 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABKD: Graph Neural Network Compression with Attention-Based Knowledge Distillation
Oct 24, 2023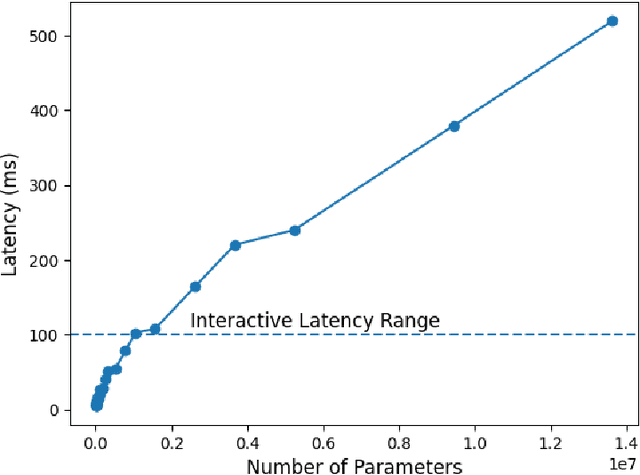

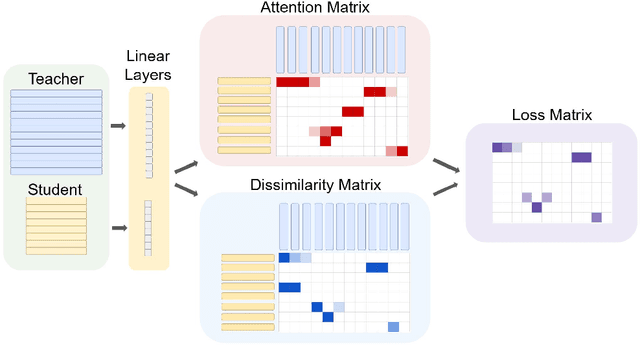
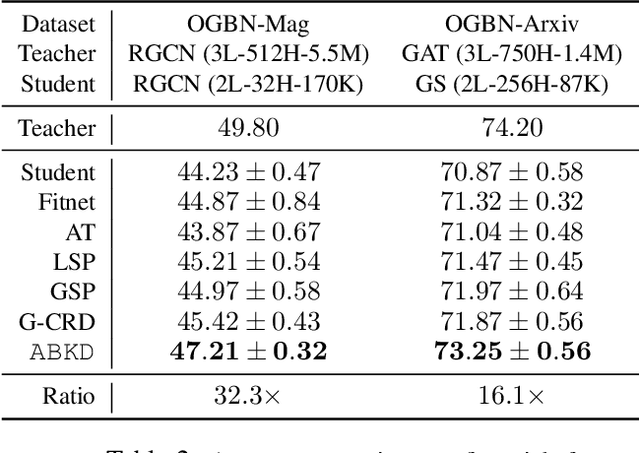
Graph Neural Networks (GNNs) have proven to be quite versatile for a variety of applications, including recommendation systems, fake news detection, drug discovery, and even computer vision. Due to the expanding size of graph-structured data, GNN models have also increased in complexity, leading to substantial latency issues. This is primarily attributed to the irregular structure of graph data and its access pattern into memory. The natural solution to reduce latency is to compress large GNNs into small GNNs. One way to do this is via knowledge distillation (KD). However, most KD approaches for GNNs only consider the outputs of the last layers and do not consider the outputs of the intermediate layers of the GNNs; these layers may contain important inductive biases indicated by the graph structure. To address this shortcoming, we propose a novel KD approach to GNN compression that we call Attention-Based Knowledge Distillation (ABKD). ABKD is a KD approach that uses attention to identify important intermediate teacher-student layer pairs and focuses on aligning their outputs. ABKD enables higher compression of GNNs with a smaller accuracy dropoff compared to existing KD approaches. On average, we achieve a 1.79% increase in accuracy with a 32.3x compression ratio on OGBN-Mag, a large graph dataset, compared to state-of-the-art approaches.