 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKLAS: Using Similarity to Stitch Neural Networks for Improved Accuracy-Efficiency Tradeoffs
May 28, 2026Given the wide range of deployment targets, flexible model selection is essential for optimizing performance within a given compute budget. Recent work demonstrates that stitching pretrained models within a model family enables cost-effective interpolation of the accuracy-efficiency tradeoff space. Stitching transforms intermediate activations from one pretrained model into another, producing a new interpolated stitched network. Such networks provide a pool of deployment options along the accuracy-efficiency spectrum. However, existing stitching approaches often yield suboptimal tradeoffs and lack generalizability, as they primarily rely on heuristics to select stitch configurations. We argue that constructing improved accuracy-efficiency tradeoffs requires explicitly capturing and leveraging the similarity between pretrained models being stitched. To this end, we introduce KLAS, a novel stitch selection framework that automates and generalizes stitch selection across model families by leveraging KL divergence between intermediate representations. KLAS identifies the most promising binary stitches from the $O(k^2n^2)$ possibilities for $k$ pretrained models of depth $n$. Through comprehensive experiments, we demonstrate that KLAS improves the accuracy-efficiency curve of stitched models at the same finetuning cost as baselines. KLAS achieves up to $1.21\%$ higher ImageNet-1K top-1 accuracy at the same computational cost, or maintains accuracy with a $1.33\times$ reduction in FLOPs.
AgentRx: Diagnosing AI Agent Failures from Execution Trajectories
Feb 02, 2026AI agents often fail in ways that are difficult to localize because executions are probabilistic, long-horizon, multi-agent, and mediated by noisy tool outputs. We address this gap by manually annotating failed agent runs and release a novel benchmark of 115 failed trajectories spanning structured API workflows, incident management, and open-ended web/file tasks. Each trajectory is annotated with a critical failure step and a category from a grounded-theory derived, cross-domain failure taxonomy. To mitigate the human cost of failure attribution, we present AGENTRX, an automated domain-agnostic diagnostic framework that pinpoints the critical failure step in a failed agent trajectory. It synthesizes constraints, evaluates them step-by-step, and produces an auditable validation log of constraint violations with associated evidence; an LLM-based judge uses this log to localize the critical step and category. Our framework improves step localization and failure attribution over existing baselines across three domains.
Towards Efficient Large Multimodal Model Serving
Feb 02, 2025Recent advances in generative AI have led to large multi-modal models (LMMs) capable of simultaneously processing inputs of various modalities such as text, images, video, and audio. While these models demonstrate impressive capabilities, efficiently serving them in production environments poses significant challenges due to their complex architectures and heterogeneous resource requirements. We present the first comprehensive systems analysis of two prominent LMM architectures, decoder-only and cross-attention, on six representative open-source models. We investigate their multi-stage inference pipelines and resource utilization patterns that lead to unique systems design implications. We also present an in-depth analysis of production LMM inference traces, uncovering unique workload characteristics, including variable, heavy-tailed request distributions, diverse modal combinations, and bursty traffic patterns. Our key findings reveal that different LMM inference stages exhibit highly heterogeneous performance characteristics and resource demands, while concurrent requests across modalities lead to significant performance interference. To address these challenges, we propose a decoupled serving architecture that enables independent resource allocation and adaptive scaling for each stage. We further propose optimizations such as stage colocation to maximize throughput and resource utilization while meeting the latency objectives.
DεpS: Delayed ε-Shrinking for Faster Once-For-All Training
Jul 08, 2024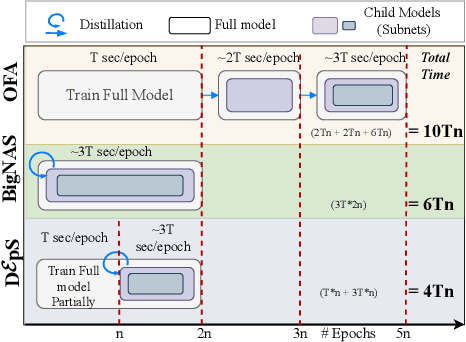

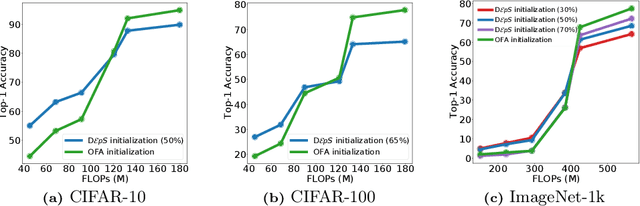

CNNs are increasingly deployed across different hardware, dynamic environments, and low-power embedded devices. This has led to the design and training of CNN architectures with the goal of maximizing accuracy subject to such variable deployment constraints. As the number of deployment scenarios grows, there is a need to find scalable solutions to design and train specialized CNNs. Once-for-all training has emerged as a scalable approach that jointly co-trains many models (subnets) at once with a constant training cost and finds specialized CNNs later. The scalability is achieved by training the full model and simultaneously reducing it to smaller subnets that share model weights (weight-shared shrinking). However, existing once-for-all training approaches incur huge training costs reaching 1200 GPU hours. We argue this is because they either start the process of shrinking the full model too early or too late. Hence, we propose Delayed $\epsilon$-Shrinking (D$\epsilon$pS) that starts the process of shrinking the full model when it is partially trained (~50%) which leads to training cost improvement and better in-place knowledge distillation to smaller models. The proposed approach also consists of novel heuristics that dynamically adjust subnet learning rates incrementally (E), leading to improved weight-shared knowledge distillation from larger to smaller subnets as well. As a result, DEpS outperforms state-of-the-art once-for-all training techniques across different datasets including CIFAR10/100, ImageNet-100, and ImageNet-1k on accuracy and cost. It achieves 1.83% higher ImageNet-1k top1 accuracy or the same accuracy with 1.3x reduction in FLOPs and 2.5x drop in training cost (GPU*hrs)
SuperServe: Fine-Grained Inference Serving for Unpredictable Workloads
Dec 27, 2023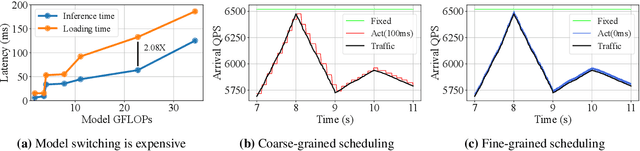
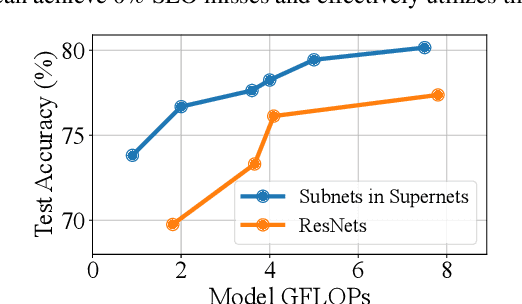
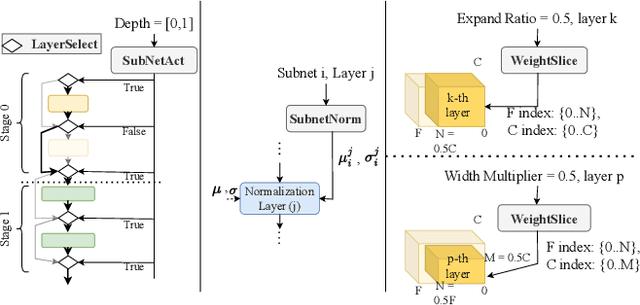
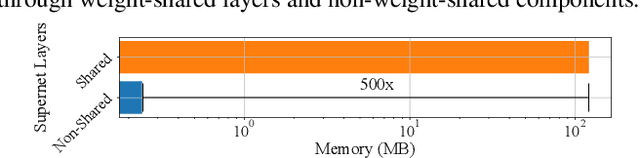
The increasing deployment of ML models on the critical path of production applications in both datacenter and the edge requires ML inference serving systems to serve these models under unpredictable and bursty request arrival rates. Serving models under such conditions requires these systems to strike a careful balance between the latency and accuracy requirements of the application and the overall efficiency of utilization of scarce resources. State-of-the-art systems resolve this tension by either choosing a static point in the latency-accuracy tradeoff space to serve all requests or load specific models on the critical path of request serving. In this work, we instead resolve this tension by simultaneously serving the entire-range of models spanning the latency-accuracy tradeoff space. Our novel mechanism, SubNetAct, achieves this by carefully inserting specialized operators in weight-shared SuperNetworks. These operators enable SubNetAct to dynamically route requests through the network to meet a latency and accuracy target. SubNetAct requires upto 2.6x lower memory to serve a vastly-higher number of models than prior state-of-the-art. In addition, SubNetAct's near-instantaneous actuation of models unlocks the design space of fine-grained, reactive scheduling policies. We explore the design of one such extremely effective policy, SlackFit and instantiate both SubNetAct and SlackFit in a real system, SuperServe. SuperServe achieves 4.67% higher accuracy for the same SLO attainment and 2.85x higher SLO attainment for the same accuracy on a trace derived from the real-world Microsoft Azure Functions workload and yields the best trade-offs on a wide range of extremely-bursty synthetic traces automatically.
ABKD: Graph Neural Network Compression with Attention-Based Knowledge Distillation
Oct 24, 2023

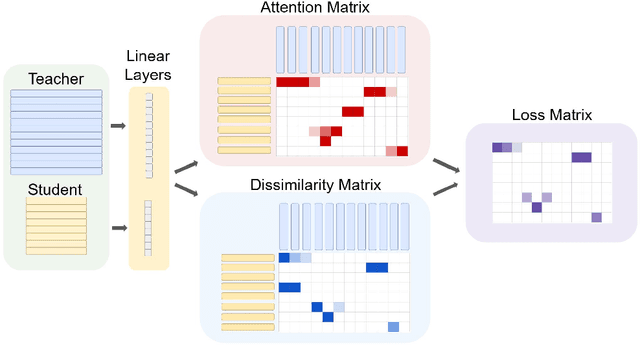
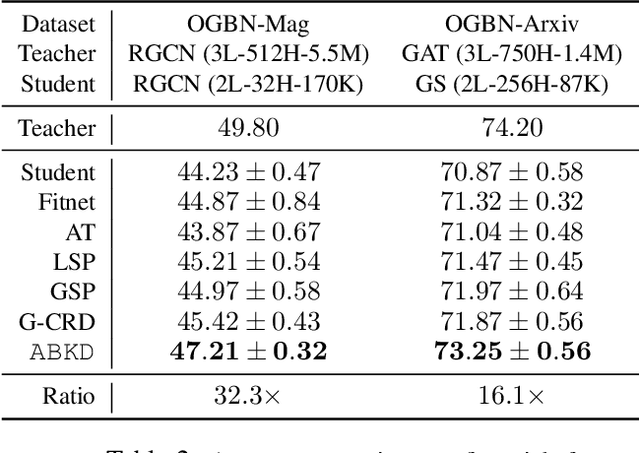
Graph Neural Networks (GNNs) have proven to be quite versatile for a variety of applications, including recommendation systems, fake news detection, drug discovery, and even computer vision. Due to the expanding size of graph-structured data, GNN models have also increased in complexity, leading to substantial latency issues. This is primarily attributed to the irregular structure of graph data and its access pattern into memory. The natural solution to reduce latency is to compress large GNNs into small GNNs. One way to do this is via knowledge distillation (KD). However, most KD approaches for GNNs only consider the outputs of the last layers and do not consider the outputs of the intermediate layers of the GNNs; these layers may contain important inductive biases indicated by the graph structure. To address this shortcoming, we propose a novel KD approach to GNN compression that we call Attention-Based Knowledge Distillation (ABKD). ABKD is a KD approach that uses attention to identify important intermediate teacher-student layer pairs and focuses on aligning their outputs. ABKD enables higher compression of GNNs with a smaller accuracy dropoff compared to existing KD approaches. On average, we achieve a 1.79% increase in accuracy with a 32.3x compression ratio on OGBN-Mag, a large graph dataset, compared to state-of-the-art approaches.
Subgraph Stationary Hardware-Software Inference Co-Design
Jun 21, 2023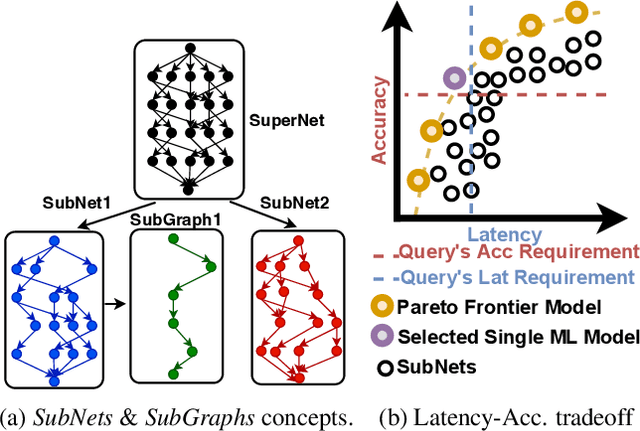



A growing number of applications depend on Machine Learning (ML) functionality and benefits from both higher quality ML predictions and better timeliness (latency) at the same time. A growing body of research in computer architecture, ML, and systems software literature focuses on reaching better latency-accuracy tradeoffs for ML models. Efforts include compression, quantization, pruning, early-exit models, mixed DNN precision, as well as ML inference accelerator designs that minimize latency and energy, while preserving delivered accuracy. All of them, however, yield improvements for a single static point in the latency-accuracy tradeoff space. We make a case for applications that operate in dynamically changing deployment scenarios, where no single static point is optimal. We draw on a recently proposed weight-shared SuperNet mechanism to enable serving a stream of queries that uses (activates) different SubNets within this weight-shared construct. This creates an opportunity to exploit the inherent temporal locality with our proposed SubGraph Stationary (SGS) optimization. We take a hardware-software co-design approach with a real implementation of SGS in SushiAccel and the implementation of a software scheduler SushiSched controlling which SubNets to serve and what to cache in real-time. Combined, they are vertically integrated into SUSHI-an inference serving stack. For the stream of queries, SUSHI yields up to 25% improvement in latency, 0.98% increase in served accuracy. SUSHI can achieve up to 78.7% off-chip energy savings.
SuperFed: Weight Shared Federated Learning
Jan 26, 2023Federated Learning (FL) is a well-established technique for privacy preserving distributed training. Much attention has been given to various aspects of FL training. A growing number of applications that consume FL-trained models, however, increasingly operate under dynamically and unpredictably variable conditions, rendering a single model insufficient. We argue for training a global family of models cost efficiently in a federated fashion. Training them independently for different tradeoff points incurs $O(k)$ cost for any k architectures of interest, however. Straightforward applications of FL techniques to recent weight-shared training approaches is either infeasible or prohibitively expensive. We propose SuperFed - an architectural framework that incurs $O(1)$ cost to co-train a large family of models in a federated fashion by leveraging weight-shared learning. We achieve an order of magnitude cost savings on both communication and computation by proposing two novel training mechanisms: (a) distribution of weight-shared models to federated clients, (b) central aggregation of arbitrarily overlapping weight-shared model parameters. The combination of these mechanisms is shown to reach an order of magnitude (9.43x) reduction in computation and communication cost for training a $5*10^{18}$-sized family of models, compared to independently training as few as $k = 9$ DNNs without any accuracy loss.
UnfoldML: Cost-Aware and Uncertainty-Based Dynamic 2D Prediction for Multi-Stage Classification
Oct 28, 2022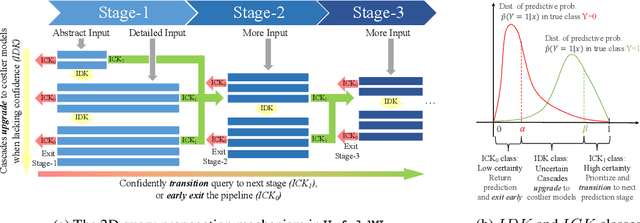

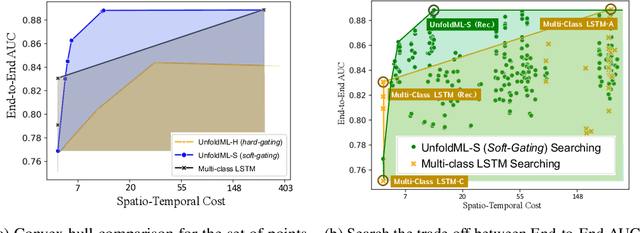
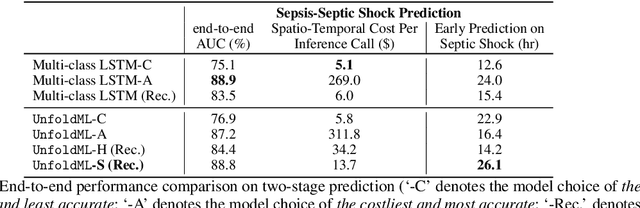
Machine Learning (ML) research has focused on maximizing the accuracy of predictive tasks. ML models, however, are increasingly more complex, resource intensive, and costlier to deploy in resource-constrained environments. These issues are exacerbated for prediction tasks with sequential classification on progressively transitioned stages with ''happens-before'' relation between them.We argue that it is possible to ''unfold'' a monolithic single multi-class classifier, typically trained for all stages using all data, into a series of single-stage classifiers. Each single-stage classifier can be cascaded gradually from cheaper to more expensive binary classifiers that are trained using only the necessary data modalities or features required for that stage. UnfoldML is a cost-aware and uncertainty-based dynamic 2D prediction pipeline for multi-stage classification that enables (1) navigation of the accuracy/cost tradeoff space, (2) reducing the spatio-temporal cost of inference by orders of magnitude, and (3) early prediction on proceeding stages. UnfoldML achieves orders of magnitude better cost in clinical settings, while detecting multi-stage disease development in real time. It achieves within 0.1% accuracy from the highest-performing multi-class baseline, while saving close to 20X on spatio-temporal cost of inference and earlier (3.5hrs) disease onset prediction. We also show that UnfoldML generalizes to image classification, where it can predict different level of labels (from coarse to fine) given different level of abstractions of a image, saving close to 5X cost with as little as 0.4% accuracy reduction.
CompOFA: Compound Once-For-All Networks for Faster Multi-Platform Deployment
Apr 26, 2021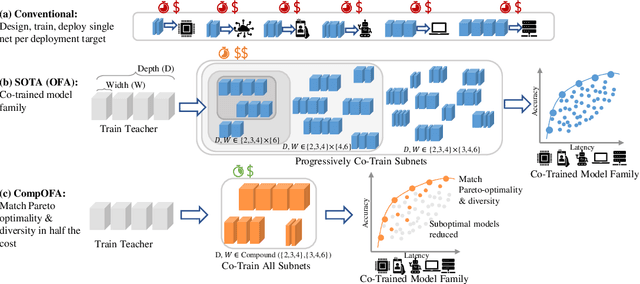
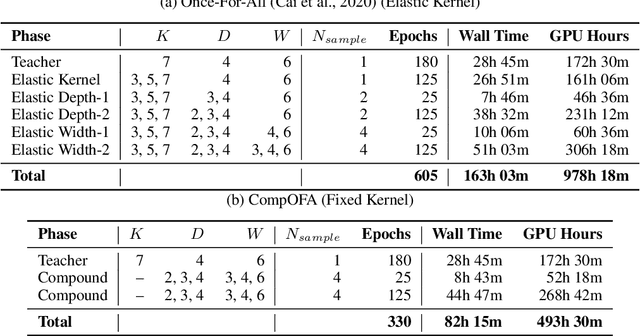
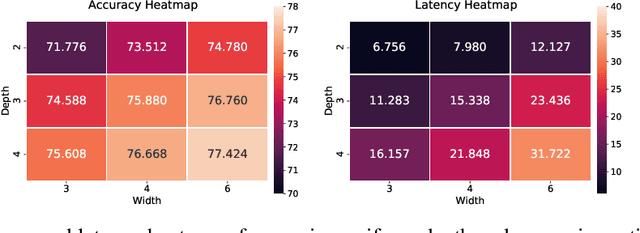

The emergence of CNNs in mainstream deployment has necessitated methods to design and train efficient architectures tailored to maximize the accuracy under diverse hardware & latency constraints. To scale these resource-intensive tasks with an increasing number of deployment targets, Once-For-All (OFA) proposed an approach to jointly train several models at once with a constant training cost. However, this cost remains as high as 40-50 GPU days and also suffers from a combinatorial explosion of sub-optimal model configurations. We seek to reduce this search space -- and hence the training budget -- by constraining search to models close to the accuracy-latency Pareto frontier. We incorporate insights of compound relationships between model dimensions to build CompOFA, a design space smaller by several orders of magnitude. Through experiments on ImageNet, we demonstrate that even with simple heuristics we can achieve a 2x reduction in training time and 216x speedup in model search/extraction time compared to the state of the art, without loss of Pareto optimality! We also show that this smaller design space is dense enough to support equally accurate models for a similar diversity of hardware and latency targets, while also reducing the complexity of the training and subsequent extraction algorithms.