 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Lagrangian Relaxation: A Path To Retrain-free Deep Neural Network Pruning
Paper and Code
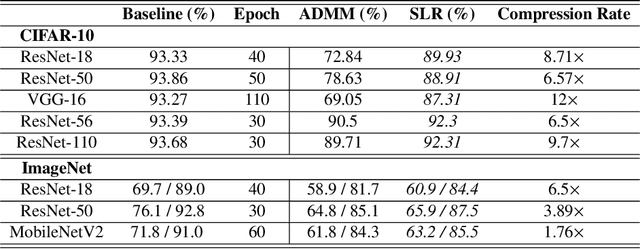
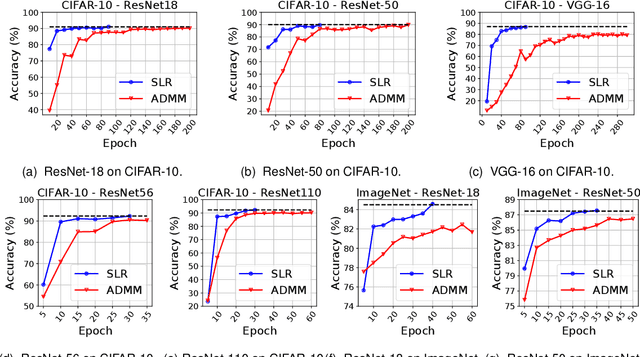
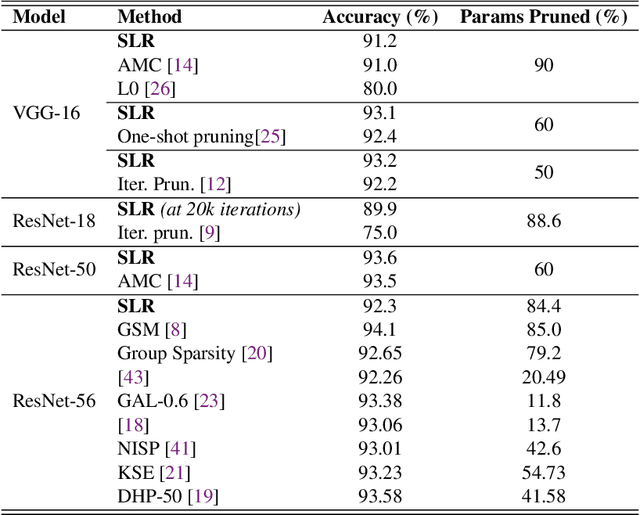
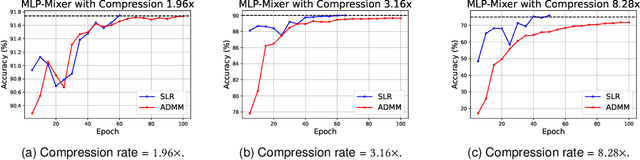
Network pruning is a widely used technique to reduce computation cost and model size for deep neural networks. However, the typical three-stage pipeline significantly increases the overall training time. In this paper, we develop a systematic weight-pruning optimization approach based on Surrogate Lagrangian relaxation, which is tailored to overcome difficulties caused by the discrete nature of the weight-pruning problem. We prove that our method ensures fast convergence of the model compression problem, and the convergence of the SLR is accelerated by using quadratic penalties. Model parameters obtained by SLR during the training phase are much closer to their optimal values as compared to those obtained by other state-of-the-art methods. We evaluate our method on image classification tasks using CIFAR-10 and ImageNet with state-of-the-art MLP-Mixer, Swin Transformer, and VGG-16, ResNet-18, ResNet-50 and ResNet-110, MobileNetV2. We also evaluate object detection and segmentation tasks on COCO, KITTI benchmark, and TuSimple lane detection dataset using a variety of models. Experimental results demonstrate that our SLR-based weight-pruning optimization approach achieves a higher compression rate than state-of-the-art methods under the same accuracy requirement and also can achieve higher accuracy under the same compression rate requirement. Under classification tasks, our SLR approach converges to the desired accuracy $3\times$ faster on both of the datasets. Under object detection and segmentation tasks, SLR also converges $2\times$ faster to the desired accuracy. Further, our SLR achieves high model accuracy even at the hard-pruning stage without retraining, which reduces the traditional three-stage pruning into a two-stage process. Given a limited budget of retraining epochs, our approach quickly recovers the model's accuracy.