 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-Powered Evolutionary Code Optimization on a Phylogenetic Tree
Jan 20, 2026Optimizing scientific computing algorithms for modern GPUs is a labor-intensive and iterative process involving repeated code modification, benchmarking, and tuning across complex hardware and software stacks. Recent work has explored large language model (LLM)-assisted evolutionary methods for automated code optimization, but these approaches primarily rely on outcome-based selection and random mutation, underutilizing the rich trajectory information generated during iterative optimization. We propose PhyloEvolve, an LLM-agent system that reframes GPU-oriented algorithm optimization as an In-Context Reinforcement Learning (ICRL) problem. This formulation enables trajectory-conditioned reuse of optimization experience without model retraining. PhyloEvolve integrates Algorithm Distillation and prompt-based Decision Transformers into an iterative workflow, treating sequences of algorithm modifications and performance feedback as first-class learning signals. To organize optimization history, we introduce a phylogenetic tree representation that captures inheritance, divergence, and recombination among algorithm variants, enabling backtracking, cross-lineage transfer, and reproducibility. The system combines elite trajectory pooling, multi-island parallel exploration, and containerized execution to balance exploration and exploitation across heterogeneous hardware. We evaluate PhyloEvolve on scientific computing workloads including PDE solvers, manifold learning, and spectral graph algorithms, demonstrating consistent improvements in runtime, memory efficiency, and correctness over baseline and evolutionary methods. Code is published at: https://github.com/annihi1ation/phylo_evolve
Differentially Private Learned Indexes
Oct 28, 2024


In this paper, we address the problem of efficiently answering predicate queries on encrypted databases, those secured by Trusted Execution Environments (TEEs), which enable untrusted providers to process encrypted user data without revealing its contents. A common strategy in modern databases to accelerate predicate queries is the use of indexes, which map attribute values (keys) to their corresponding positions in a sorted data array. This allows for fast lookup and retrieval of data subsets that satisfy specific predicates. Unfortunately, indexes cannot be directly applied to encrypted databases due to strong data dependent leakages. Recent approaches apply differential privacy (DP) to construct noisy indexes that enable faster access to encrypted data while maintaining provable privacy guarantees. However, these methods often suffer from large storage costs, with index sizes typically scaling linearly with the key space. To address this challenge, we propose leveraging learned indexes, a trending technique that repurposes machine learning models as indexing structures, to build more compact DP indexes.
SSNet: A Lightweight Multi-Party Computation Scheme for Practical Privacy-Preserving Machine Learning Service in the Cloud
Jun 04, 2024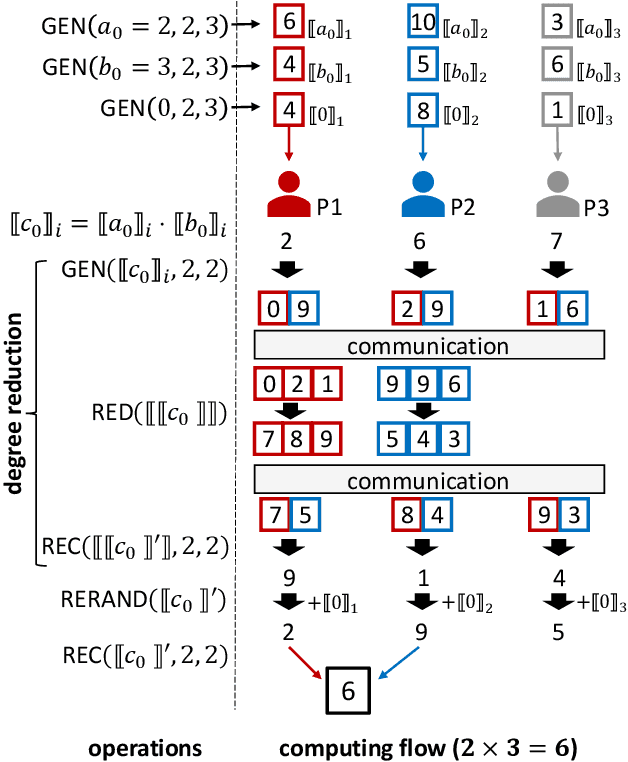
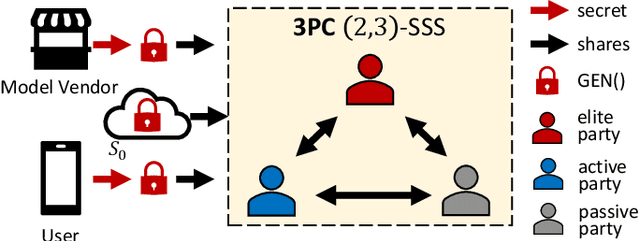
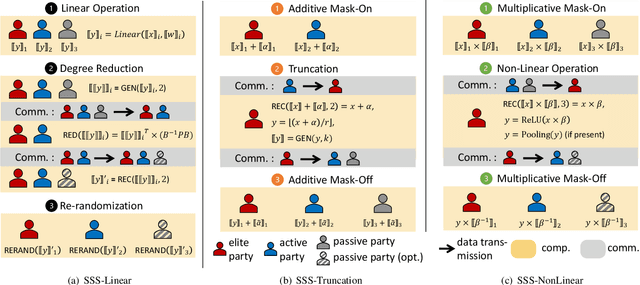
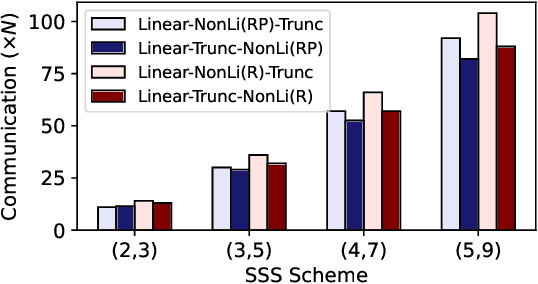
As privacy-preserving becomes a pivotal aspect of deep learning (DL) development, multi-party computation (MPC) has gained prominence for its efficiency and strong security. However, the practice of current MPC frameworks is limited, especially when dealing with large neural networks, exemplified by the prolonged execution time of 25.8 seconds for secure inference on ResNet-152. The primary challenge lies in the reliance of current MPC approaches on additive secret sharing, which incurs significant communication overhead with non-linear operations such as comparisons. Furthermore, additive sharing suffers from poor scalability on party size. In contrast, the evolving landscape of MPC necessitates accommodating a larger number of compute parties and ensuring robust performance against malicious activities or computational failures. In light of these challenges, we propose SSNet, which for the first time, employs Shamir's secret sharing (SSS) as the backbone of MPC-based ML framework. We meticulously develop all framework primitives and operations for secure DL models tailored to seamlessly integrate with the SSS scheme. SSNet demonstrates the ability to scale up party numbers straightforwardly and embeds strategies to authenticate the computation correctness without incurring significant performance overhead. Additionally, SSNet introduces masking strategies designed to reduce communication overhead associated with non-linear operations. We conduct comprehensive experimental evaluations on commercial cloud computing infrastructure from Amazon AWS, as well as across diverse prevalent DNN models and datasets. SSNet demonstrates a substantial performance boost, achieving speed-ups ranging from 3x to 14x compared to SOTA MPC frameworks. Moreover, SSNet also represents the first framework that is evaluated on a five-party computation setup, in the context of secure DL inference.
LinGCN: Structural Linearized Graph Convolutional Network for Homomorphically Encrypted Inference
Sep 30, 2023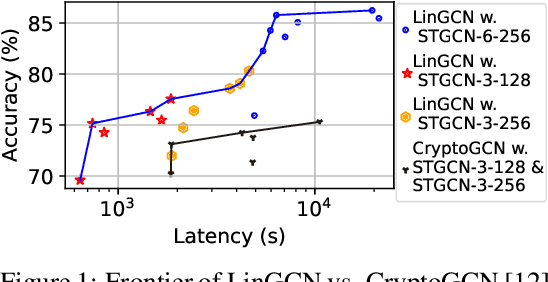

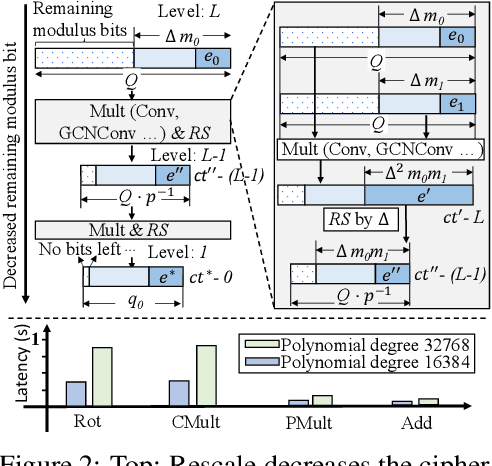
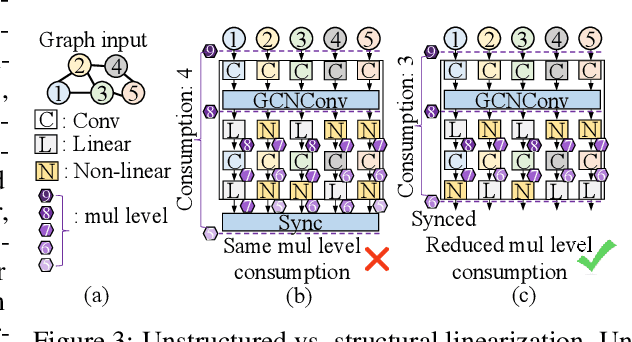
The growth of Graph Convolution Network (GCN) model sizes has revolutionized numerous applications, surpassing human performance in areas such as personal healthcare and financial systems. The deployment of GCNs in the cloud raises privacy concerns due to potential adversarial attacks on client data. To address security concerns, Privacy-Preserving Machine Learning (PPML) using Homomorphic Encryption (HE) secures sensitive client data. However, it introduces substantial computational overhead in practical applications. To tackle those challenges, we present LinGCN, a framework designed to reduce multiplication depth and optimize the performance of HE based GCN inference. LinGCN is structured around three key elements: (1) A differentiable structural linearization algorithm, complemented by a parameterized discrete indicator function, co-trained with model weights to meet the optimization goal. This strategy promotes fine-grained node-level non-linear location selection, resulting in a model with minimized multiplication depth. (2) A compact node-wise polynomial replacement policy with a second-order trainable activation function, steered towards superior convergence by a two-level distillation approach from an all-ReLU based teacher model. (3) an enhanced HE solution that enables finer-grained operator fusion for node-wise activation functions, further reducing multiplication level consumption in HE-based inference. Our experiments on the NTU-XVIEW skeleton joint dataset reveal that LinGCN excels in latency, accuracy, and scalability for homomorphically encrypted inference, outperforming solutions such as CryptoGCN. Remarkably, LinGCN achieves a 14.2x latency speedup relative to CryptoGCN, while preserving an inference accuracy of 75% and notably reducing multiplication depth.
AutoReP: Automatic ReLU Replacement for Fast Private Network Inference
Aug 20, 2023



The growth of the Machine-Learning-As-A-Service (MLaaS) market has highlighted clients' data privacy and security issues. Private inference (PI) techniques using cryptographic primitives offer a solution but often have high computation and communication costs, particularly with non-linear operators like ReLU. Many attempts to reduce ReLU operations exist, but they may need heuristic threshold selection or cause substantial accuracy loss. This work introduces AutoReP, a gradient-based approach to lessen non-linear operators and alleviate these issues. It automates the selection of ReLU and polynomial functions to speed up PI applications and introduces distribution-aware polynomial approximation (DaPa) to maintain model expressivity while accurately approximating ReLUs. Our experimental results demonstrate significant accuracy improvements of 6.12% (94.31%, 12.9K ReLU budget, CIFAR-10), 8.39% (74.92%, 12.9K ReLU budget, CIFAR-100), and 9.45% (63.69%, 55K ReLU budget, Tiny-ImageNet) over current state-of-the-art methods, e.g., SNL. Morever, AutoReP is applied to EfficientNet-B2 on ImageNet dataset, and achieved 75.55% accuracy with 176.1 times ReLU budget reduction.
RRNet: Towards ReLU-Reduced Neural Network for Two-party Computation Based Private Inference
Feb 22, 2023



The proliferation of deep learning (DL) has led to the emergence of privacy and security concerns. To address these issues, secure Two-party computation (2PC) has been proposed as a means of enabling privacy-preserving DL computation. However, in practice, 2PC methods often incur high computation and communication overhead, which can impede their use in large-scale systems. To address this challenge, we introduce RRNet, a systematic framework that aims to jointly reduce the overhead of MPC comparison protocols and accelerate computation through hardware acceleration. Our approach integrates the hardware latency of cryptographic building blocks into the DNN loss function, resulting in improved energy efficiency, accuracy, and security guarantees. Furthermore, we propose a cryptographic hardware scheduler and corresponding performance model for Field Programmable Gate Arrays (FPGAs) to further enhance the efficiency of our framework. Experiments show RRNet achieved a much higher ReLU reduction performance than all SOTA works on CIFAR-10 dataset.
PolyMPCNet: Towards ReLU-free Neural Architecture Search in Two-party Computation Based Private Inference
Sep 20, 2022
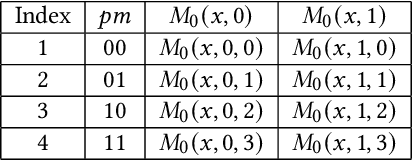
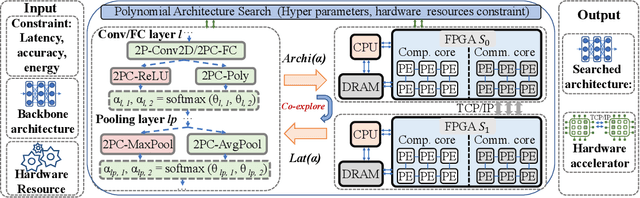
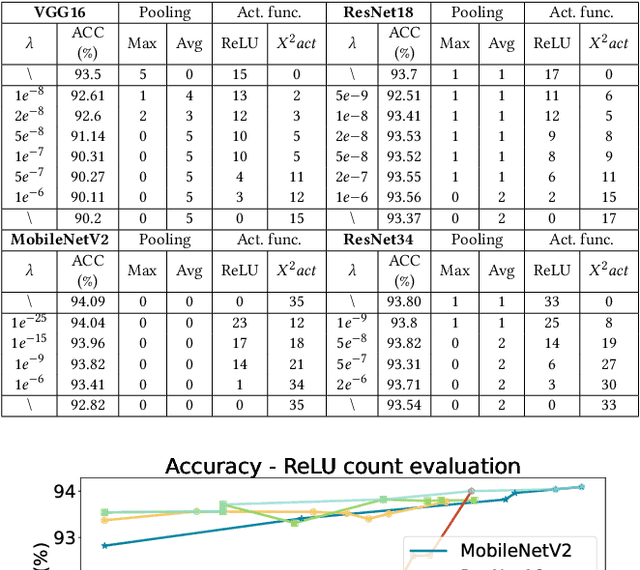
The rapid growth and deployment of deep learning (DL) has witnessed emerging privacy and security concerns. To mitigate these issues, secure multi-party computation (MPC) has been discussed, to enable the privacy-preserving DL computation. In practice, they often come at very high computation and communication overhead, and potentially prohibit their popularity in large scale systems. Two orthogonal research trends have attracted enormous interests in addressing the energy efficiency in secure deep learning, i.e., overhead reduction of MPC comparison protocol, and hardware acceleration. However, they either achieve a low reduction ratio and suffer from high latency due to limited computation and communication saving, or are power-hungry as existing works mainly focus on general computing platforms such as CPUs and GPUs. In this work, as the first attempt, we develop a systematic framework, PolyMPCNet, of joint overhead reduction of MPC comparison protocol and hardware acceleration, by integrating hardware latency of the cryptographic building block into the DNN loss function to achieve high energy efficiency, accuracy, and security guarantee. Instead of heuristically checking the model sensitivity after a DNN is well-trained (through deleting or dropping some non-polynomial operators), our key design principle is to em enforce exactly what is assumed in the DNN design -- training a DNN that is both hardware efficient and secure, while escaping the local minima and saddle points and maintaining high accuracy. More specifically, we propose a straight through polynomial activation initialization method for cryptographic hardware friendly trainable polynomial activation function to replace the expensive 2P-ReLU operator. We develop a cryptographic hardware scheduler and the corresponding performance model for Field Programmable Gate Arrays (FPGA) platform.
A Secure and Efficient Federated Learning Framework for NLP
Jan 28, 2022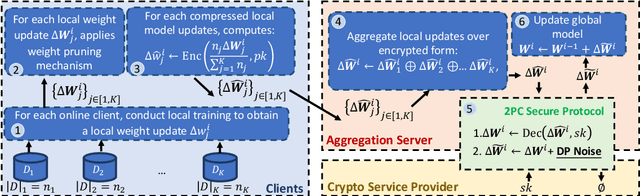
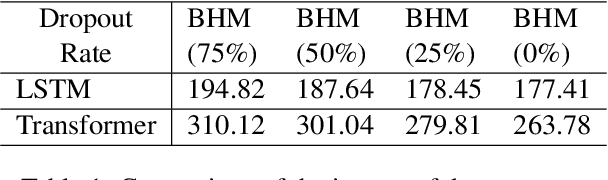
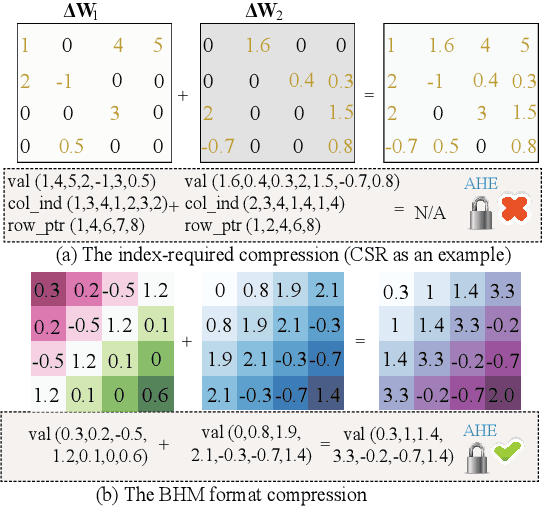
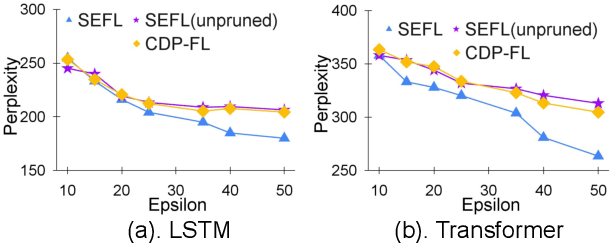
In this work, we consider the problem of designing secure and efficient federated learning (FL) frameworks. Existing solutions either involve a trusted aggregator or require heavyweight cryptographic primitives, which degrades performance significantly. Moreover, many existing secure FL designs work only under the restrictive assumption that none of the clients can be dropped out from the training protocol. To tackle these problems, we propose SEFL, a secure and efficient FL framework that (1) eliminates the need for the trusted entities; (2) achieves similar and even better model accuracy compared with existing FL designs; (3) is resilient to client dropouts. Through extensive experimental studies on natural language processing (NLP) tasks, we demonstrate that the SEFL achieves comparable accuracy compared to existing FL solutions, and the proposed pruning technique can improve runtime performance up to 13.7x.
SAPAG: A Self-Adaptive Privacy Attack From Gradients
Sep 14, 2020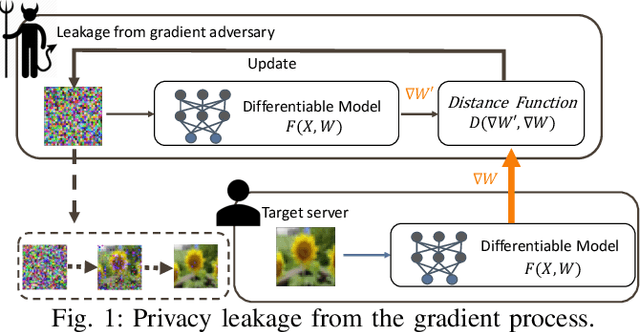

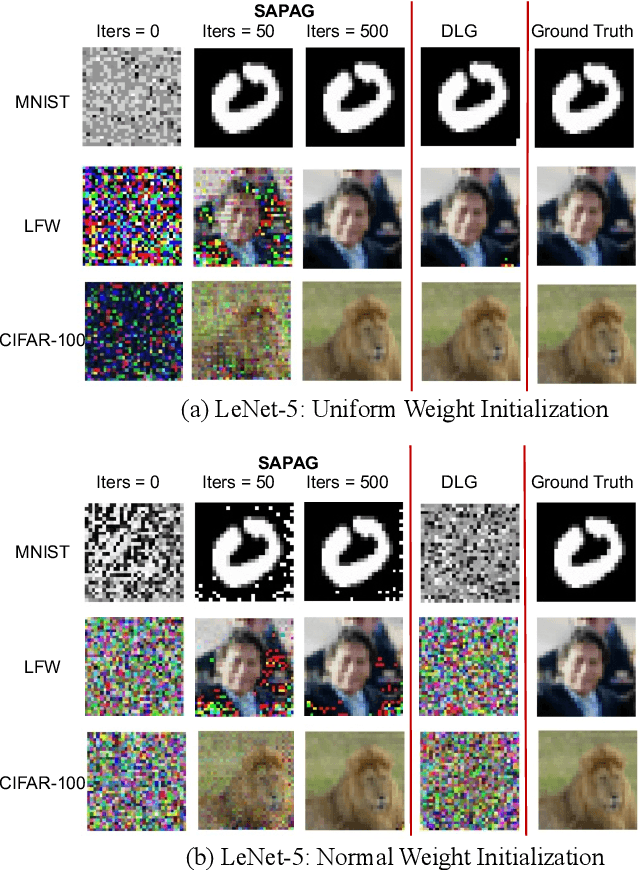
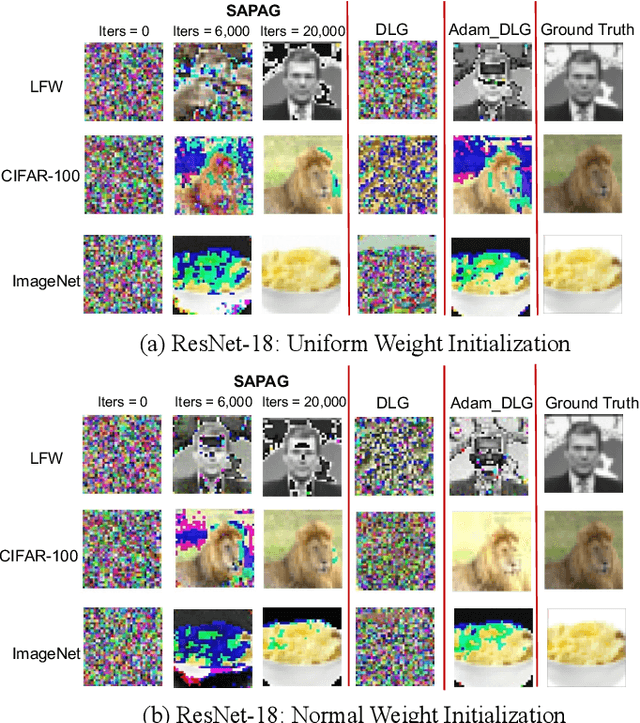
Distributed learning such as federated learning or collaborative learning enables model training on decentralized data from users and only collects local gradients, where data is processed close to its sources for data privacy. The nature of not centralizing the training data addresses the privacy issue of privacy-sensitive data. Recent studies show that a third party can reconstruct the true training data in the distributed machine learning system through the publicly-shared gradients. However, existing reconstruction attack frameworks lack generalizability on different Deep Neural Network (DNN) architectures and different weight distribution initialization, and can only succeed in the early training phase. To address these limitations, in this paper, we propose a more general privacy attack from gradient, SAPAG, which uses a Gaussian kernel based of gradient difference as a distance measure. Our experiments demonstrate that SAPAG can construct the training data on different DNNs with different weight initializations and on DNNs in any training phases.
ESMFL: Efficient and Secure Models for Federated Learning
Sep 03, 2020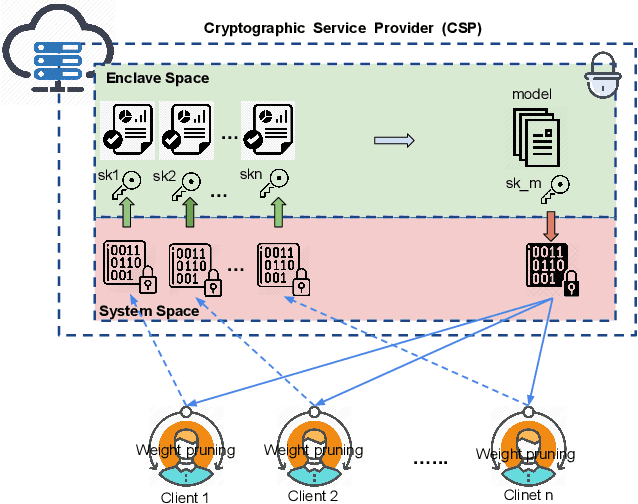
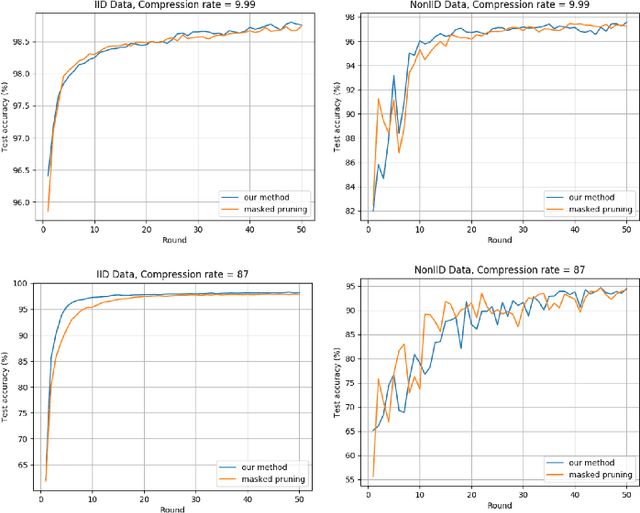
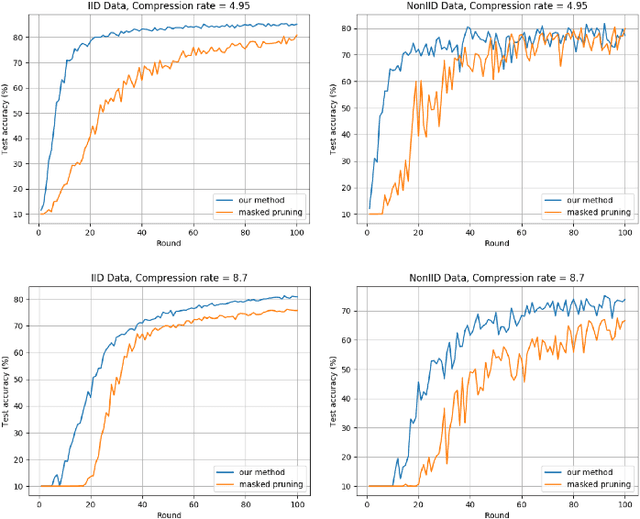
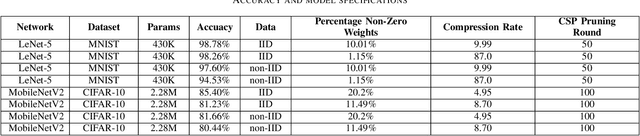
Deep Neural Networks are widely applied to various domains. The successful deployment of these applications is everywhere and it depends on the availability of big data. However, massive data collection required for deep neural network reveals the potential privacy issues and also consumes large mounts of communication bandwidth. To address this problem, we propose a privacy-preserving method for the federated learning distributed system, operated on Intel Software Guard Extensions, a set of instructions that increases the security of application code and data. Meanwhile, the encrypted models make the transmission overhead larger. Hence, we reduce the commutation cost by sparsification and achieve reasonable accuracy with different model architectures. Experimental results under our privacy-preserving framework show that, for LeNet-5, we obtain 98.78% accuracy on IID data and 97.60% accuracy on Non-IID data with 34.85% communication saving, and 1.8X total elapsed time acceleration. For MobileNetV2, we obtain 85.40% accuracy on IID data and 81.66% accuracy on Non-IID data with 15.85% communication saving, and 1.2X total elapsed time acceleration.