 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLate Breaking Results: Conversion of Neural Networks into Logic Flows for Edge Computing
Jan 29, 2026Neural networks have been successfully applied in various resource-constrained edge devices, where usually central processing units (CPUs) instead of graphics processing units exist due to limited power availability. State-of-the-art research still focuses on efficiently executing enormous numbers of multiply-accumulate (MAC) operations. However, CPUs themselves are not good at executing such mathematical operations on a large scale, since they are more suited to execute control flow logic, i.e., computer algorithms. To enhance the computation efficiency of neural networks on CPUs, in this paper, we propose to convert them into logic flows for execution. Specifically, neural networks are first converted into equivalent decision trees, from which decision paths with constant leaves are then selected and compressed into logic flows. Such logic flows consist of if and else structures and a reduced number of MAC operations. Experimental results demonstrate that the latency can be reduced by up to 14.9 % on a simulated RISC-V CPU without any accuracy degradation. The code is open source at https://github.com/TUDa-HWAI/NN2Logic
PEL-NAS: Search Space Partitioned Architecture Prompt Co-Evolutionary LLM-driven Hardware-Aware Neural Architecture Search
Oct 01, 2025Hardware-Aware Neural Architecture Search (HW-NAS) requires joint optimization of accuracy and latency under device constraints. Traditional supernet-based methods require multiple GPU days per dataset. Large Language Model (LLM)-driven approaches avoid training a large supernet and can provide quick feedback, but we observe an exploration bias: the LLM repeatedly proposes neural network designs within limited search space and fails to discover architectures across different latency ranges in the entire search space. To address this issue, we propose PEL-NAS: a search space Partitioned, architecture prompt co-Evolutionary and LLM-driven Neural Architecture Search that can generate neural networks with high accuracy and low latency with reduced search cost. Our proposed PEL-NAS has three key components: 1) a complexity-driven partitioning engine that divides the search space by complexity to enforce diversity and mitigate exploration bias; 2) an LLM-powered architecture prompt co-evolution operator, in which the LLM first updates a knowledge base of design heuristics based on results from the previous round, then performs a guided evolution algorithm on architectures with prompts that incorporate this knowledge base. Prompts and designs improve together across rounds which avoids random guesswork and improve efficiency; 3) a zero-cost predictor to avoid training a large number of candidates from scratch. Experimental results show that on HW-NAS-Bench, PEL-NAS can achieve overall higher HV, lower IGD, and up to 54% lower latency than baselines at similar accuracy. Meanwhile, the search cost drops from days to minutes compared with traditional supernet baselines.
Rethinking the Potential of Layer Freezing for Efficient DNN Training
Aug 20, 2025With the growing size of deep neural networks and datasets, the computational costs of training have significantly increased. The layer-freezing technique has recently attracted great attention as a promising method to effectively reduce the cost of network training. However, in traditional layer-freezing methods, frozen layers are still required for forward propagation to generate feature maps for unfrozen layers, limiting the reduction of computation costs. To overcome this, prior works proposed a hypothetical solution, which caches feature maps from frozen layers as a new dataset, allowing later layers to train directly on stored feature maps. While this approach appears to be straightforward, it presents several major challenges that are severely overlooked by prior literature, such as how to effectively apply augmentations to feature maps and the substantial storage overhead introduced. If these overlooked challenges are not addressed, the performance of the caching method will be severely impacted and even make it infeasible. This paper is the first to comprehensively explore these challenges and provides a systematic solution. To improve training accuracy, we propose \textit{similarity-aware channel augmentation}, which caches channels with high augmentation sensitivity with a minimum additional storage cost. To mitigate storage overhead, we incorporate lossy data compression into layer freezing and design a \textit{progressive compression} strategy, which increases compression rates as more layers are frozen, effectively reducing storage costs. Finally, our solution achieves significant reductions in training cost while maintaining model accuracy, with a minor time overhead. Additionally, we conduct a comprehensive evaluation of freezing and compression strategies, providing insights into optimizing their application for efficient DNN training.
ACE: Exploring Activation Cosine Similarity and Variance for Accurate and Calibration-Efficient LLM Pruning
May 28, 2025



With the rapid expansion of large language models (LLMs), the demand for memory and computational resources has grown significantly. Recent advances in LLM pruning aim to reduce the size and computational cost of these models. However, existing methods often suffer from either suboptimal pruning performance or low time efficiency during the pruning process. In this work, we propose an efficient and effective pruning method that simultaneously achieves high pruning performance and fast pruning speed with improved calibration efficiency. Our approach introduces two key innovations: (1) An activation cosine similarity loss-guided pruning metric, which considers the angular deviation of the output activation between the dense and pruned models. (2) An activation variance-guided pruning metric, which helps preserve semantic distinctions in output activations after pruning, enabling effective pruning with shorter input sequences. These two components can be readily combined to enhance LLM pruning in both accuracy and efficiency. Experimental results show that our method achieves up to an 18% reduction in perplexity and up to 63% decrease in pruning time on prevalent LLMs such as LLaMA, LLaMA-2, and OPT.
KerZOO: Kernel Function Informed Zeroth-Order Optimization for Accurate and Accelerated LLM Fine-Tuning
May 24, 2025Large language models (LLMs) have demonstrated impressive capabilities across numerous NLP tasks. Nevertheless, conventional first-order fine-tuning techniques impose heavy memory demands, creating practical obstacles to real-world applications. Zeroth-order (ZO) optimization has recently emerged as a promising memory-efficient alternative, as it circumvents the need for backpropagation by estimating gradients solely through forward passes--making it particularly suitable for resource-limited environments. Despite its efficiency, ZO optimization suffers from gradient estimation bias, which significantly hinders convergence speed. To address this, we analytically identify and characterize the lower-order bias introduced during ZO-based gradient estimation in LLM fine-tuning. Motivated by tools in mathematical physics, we introduce a kernel-function-based ZO framework aimed at mitigating this bias and improving optimization stability. KerZOO achieves comparable or superior performance to existing ZO baselines in both full-parameter and parameter-efficient fine-tuning settings of LLMs, while significantly reducing the number of iterations required to reach convergence. For example, KerZOO reduces total GPU training hours by as much as 74% and 44% on WSC and MultiRC datasets in fine-tuning OPT-2.7B model and can exceed the MeZO baseline by 2.9% and 2.6% in accuracy. We show that the kernel function is an effective avenue for reducing estimation bias in ZO methods.
PromptV: Leveraging LLM-powered Multi-Agent Prompting for High-quality Verilog Generation
Dec 15, 2024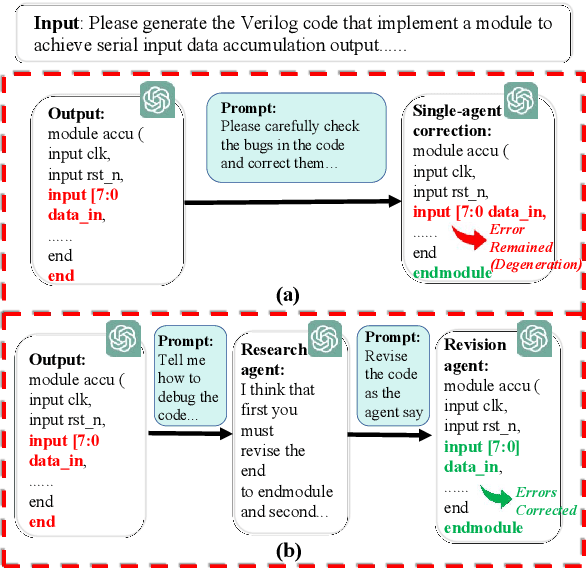
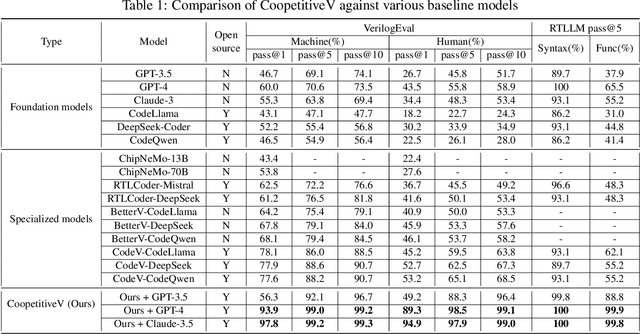
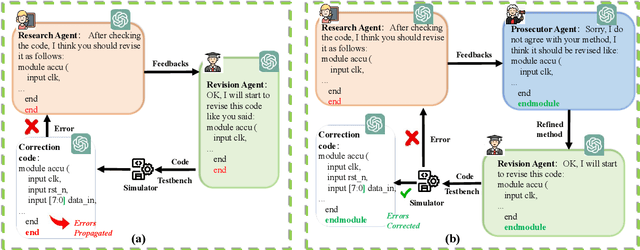

Recent advances in agentic LLMs have demonstrated remarkable automated Verilog code generation capabilities. However, existing approaches either demand substantial computational resources or rely on LLM-assisted single-agent prompt learning techniques, which we observe for the first time has a degeneration issue - characterized by deteriorating generative performance and diminished error detection and correction capabilities. This paper proposes a novel multi-agent prompt learning framework to address these limitations and enhance code generation quality. We show for the first time that multi-agent architectures can effectively mitigate the degeneration risk while improving code error correction capabilities, resulting in higher-quality Verilog code generation. Experimental results show that the proposed method could achieve 96.4% and 96.5% pass@10 scores on VerilogEval Machine and Human benchmarks, respectively while attaining 100% Syntax and 99.9% Functionality pass@5 metrics on the RTLLM benchmark.
Enhanced Computationally Efficient Long LoRA Inspired Perceiver Architectures for Auto-Regressive Language Modeling
Dec 08, 2024The Transformer architecture has revolutionized the Natural Language Processing field and is the backbone of Large Language Models (LLMs). The Transformer uses the attention mechanism that computes the pair-wise similarity between its input tokens to produce latent vectors that are able to understand the semantic meaning of the input text. One of the challenges in the Transformer architecture is the quadratic complexity of the attention mechanism that prohibits the efficient processing of long sequence lengths. While many recent research works have attempted to provide a reduction from $O(n^2)$ time complexity of attention to semi-linear complexity, it remains an unsolved problem in the sense of maintaining a high performance when such complexity is reduced. One of the important works in this respect is the Perceiver class of architectures that have demonstrated excellent performance while reducing the computation complexity. In this paper, we use the PerceiverAR that was proposed for Auto-Regressive modeling as a baseline, and provide three different architectural enhancements to it with varying computation overhead tradeoffs. Inspired by the recently proposed efficient attention computation approach of Long-LoRA, we then present an equally efficient Perceiver-based architecture (termed as Long LoRA Pereceiver - LLP) that can be used as the base architecture in LLMs instead of just a fine-tuning add-on. Our results on different benchmarks indicate impressive improvements compared to recent Transformer based models.
Zero-Space Cost Fault Tolerance for Transformer-based Language Models on ReRAM
Jan 22, 2024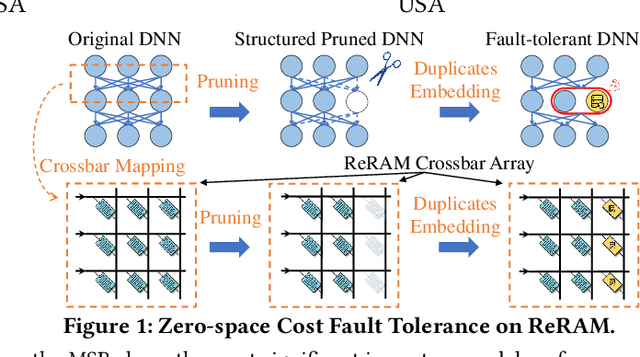

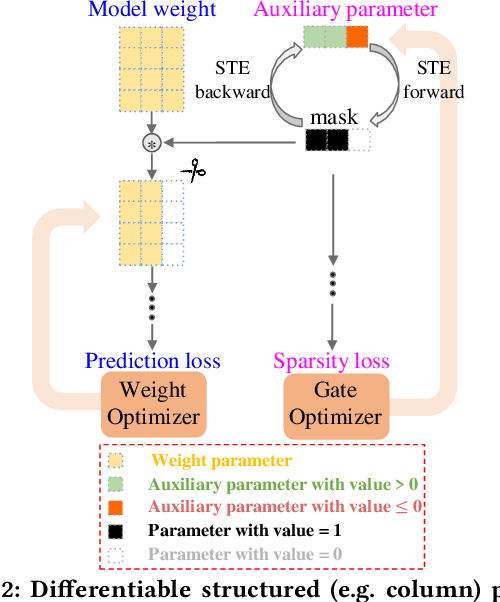

Resistive Random Access Memory (ReRAM) has emerged as a promising platform for deep neural networks (DNNs) due to its support for parallel in-situ matrix-vector multiplication. However, hardware failures, such as stuck-at-fault defects, can result in significant prediction errors during model inference. While additional crossbars can be used to address these failures, they come with storage overhead and are not efficient in terms of space, energy, and cost. In this paper, we propose a fault protection mechanism that incurs zero space cost. Our approach includes: 1) differentiable structure pruning of rows and columns to reduce model redundancy, 2) weight duplication and voting for robust output, and 3) embedding duplicated most significant bits (MSBs) into the model weight. We evaluate our method on nine tasks of the GLUE benchmark with the BERT model, and experimental results prove its effectiveness.
MaxK-GNN: Towards Theoretical Speed Limits for Accelerating Graph Neural Networks Training
Dec 18, 2023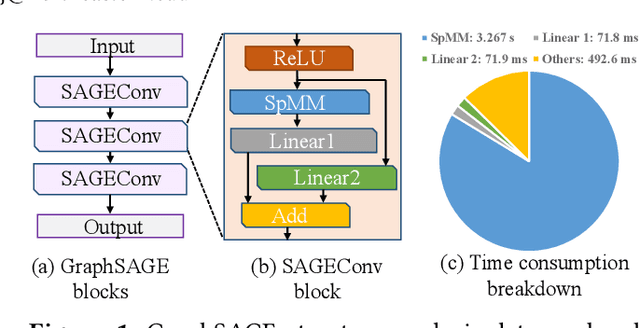

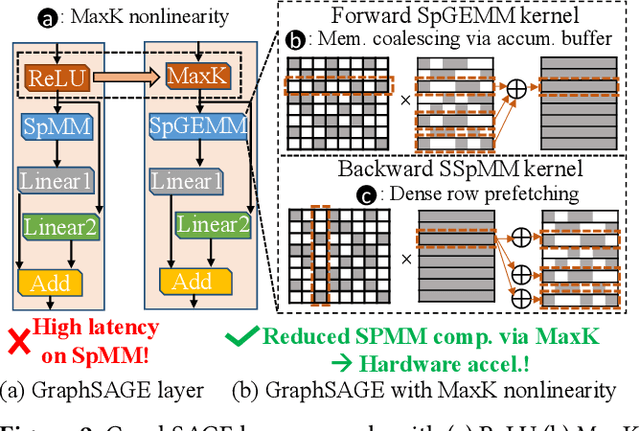
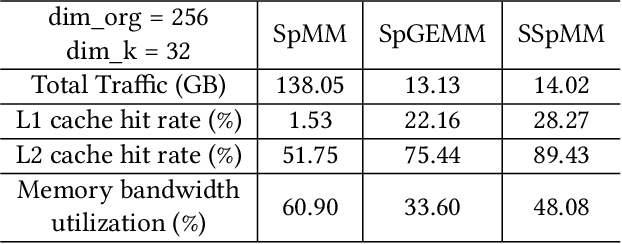
In the acceleration of deep neural network training, the GPU has become the mainstream platform. GPUs face substantial challenges on GNNs, such as workload imbalance and memory access irregularities, leading to underutilized hardware. Existing solutions such as PyG, DGL with cuSPARSE, and GNNAdvisor frameworks partially address these challenges but memory traffic is still significant. We argue that drastic performance improvements can only be achieved by the vertical optimization of algorithm and system innovations, rather than treating the speedup optimization as an "after-thought" (i.e., (i) given a GNN algorithm, designing an accelerator, or (ii) given hardware, mainly optimizing the GNN algorithm). In this paper, we present MaxK-GNN, an advanced high-performance GPU training system integrating algorithm and system innovation. (i) We introduce the MaxK nonlinearity and provide a theoretical analysis of MaxK nonlinearity as a universal approximator, and present the Compressed Balanced Sparse Row (CBSR) format, designed to store the data and index of the feature matrix after nonlinearity; (ii) We design a coalescing enhanced forward computation with row-wise product-based SpGEMM Kernel using CBSR for input feature matrix fetching and strategic placement of a sparse output accumulation buffer in shared memory; (iii) We develop an optimized backward computation with outer product-based and SSpMM Kernel. We conduct extensive evaluations of MaxK-GNN and report the end-to-end system run-time. Experiments show that MaxK-GNN system could approach the theoretical speedup limit according to Amdahl's law. We achieve comparable accuracy to SOTA GNNs, but at a significantly increased speed: 3.22/4.24 times speedup (vs. theoretical limits, 5.52/7.27 times) on Reddit compared to DGL and GNNAdvisor implementations.
LinGCN: Structural Linearized Graph Convolutional Network for Homomorphically Encrypted Inference
Sep 30, 2023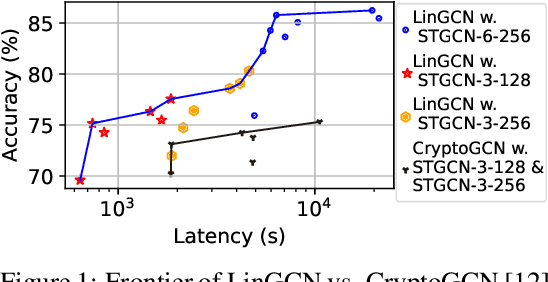

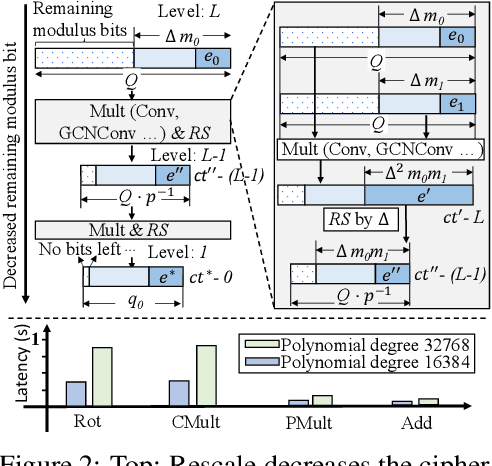
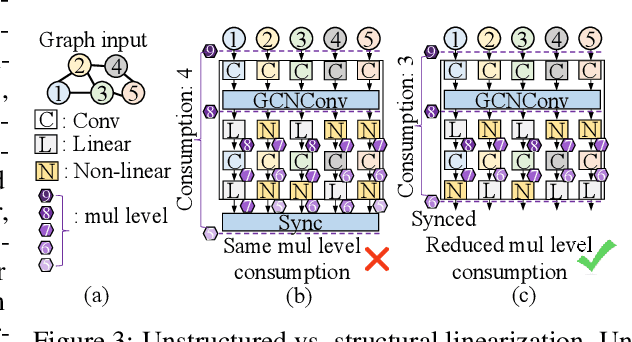
The growth of Graph Convolution Network (GCN) model sizes has revolutionized numerous applications, surpassing human performance in areas such as personal healthcare and financial systems. The deployment of GCNs in the cloud raises privacy concerns due to potential adversarial attacks on client data. To address security concerns, Privacy-Preserving Machine Learning (PPML) using Homomorphic Encryption (HE) secures sensitive client data. However, it introduces substantial computational overhead in practical applications. To tackle those challenges, we present LinGCN, a framework designed to reduce multiplication depth and optimize the performance of HE based GCN inference. LinGCN is structured around three key elements: (1) A differentiable structural linearization algorithm, complemented by a parameterized discrete indicator function, co-trained with model weights to meet the optimization goal. This strategy promotes fine-grained node-level non-linear location selection, resulting in a model with minimized multiplication depth. (2) A compact node-wise polynomial replacement policy with a second-order trainable activation function, steered towards superior convergence by a two-level distillation approach from an all-ReLU based teacher model. (3) an enhanced HE solution that enables finer-grained operator fusion for node-wise activation functions, further reducing multiplication level consumption in HE-based inference. Our experiments on the NTU-XVIEW skeleton joint dataset reveal that LinGCN excels in latency, accuracy, and scalability for homomorphically encrypted inference, outperforming solutions such as CryptoGCN. Remarkably, LinGCN achieves a 14.2x latency speedup relative to CryptoGCN, while preserving an inference accuracy of 75% and notably reducing multiplication depth.