 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyMPCNet: Towards ReLU-free Neural Architecture Search in Two-party Computation Based Private Inference
Paper and Code
Sep 20, 2022
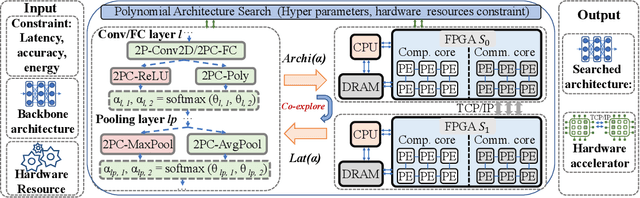
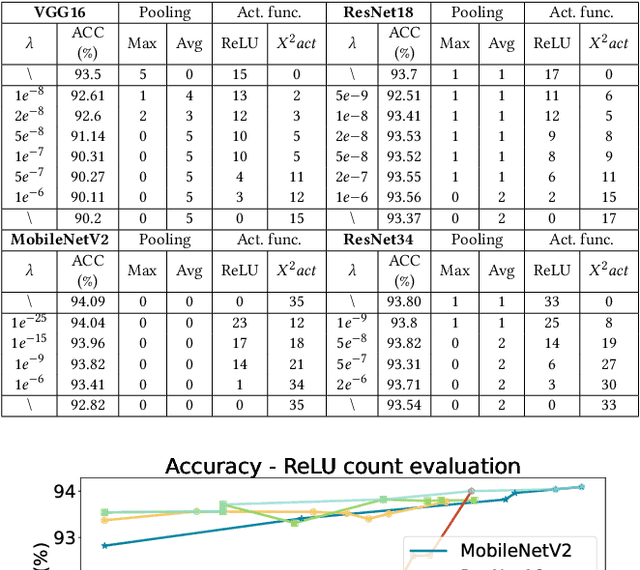
The rapid growth and deployment of deep learning (DL) has witnessed emerging privacy and security concerns. To mitigate these issues, secure multi-party computation (MPC) has been discussed, to enable the privacy-preserving DL computation. In practice, they often come at very high computation and communication overhead, and potentially prohibit their popularity in large scale systems. Two orthogonal research trends have attracted enormous interests in addressing the energy efficiency in secure deep learning, i.e., overhead reduction of MPC comparison protocol, and hardware acceleration. However, they either achieve a low reduction ratio and suffer from high latency due to limited computation and communication saving, or are power-hungry as existing works mainly focus on general computing platforms such as CPUs and GPUs. In this work, as the first attempt, we develop a systematic framework, PolyMPCNet, of joint overhead reduction of MPC comparison protocol and hardware acceleration, by integrating hardware latency of the cryptographic building block into the DNN loss function to achieve high energy efficiency, accuracy, and security guarantee. Instead of heuristically checking the model sensitivity after a DNN is well-trained (through deleting or dropping some non-polynomial operators), our key design principle is to em enforce exactly what is assumed in the DNN design -- training a DNN that is both hardware efficient and secure, while escaping the local minima and saddle points and maintaining high accuracy. More specifically, we propose a straight through polynomial activation initialization method for cryptographic hardware friendly trainable polynomial activation function to replace the expensive 2P-ReLU operator. We develop a cryptographic hardware scheduler and the corresponding performance model for Field Programmable Gate Arrays (FPGA) platform.