 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Lagrangian Relaxation: A Path To Retrain-free Deep Neural Network Pruning
Apr 08, 2023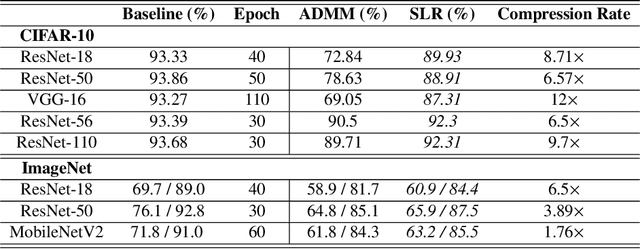
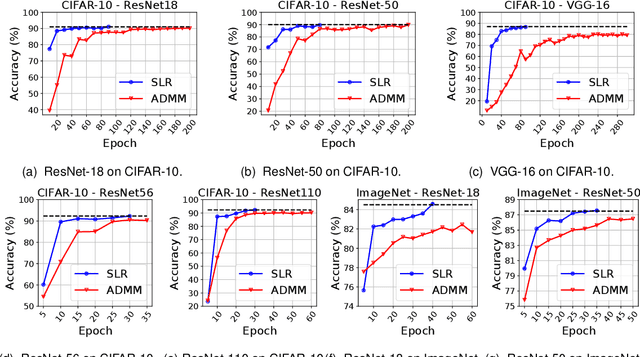
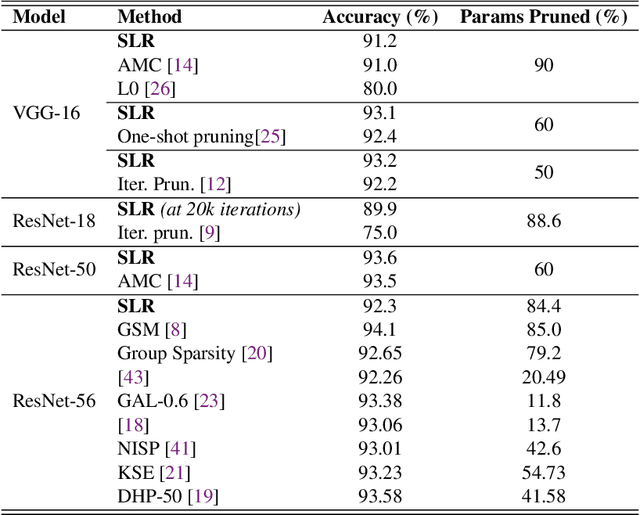
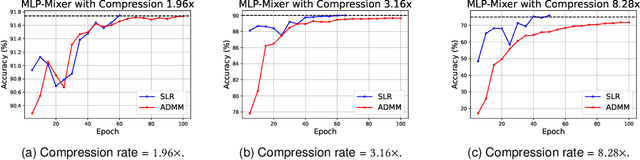
Network pruning is a widely used technique to reduce computation cost and model size for deep neural networks. However, the typical three-stage pipeline significantly increases the overall training time. In this paper, we develop a systematic weight-pruning optimization approach based on Surrogate Lagrangian relaxation, which is tailored to overcome difficulties caused by the discrete nature of the weight-pruning problem. We prove that our method ensures fast convergence of the model compression problem, and the convergence of the SLR is accelerated by using quadratic penalties. Model parameters obtained by SLR during the training phase are much closer to their optimal values as compared to those obtained by other state-of-the-art methods. We evaluate our method on image classification tasks using CIFAR-10 and ImageNet with state-of-the-art MLP-Mixer, Swin Transformer, and VGG-16, ResNet-18, ResNet-50 and ResNet-110, MobileNetV2. We also evaluate object detection and segmentation tasks on COCO, KITTI benchmark, and TuSimple lane detection dataset using a variety of models. Experimental results demonstrate that our SLR-based weight-pruning optimization approach achieves a higher compression rate than state-of-the-art methods under the same accuracy requirement and also can achieve higher accuracy under the same compression rate requirement. Under classification tasks, our SLR approach converges to the desired accuracy $3\times$ faster on both of the datasets. Under object detection and segmentation tasks, SLR also converges $2\times$ faster to the desired accuracy. Further, our SLR achieves high model accuracy even at the hard-pruning stage without retraining, which reduces the traditional three-stage pruning into a two-stage process. Given a limited budget of retraining epochs, our approach quickly recovers the model's accuracy.
Physics-aware Roughness Optimization for Diffractive Optical Neural Networks
Apr 04, 2023As a representative next-generation device/circuit technology beyond CMOS, diffractive optical neural networks (DONNs) have shown promising advantages over conventional deep neural networks due to extreme fast computation speed (light speed) and low energy consumption. However, there is a mismatch, i.e., significant prediction accuracy loss, between the DONN numerical modelling and physical optical device deployment, because of the interpixel interaction within the diffractive layers. In this work, we propose a physics-aware diffractive optical neural network training framework to reduce the performance difference between numerical modeling and practical deployment. Specifically, we propose the roughness modeling regularization in the training process and integrate the physics-aware sparsification method to introduce sparsity to the phase masks to reduce sharp phase changes between adjacent pixels in diffractive layers. We further develop $2\pi$ periodic optimization to reduce the roughness of the phase masks to preserve the performance of DONN. Experiment results demonstrate that, compared to state-of-the-arts, our physics-aware optimization can provide $35.7\%$, $34.2\%$, $28.1\%$, and $27.3\%$ reduction in roughness with only accuracy loss on MNIST, FMNIST, KMNIST, and EMNIST, respectively.
RRNet: Towards ReLU-Reduced Neural Network for Two-party Computation Based Private Inference
Feb 22, 2023



The proliferation of deep learning (DL) has led to the emergence of privacy and security concerns. To address these issues, secure Two-party computation (2PC) has been proposed as a means of enabling privacy-preserving DL computation. However, in practice, 2PC methods often incur high computation and communication overhead, which can impede their use in large-scale systems. To address this challenge, we introduce RRNet, a systematic framework that aims to jointly reduce the overhead of MPC comparison protocols and accelerate computation through hardware acceleration. Our approach integrates the hardware latency of cryptographic building blocks into the DNN loss function, resulting in improved energy efficiency, accuracy, and security guarantees. Furthermore, we propose a cryptographic hardware scheduler and corresponding performance model for Field Programmable Gate Arrays (FPGAs) to further enhance the efficiency of our framework. Experiments show RRNet achieved a much higher ReLU reduction performance than all SOTA works on CIFAR-10 dataset.
Shared Information-Based Safe And Efficient Behavior Planning For Connected Autonomous Vehicles
Feb 15, 2023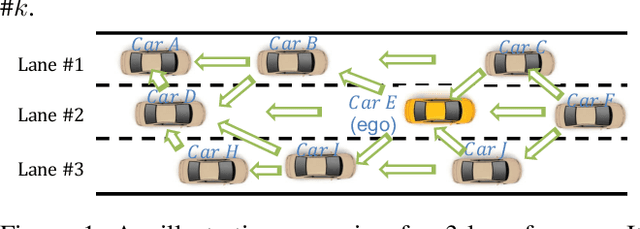

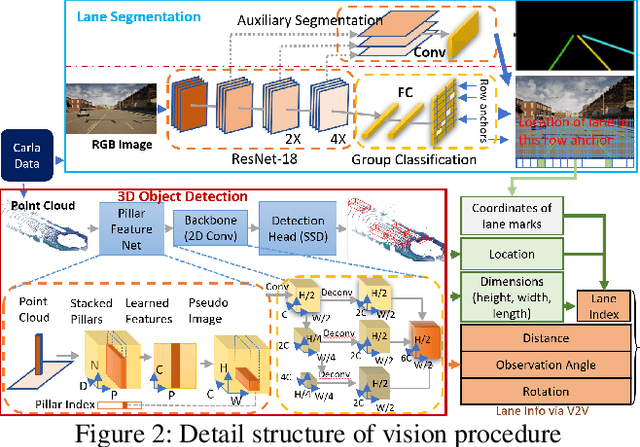
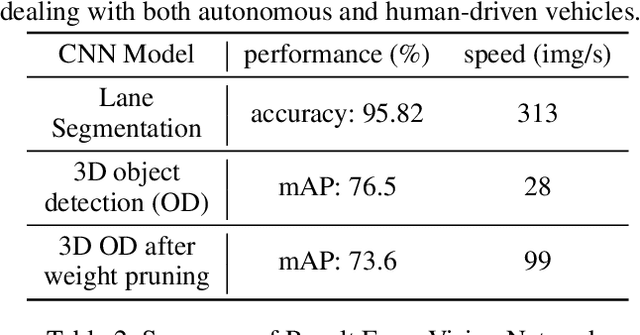
The recent advancements in wireless technology enable connected autonomous vehicles (CAVs) to gather data via vehicle-to-vehicle (V2V) communication, such as processed LIDAR and camera data from other vehicles. In this work, we design an integrated information sharing and safe multi-agent reinforcement learning (MARL) framework for CAVs, to take advantage of the extra information when making decisions to improve traffic efficiency and safety. We first use weight pruned convolutional neural networks (CNN) to process the raw image and point cloud LIDAR data locally at each autonomous vehicle, and share CNN-output data with neighboring CAVs. We then design a safe actor-critic algorithm that utilizes both a vehicle's local observation and the information received via V2V communication to explore an efficient behavior planning policy with safety guarantees. Using the CARLA simulator for experiments, we show that our approach improves the CAV system's efficiency in terms of average velocity and comfort under different CAV ratios and different traffic densities. We also show that our approach avoids the execution of unsafe actions and always maintains a safe distance from other vehicles. We construct an obstacle-at-corner scenario to show that the shared vision can help CAVs to observe obstacles earlier and take action to avoid traffic jams.
PolyMPCNet: Towards ReLU-free Neural Architecture Search in Two-party Computation Based Private Inference
Sep 20, 2022
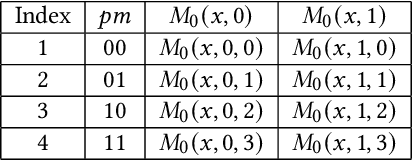
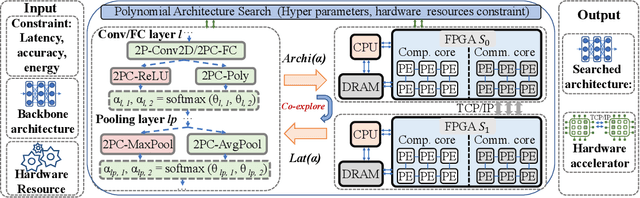
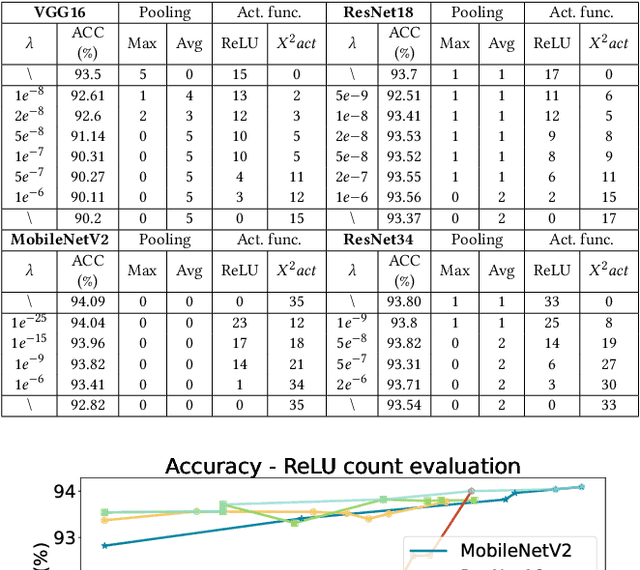
The rapid growth and deployment of deep learning (DL) has witnessed emerging privacy and security concerns. To mitigate these issues, secure multi-party computation (MPC) has been discussed, to enable the privacy-preserving DL computation. In practice, they often come at very high computation and communication overhead, and potentially prohibit their popularity in large scale systems. Two orthogonal research trends have attracted enormous interests in addressing the energy efficiency in secure deep learning, i.e., overhead reduction of MPC comparison protocol, and hardware acceleration. However, they either achieve a low reduction ratio and suffer from high latency due to limited computation and communication saving, or are power-hungry as existing works mainly focus on general computing platforms such as CPUs and GPUs. In this work, as the first attempt, we develop a systematic framework, PolyMPCNet, of joint overhead reduction of MPC comparison protocol and hardware acceleration, by integrating hardware latency of the cryptographic building block into the DNN loss function to achieve high energy efficiency, accuracy, and security guarantee. Instead of heuristically checking the model sensitivity after a DNN is well-trained (through deleting or dropping some non-polynomial operators), our key design principle is to em enforce exactly what is assumed in the DNN design -- training a DNN that is both hardware efficient and secure, while escaping the local minima and saddle points and maintaining high accuracy. More specifically, we propose a straight through polynomial activation initialization method for cryptographic hardware friendly trainable polynomial activation function to replace the expensive 2P-ReLU operator. We develop a cryptographic hardware scheduler and the corresponding performance model for Field Programmable Gate Arrays (FPGA) platform.
EVE: Environmental Adaptive Neural Network Models for Low-power Energy Harvesting System
Jul 14, 2022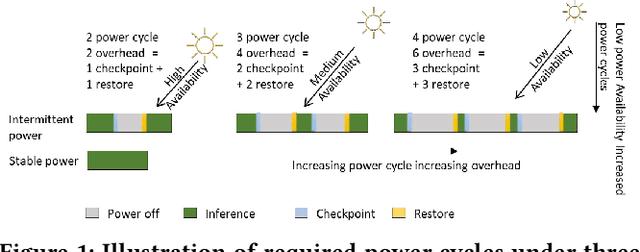
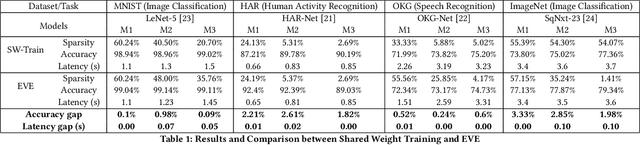
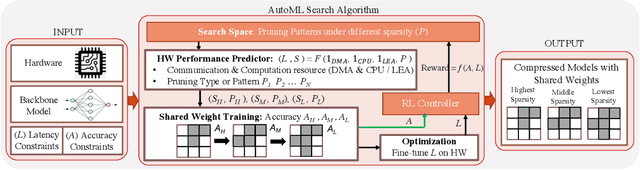
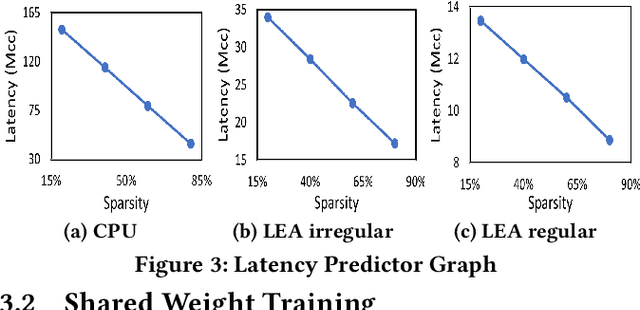
IoT devices are increasingly being implemented with neural network models to enable smart applications. Energy harvesting (EH) technology that harvests energy from ambient environment is a promising alternative to batteries for powering those devices due to the low maintenance cost and wide availability of the energy sources. However, the power provided by the energy harvester is low and has an intrinsic drawback of instability since it varies with the ambient environment. This paper proposes EVE, an automated machine learning (autoML) co-exploration framework to search for desired multi-models with shared weights for energy harvesting IoT devices. Those shared models incur significantly reduced memory footprint with different levels of model sparsity, latency, and accuracy to adapt to the environmental changes. An efficient on-device implementation architecture is further developed to efficiently execute each model on device. A run-time model extraction algorithm is proposed that retrieves individual model with negligible overhead when a specific model mode is triggered. Experimental results show that the neural networks models generated by EVE is on average 2.5X times faster than the baseline models without pruning and shared weights.
Enabling Super-Fast Deep Learning on Tiny Energy-Harvesting IoT Devices
Nov 28, 2021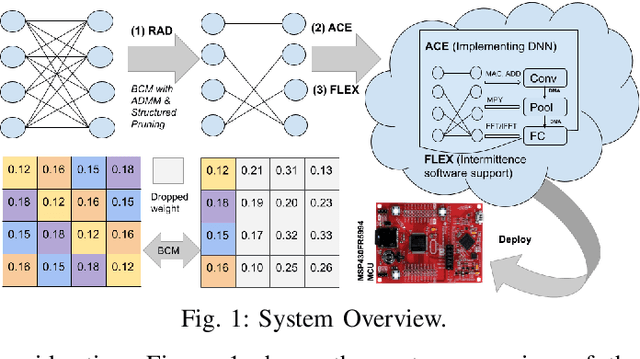
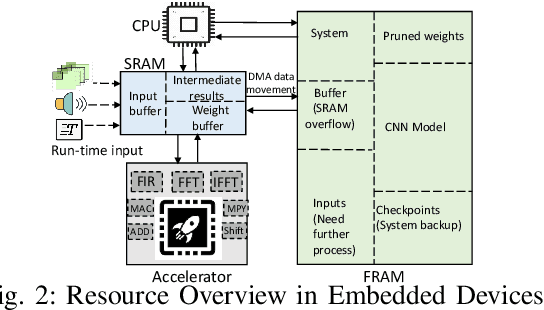
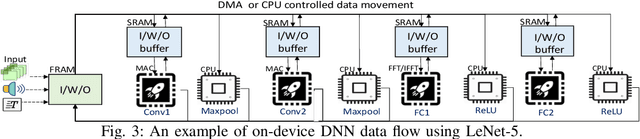
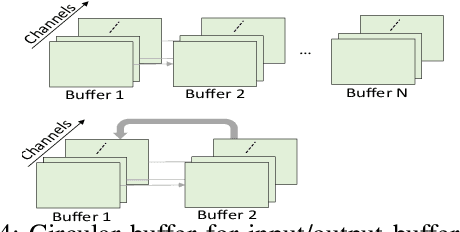
Energy harvesting (EH) IoT devices that operate intermittently without batteries, coupled with advances in deep neural networks (DNNs), have opened up new opportunities for enabling sustainable smart applications. Nevertheless, implementing those computation and memory-intensive intelligent algorithms on EH devices is extremely difficult due to the challenges of limited resources and intermittent power supply that causes frequent failures. To address those challenges, this paper proposes a methodology that enables super-fast deep learning with low-energy accelerators for tiny energy harvesting devices. We first propose RAD, a resource-aware structured DNN training framework, which employs block circulant matrix with ADMM to achieve high compression and model quantization for leveraging the advantage of various vector operation accelerators. A DNN implementation method, ACE, is then proposed that employs low-energy accelerators to profit maximum performance with minor energy consumption. Finally, we further design FLEX, the system support for intermittent computation in energy harvesting situations. Experimental results from three different DNN models demonstrate that RAD, ACE, and FLEX can enable super-fast and correct inference on energy harvesting devices with up to 4.26X runtime reduction, up to 7.7X energy reduction with higher accuracy over the state-of-the-art.
Exploration of Quantum Neural Architecture by Mixing Quantum Neuron Designs
Sep 08, 2021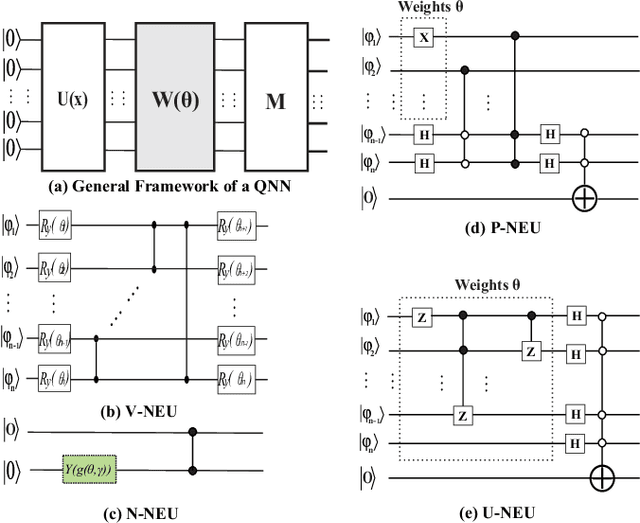

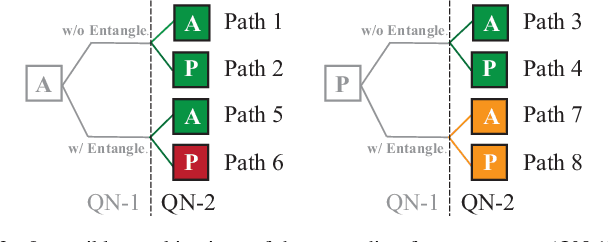
With the constant increase of the number of quantum bits (qubits) in the actual quantum computers, implementing and accelerating the prevalent deep learning on quantum computers are becoming possible. Along with this trend, there emerge quantum neural architectures based on different designs of quantum neurons. A fundamental question in quantum deep learning arises: what is the best quantum neural architecture? Inspired by the design of neural architectures for classical computing which typically employs multiple types of neurons, this paper makes the very first attempt to mix quantum neuron designs to build quantum neural architectures. We observe that the existing quantum neuron designs may be quite different but complementary, such as neurons from variation quantum circuits (VQC) and Quantumflow. More specifically, VQC can apply real-valued weights but suffer from being extended to multiple layers, while QuantumFlow can build a multi-layer network efficiently, but is limited to use binary weights. To take their respective advantages, we propose to mix them together and figure out a way to connect them seamlessly without additional costly measurement. We further investigate the design principles to mix quantum neurons, which can provide guidance for quantum neural architecture exploration in the future. Experimental results demonstrate that the identified quantum neural architectures with mixed quantum neurons can achieve 90.62% of accuracy on the MNIST dataset, compared with 52.77% and 69.92% on the VQC and QuantumFlow, respectively.
Binary Complex Neural Network Acceleration on FPGA
Aug 10, 2021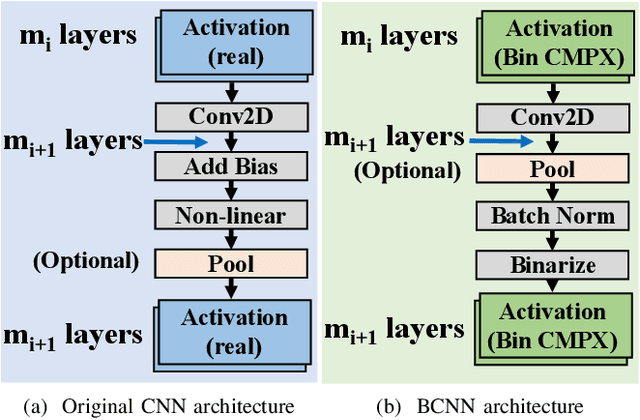
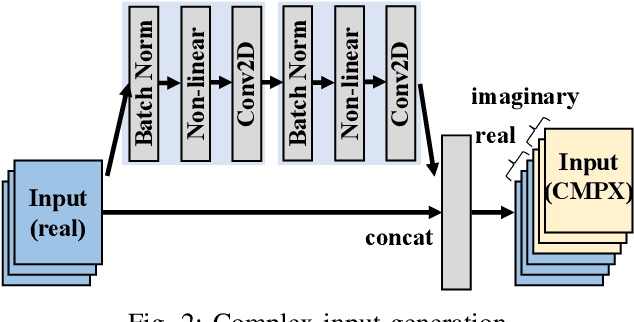

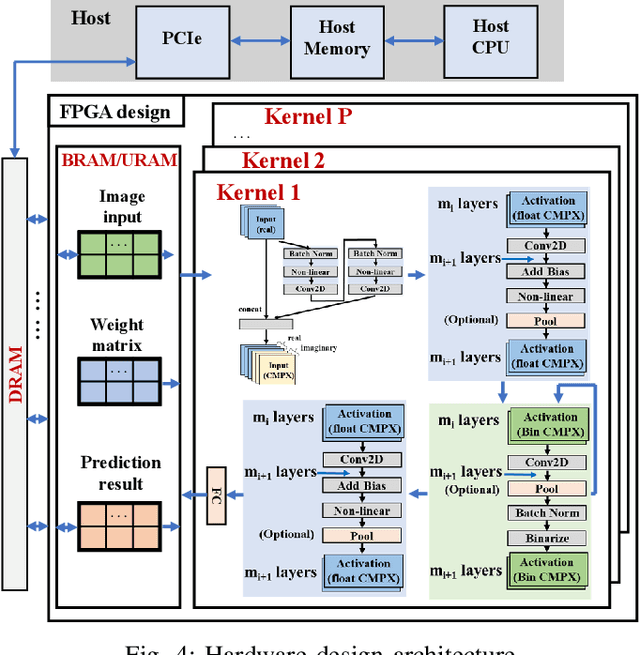
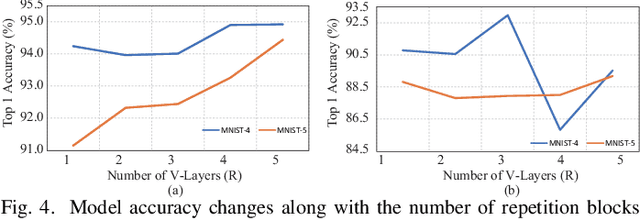
Being able to learn from complex data with phase information is imperative for many signal processing applications. Today' s real-valued deep neural networks (DNNs) have shown efficiency in latent information analysis but fall short when applied to the complex domain. Deep complex networks (DCN), in contrast, can learn from complex data, but have high computational costs; therefore, they cannot satisfy the instant decision-making requirements of many deployable systems dealing with short observations or short signal bursts. Recent, Binarized Complex Neural Network (BCNN), which integrates DCNs with binarized neural networks (BNN), shows great potential in classifying complex data in real-time. In this paper, we propose a structural pruning based accelerator of BCNN, which is able to provide more than 5000 frames/s inference throughput on edge devices. The high performance comes from both the algorithm and hardware sides. On the algorithm side, we conduct structural pruning to the original BCNN models and obtain 20 $\times$ pruning rates with negligible accuracy loss; on the hardware side, we propose a novel 2D convolution operation accelerator for the binary complex neural network. Experimental results show that the proposed design works with over 90% utilization and is able to achieve the inference throughput of 5882 frames/s and 4938 frames/s for complex NIN-Net and ResNet-18 using CIFAR-10 dataset and Alveo U280 Board.
A Surrogate Lagrangian Relaxation-based Model Compression for Deep Neural Networks
Dec 18, 2020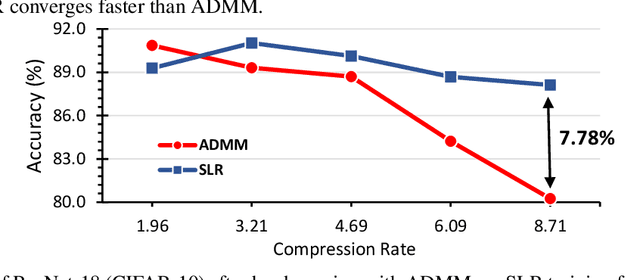
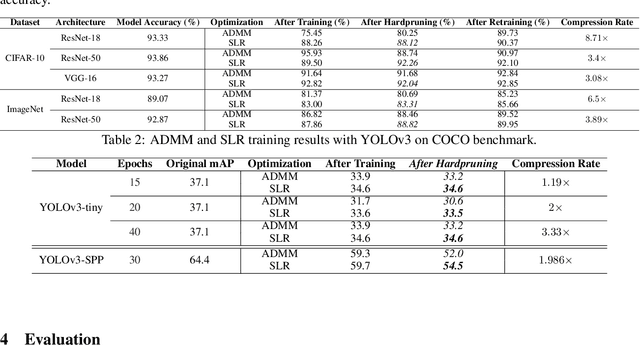
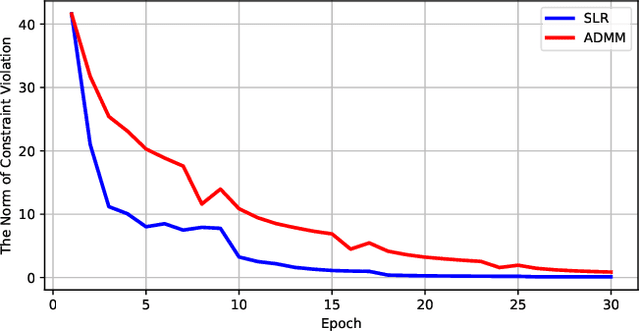
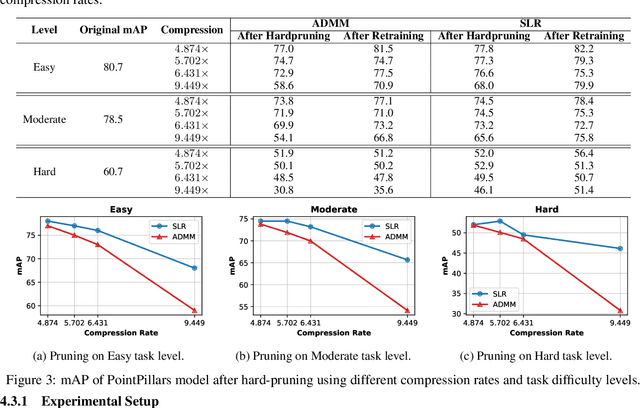
Network pruning is a widely used technique to reduce computation cost and model size for deep neural networks. However, the typical three-stage pipeline, i.e., training, pruning and retraining (fine-tuning) significantly increases the overall training trails. For instance, the retraining process could take up to 80 epochs for ResNet-18 on ImageNet, that is 70% of the original model training trails. In this paper, we develop a systematic weight-pruning optimization approach based on Surrogate Lagrangian relaxation (SLR), which is tailored to overcome difficulties caused by the discrete nature of the weight-pruning problem while ensuring fast convergence. We decompose the weight-pruning problem into subproblems, which are coordinated by updating Lagrangian multipliers. Convergence is then accelerated by using quadratic penalty terms. We evaluate the proposed method on image classification tasks, i.e., ResNet-18, ResNet-50 and VGG-16 using ImageNet and CIFAR-10, as well as object detection tasks, i.e., YOLOv3 and YOLOv3-tiny using COCO 2014, PointPillars using KITTI 2017, and Ultra-Fast-Lane-Detection using TuSimple lane detection dataset. Numerical testing results demonstrate that with the adoption of the Surrogate Lagrangian Relaxation method, our SLR-based weight-pruning optimization approach achieves a high model accuracy even at the hard-pruning stage without retraining for many epochs, such as on PointPillars object detection model on KITTI dataset where we achieve 9.44x compression rate by only retraining for 3 epochs with less than 1% accuracy loss. As the compression rate increases, SLR starts to perform better than ADMM and the accuracy gap between them increases. SLR achieves 15.2% better accuracy than ADMM on PointPillars after pruning under 9.49x compression. Given a limited budget of retraining epochs, our approach quickly recovers the model accuracy.