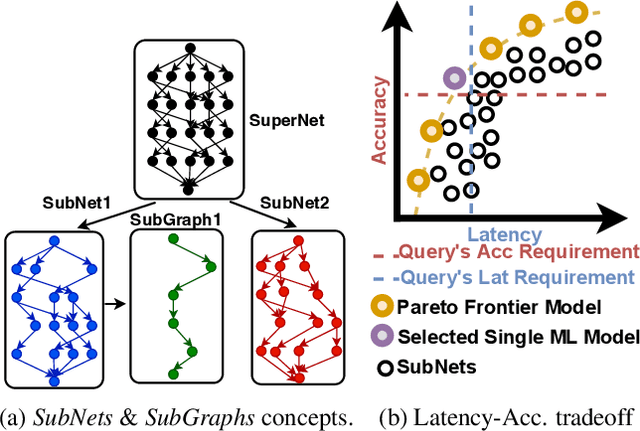



A growing number of applications depend on Machine Learning (ML) functionality and benefits from both higher quality ML predictions and better timeliness (latency) at the same time. A growing body of research in computer architecture, ML, and systems software literature focuses on reaching better latency-accuracy tradeoffs for ML models. Efforts include compression, quantization, pruning, early-exit models, mixed DNN precision, as well as ML inference accelerator designs that minimize latency and energy, while preserving delivered accuracy. All of them, however, yield improvements for a single static point in the latency-accuracy tradeoff space. We make a case for applications that operate in dynamically changing deployment scenarios, where no single static point is optimal. We draw on a recently proposed weight-shared SuperNet mechanism to enable serving a stream of queries that uses (activates) different SubNets within this weight-shared construct. This creates an opportunity to exploit the inherent temporal locality with our proposed SubGraph Stationary (SGS) optimization. We take a hardware-software co-design approach with a real implementation of SGS in SushiAccel and the implementation of a software scheduler SushiSched controlling which SubNets to serve and what to cache in real-time. Combined, they are vertically integrated into SUSHI-an inference serving stack. For the stream of queries, SUSHI yields up to 25% improvement in latency, 0.98% increase in served accuracy. SUSHI can achieve up to 78.7% off-chip energy savings.
Less Is More: Picking Informative Frames for Video Captioning
Mar 05, 2018
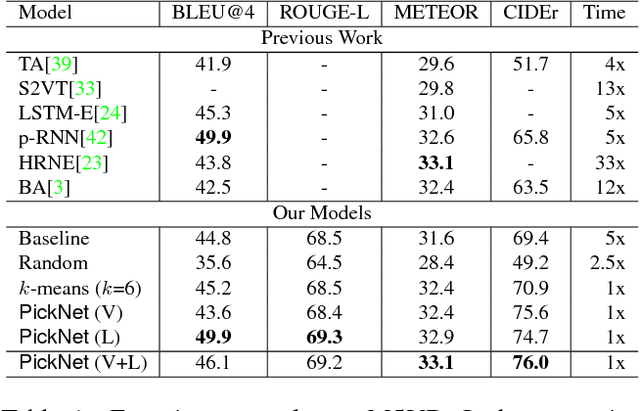
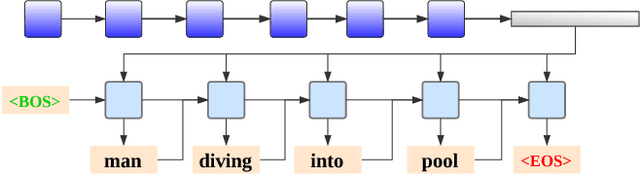
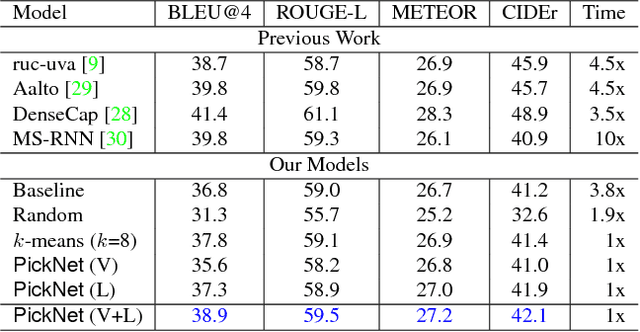
In video captioning task, the best practice has been achieved by attention-based models which associate salient visual components with sentences in the video. However, existing study follows a common procedure which includes a frame-level appearance modeling and motion modeling on equal interval frame sampling, which may bring about redundant visual information, sensitivity to content noise and unnecessary computation cost. We propose a plug-and-play PickNet to perform informative frame picking in video captioning. Based on a standard Encoder-Decoder framework, we develop a reinforcement-learning-based procedure to train the network sequentially, where the reward of each frame picking action is designed by maximizing visual diversity and minimizing textual discrepancy. If the candidate is rewarded, it will be selected and the corresponding latent representation of Encoder-Decoder will be updated for future trials. This procedure goes on until the end of the video sequence. Consequently, a compact frame subset can be selected to represent the visual information and perform video captioning without performance degradation. Experiment results shows that our model can use 6-8 frames to achieve competitive performance across popular benchmarks.