 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRocketKV: Accelerating Long-Context LLM Inference via Two-Stage KV Cache Compression
Feb 19, 2025



Transformer-based Large Language Models rely critically on KV cache to efficiently handle extended contexts during the decode phase. Yet, the size of the KV cache grows proportionally with the input length, burdening both memory bandwidth and capacity as decoding progresses. To address this challenge, we present RocketKV, a training-free KV cache compression strategy designed specifically to reduce both memory bandwidth and capacity demand of KV cache during the decode phase. RocketKV contains two consecutive stages. In the first stage, it performs coarse-grain KV cache eviction on the input sequence tokens with SnapKV++, a method improved upon SnapKV by introducing adaptive pooling size and full compatibility with grouped-query attention. In the second stage, it adopts a hybrid attention method to conduct fine-grain top-k sparse attention, approximating the attention scores by leveraging both head and sequence dimensional reductions. Combining these two stages, RocketKV achieves significant KV cache fetching bandwidth and storage savings while maintaining comparable accuracy to full KV cache attention. We show that RocketKV provides end-to-end speedup by up to 3$\times$ as well as peak memory reduction by up to 31% in the decode phase on an NVIDIA H100 GPU compared to the full KV cache baseline, while achieving negligible accuracy loss on a variety of long-context tasks.
Real-time Digital RF Emulation -- II: A Near Memory Custom Accelerator
Jun 13, 2024



A near memory hardware accelerator, based on a novel direct path computational model, for real-time emulation of radio frequency systems is demonstrated. Our evaluation of hardware performance uses both application-specific integrated circuits (ASIC) and field programmable gate arrays (FPGA) methodologies: 1). The ASIC testchip implementation, using TSMC 28nm CMOS, leverages distributed autonomous control to extract concurrency in compute as well as low latency. It achieves a $518$ MHz per channel bandwidth in a prototype $4$-node system. The maximum emulation range supported in this paradigm is $9.5$ km with $0.24$ $\mu$s of per-sample emulation latency. 2). The FPGA-based implementation, evaluated on a Xilinx ZCU104 board, demonstrates a $9$-node test case (two Transmitters, one Receiver, and $6$ passive reflectors) with an emulation range of $1.13$ km to $27.3$ km at $215$ MHz bandwidth.
Zero-Space Cost Fault Tolerance for Transformer-based Language Models on ReRAM
Jan 22, 2024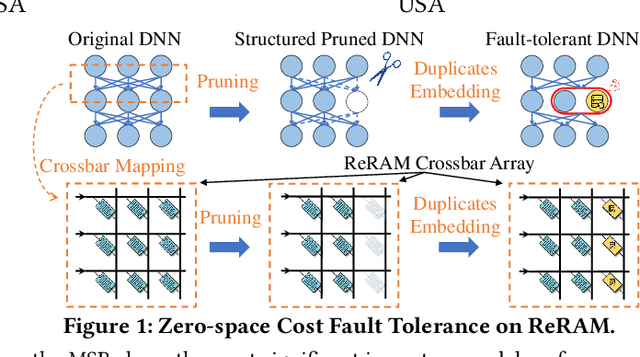

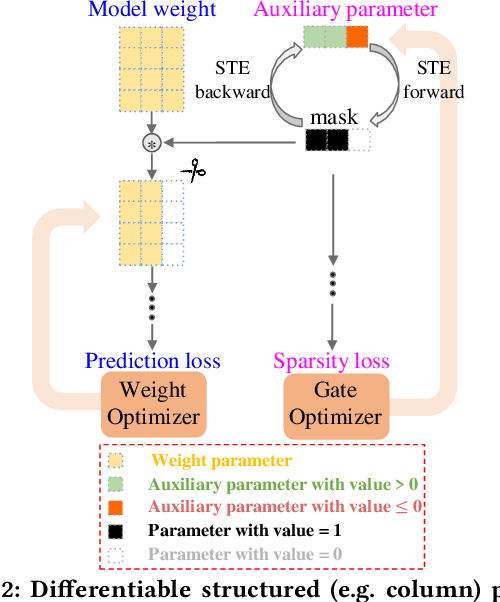

Resistive Random Access Memory (ReRAM) has emerged as a promising platform for deep neural networks (DNNs) due to its support for parallel in-situ matrix-vector multiplication. However, hardware failures, such as stuck-at-fault defects, can result in significant prediction errors during model inference. While additional crossbars can be used to address these failures, they come with storage overhead and are not efficient in terms of space, energy, and cost. In this paper, we propose a fault protection mechanism that incurs zero space cost. Our approach includes: 1) differentiable structure pruning of rows and columns to reduce model redundancy, 2) weight duplication and voting for robust output, and 3) embedding duplicated most significant bits (MSBs) into the model weight. We evaluate our method on nine tasks of the GLUE benchmark with the BERT model, and experimental results prove its effectiveness.
ABKD: Graph Neural Network Compression with Attention-Based Knowledge Distillation
Oct 24, 2023

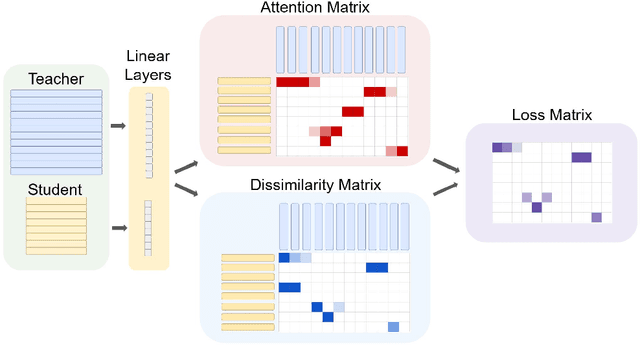
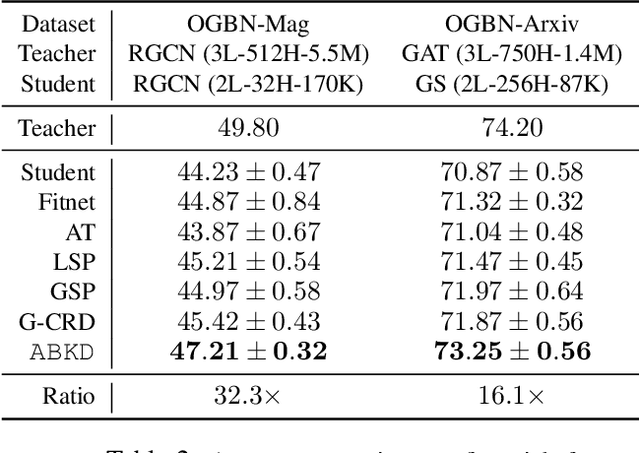
Graph Neural Networks (GNNs) have proven to be quite versatile for a variety of applications, including recommendation systems, fake news detection, drug discovery, and even computer vision. Due to the expanding size of graph-structured data, GNN models have also increased in complexity, leading to substantial latency issues. This is primarily attributed to the irregular structure of graph data and its access pattern into memory. The natural solution to reduce latency is to compress large GNNs into small GNNs. One way to do this is via knowledge distillation (KD). However, most KD approaches for GNNs only consider the outputs of the last layers and do not consider the outputs of the intermediate layers of the GNNs; these layers may contain important inductive biases indicated by the graph structure. To address this shortcoming, we propose a novel KD approach to GNN compression that we call Attention-Based Knowledge Distillation (ABKD). ABKD is a KD approach that uses attention to identify important intermediate teacher-student layer pairs and focuses on aligning their outputs. ABKD enables higher compression of GNNs with a smaller accuracy dropoff compared to existing KD approaches. On average, we achieve a 1.79% increase in accuracy with a 32.3x compression ratio on OGBN-Mag, a large graph dataset, compared to state-of-the-art approaches.
Subgraph Stationary Hardware-Software Inference Co-Design
Jun 21, 2023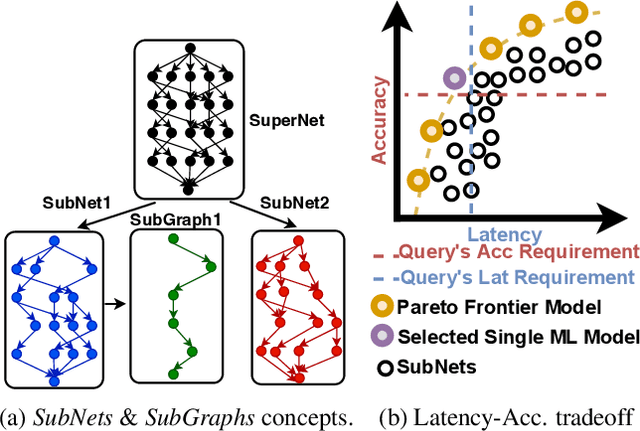



A growing number of applications depend on Machine Learning (ML) functionality and benefits from both higher quality ML predictions and better timeliness (latency) at the same time. A growing body of research in computer architecture, ML, and systems software literature focuses on reaching better latency-accuracy tradeoffs for ML models. Efforts include compression, quantization, pruning, early-exit models, mixed DNN precision, as well as ML inference accelerator designs that minimize latency and energy, while preserving delivered accuracy. All of them, however, yield improvements for a single static point in the latency-accuracy tradeoff space. We make a case for applications that operate in dynamically changing deployment scenarios, where no single static point is optimal. We draw on a recently proposed weight-shared SuperNet mechanism to enable serving a stream of queries that uses (activates) different SubNets within this weight-shared construct. This creates an opportunity to exploit the inherent temporal locality with our proposed SubGraph Stationary (SGS) optimization. We take a hardware-software co-design approach with a real implementation of SGS in SushiAccel and the implementation of a software scheduler SushiSched controlling which SubNets to serve and what to cache in real-time. Combined, they are vertically integrated into SUSHI-an inference serving stack. For the stream of queries, SUSHI yields up to 25% improvement in latency, 0.98% increase in served accuracy. SUSHI can achieve up to 78.7% off-chip energy savings.
FORMS: Fine-grained Polarized ReRAM-based In-situ Computation for Mixed-signal DNN Accelerator
Jun 16, 2021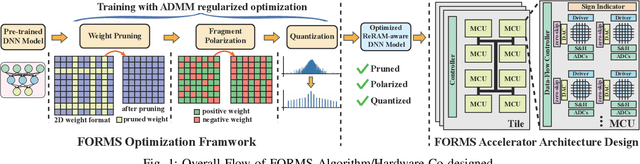
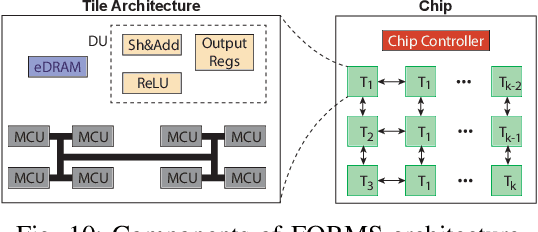
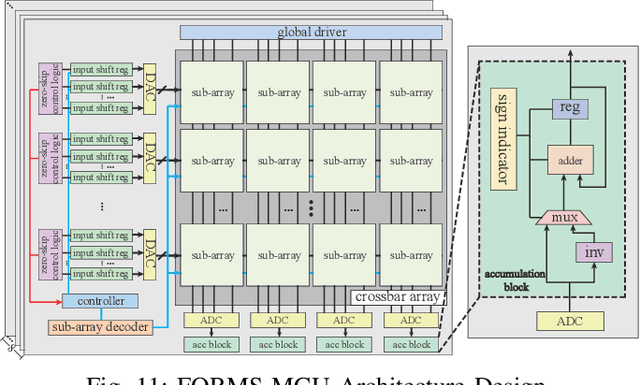

Recent works demonstrated the promise of using resistive random access memory (ReRAM) as an emerging technology to perform inherently parallel analog domain in-situ matrix-vector multiplication -- the intensive and key computation in DNNs. With weights stored in the ReRAM crossbar cells as conductance, when the input vector is applied to word lines, the matrix-vector multiplication results can be generated as the current in bit lines. A key problem is that the weight can be either positive or negative, but the in-situ computation assumes all cells on each crossbar column with the same sign. The current architectures either use two ReRAM crossbars for positive and negative weights, or add an offset to weights so that all values become positive. Neither solution is ideal: they either double the cost of crossbars, or incur extra offset circuity. To better solve this problem, this paper proposes FORMS, a fine-grained ReRAM-based DNN accelerator with polarized weights. Instead of trying to represent the positive/negative weights, our key design principle is to enforce exactly what is assumed in the in-situ computation -- ensuring that all weights in the same column of a crossbar have the same sign. It naturally avoids the cost of an additional crossbar. Such weights can be nicely generated using alternating direction method of multipliers (ADMM) regularized optimization, which can exactly enforce certain patterns in DNN weights. To achieve high accuracy, we propose to use fine-grained sub-array columns, which provide a unique opportunity for input zero-skipping, significantly avoiding unnecessary computations. It also makes the hardware much easier to implement. Putting all together, with the same optimized models, FORMS achieves significant throughput improvement and speed up in frame per second over ISAAC with similar area cost.