 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Lagrangian Relaxation: A Path To Retrain-free Deep Neural Network Pruning
Apr 08, 2023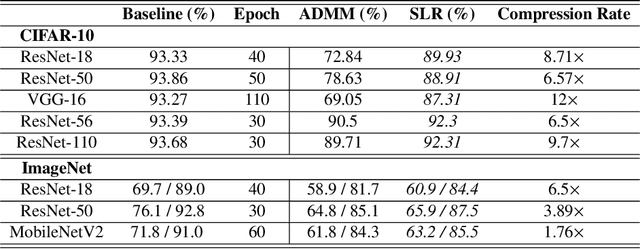
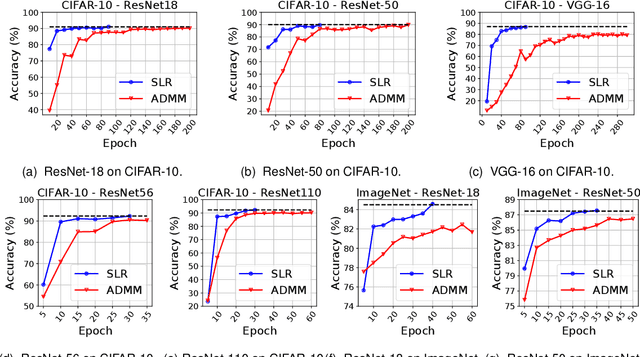
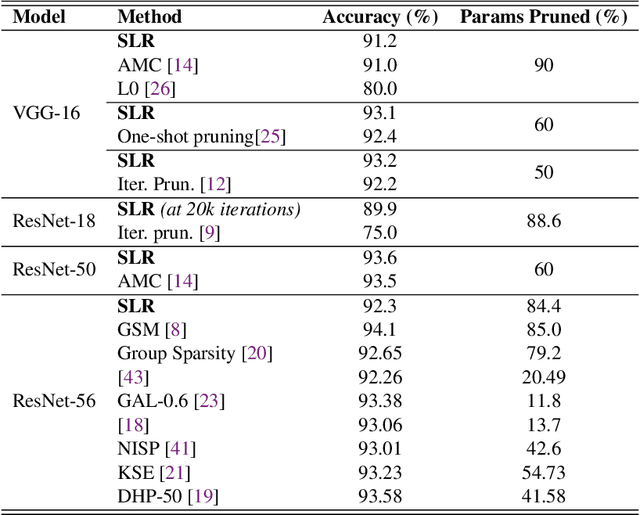
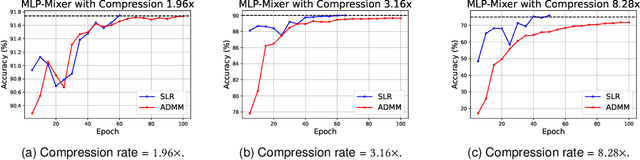
Network pruning is a widely used technique to reduce computation cost and model size for deep neural networks. However, the typical three-stage pipeline significantly increases the overall training time. In this paper, we develop a systematic weight-pruning optimization approach based on Surrogate Lagrangian relaxation, which is tailored to overcome difficulties caused by the discrete nature of the weight-pruning problem. We prove that our method ensures fast convergence of the model compression problem, and the convergence of the SLR is accelerated by using quadratic penalties. Model parameters obtained by SLR during the training phase are much closer to their optimal values as compared to those obtained by other state-of-the-art methods. We evaluate our method on image classification tasks using CIFAR-10 and ImageNet with state-of-the-art MLP-Mixer, Swin Transformer, and VGG-16, ResNet-18, ResNet-50 and ResNet-110, MobileNetV2. We also evaluate object detection and segmentation tasks on COCO, KITTI benchmark, and TuSimple lane detection dataset using a variety of models. Experimental results demonstrate that our SLR-based weight-pruning optimization approach achieves a higher compression rate than state-of-the-art methods under the same accuracy requirement and also can achieve higher accuracy under the same compression rate requirement. Under classification tasks, our SLR approach converges to the desired accuracy $3\times$ faster on both of the datasets. Under object detection and segmentation tasks, SLR also converges $2\times$ faster to the desired accuracy. Further, our SLR achieves high model accuracy even at the hard-pruning stage without retraining, which reduces the traditional three-stage pruning into a two-stage process. Given a limited budget of retraining epochs, our approach quickly recovers the model's accuracy.
Towards Real-Time Temporal Graph Learning
Oct 12, 2022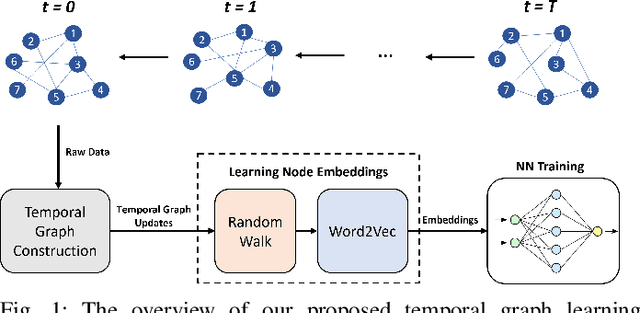
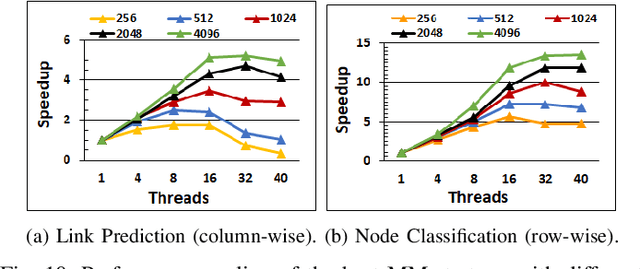
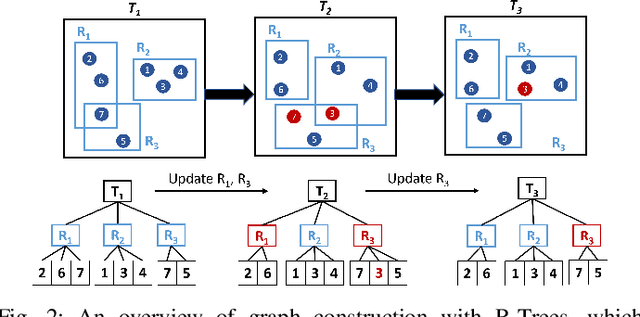
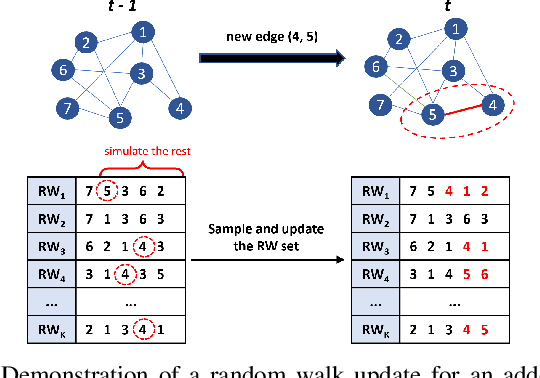
In recent years, graph representation learning has gained significant popularity, which aims to generate node embeddings that capture features of graphs. One of the methods to achieve this is employing a technique called random walks that captures node sequences in a graph and then learns embeddings for each node using a natural language processing technique called Word2Vec. These embeddings are then used for deep learning on graph data for classification tasks, such as link prediction or node classification. Prior work operates on pre-collected temporal graph data and is not designed to handle updates on a graph in real-time. Real world graphs change dynamically and their entire temporal updates are not available upfront. In this paper, we propose an end-to-end graph learning pipeline that performs temporal graph construction, creates low-dimensional node embeddings, and trains multi-layer neural network models in an online setting. The training of the neural network models is identified as the main performance bottleneck as it performs repeated matrix operations on many sequentially connected low-dimensional kernels. We propose to unlock fine-grain parallelism in these low-dimensional kernels to boost performance of model training.
Towards Sparsification of Graph Neural Networks
Sep 11, 2022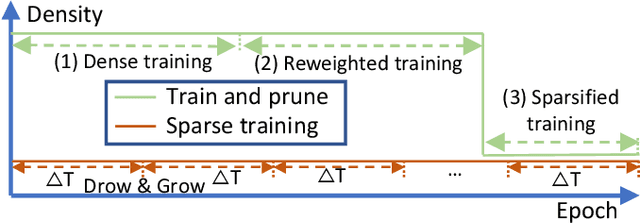
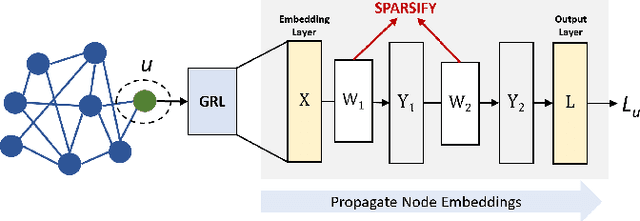
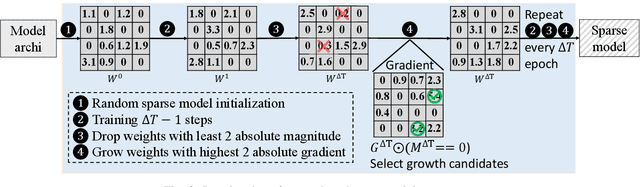

As real-world graphs expand in size, larger GNN models with billions of parameters are deployed. High parameter count in such models makes training and inference on graphs expensive and challenging. To reduce the computational and memory costs of GNNs, optimization methods such as pruning the redundant nodes and edges in input graphs have been commonly adopted. However, model compression, which directly targets the sparsification of model layers, has been mostly limited to traditional Deep Neural Networks (DNNs) used for tasks such as image classification and object detection. In this paper, we utilize two state-of-the-art model compression methods (1) train and prune and (2) sparse training for the sparsification of weight layers in GNNs. We evaluate and compare the efficiency of both methods in terms of accuracy, training sparsity, and training FLOPs on real-world graphs. Our experimental results show that on the ia-email, wiki-talk, and stackoverflow datasets for link prediction, sparse training with much lower training FLOPs achieves a comparable accuracy with the train and prune method. On the brain dataset for node classification, sparse training uses a lower number FLOPs (less than 1/7 FLOPs of train and prune method) and preserves a much better accuracy performance under extreme model sparsity.
A Surrogate Lagrangian Relaxation-based Model Compression for Deep Neural Networks
Dec 18, 2020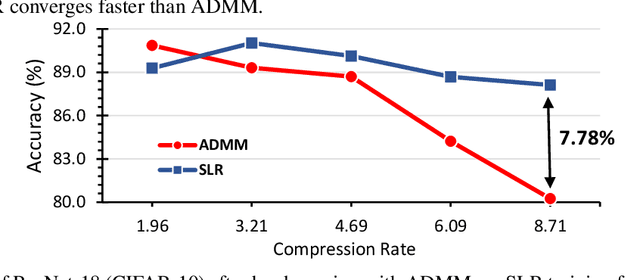
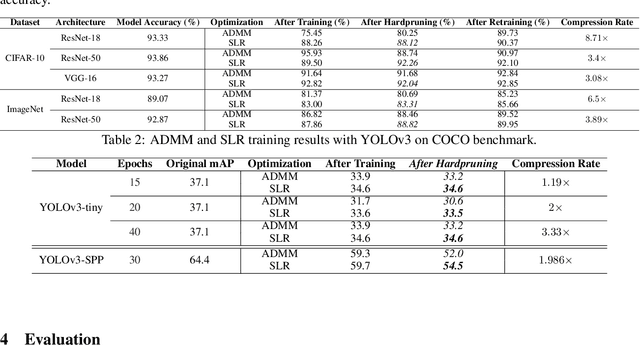
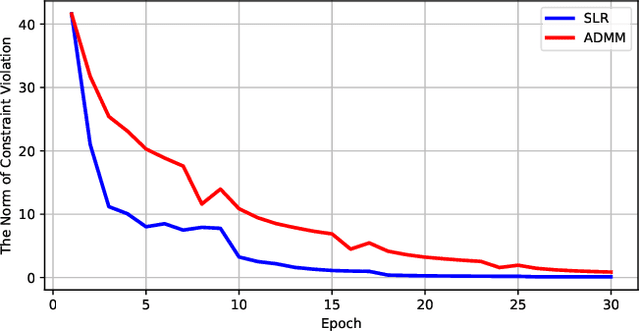
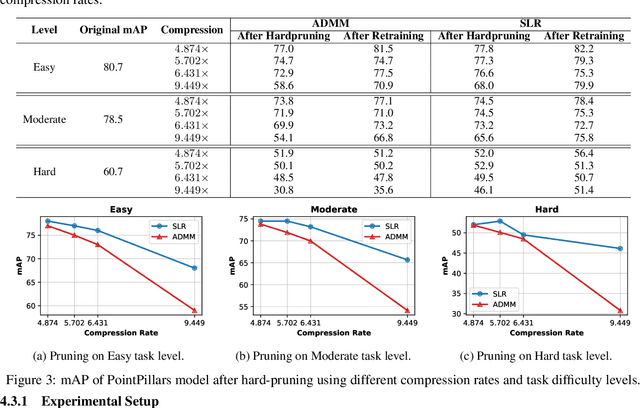
Network pruning is a widely used technique to reduce computation cost and model size for deep neural networks. However, the typical three-stage pipeline, i.e., training, pruning and retraining (fine-tuning) significantly increases the overall training trails. For instance, the retraining process could take up to 80 epochs for ResNet-18 on ImageNet, that is 70% of the original model training trails. In this paper, we develop a systematic weight-pruning optimization approach based on Surrogate Lagrangian relaxation (SLR), which is tailored to overcome difficulties caused by the discrete nature of the weight-pruning problem while ensuring fast convergence. We decompose the weight-pruning problem into subproblems, which are coordinated by updating Lagrangian multipliers. Convergence is then accelerated by using quadratic penalty terms. We evaluate the proposed method on image classification tasks, i.e., ResNet-18, ResNet-50 and VGG-16 using ImageNet and CIFAR-10, as well as object detection tasks, i.e., YOLOv3 and YOLOv3-tiny using COCO 2014, PointPillars using KITTI 2017, and Ultra-Fast-Lane-Detection using TuSimple lane detection dataset. Numerical testing results demonstrate that with the adoption of the Surrogate Lagrangian Relaxation method, our SLR-based weight-pruning optimization approach achieves a high model accuracy even at the hard-pruning stage without retraining for many epochs, such as on PointPillars object detection model on KITTI dataset where we achieve 9.44x compression rate by only retraining for 3 epochs with less than 1% accuracy loss. As the compression rate increases, SLR starts to perform better than ADMM and the accuracy gap between them increases. SLR achieves 15.2% better accuracy than ADMM on PointPillars after pruning under 9.49x compression. Given a limited budget of retraining epochs, our approach quickly recovers the model accuracy.
Beware the Black-Box: on the Robustness of Recent Defenses to Adversarial Examples
Jun 18, 2020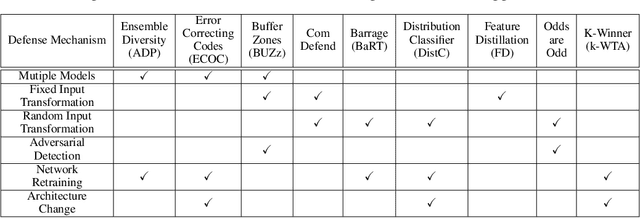
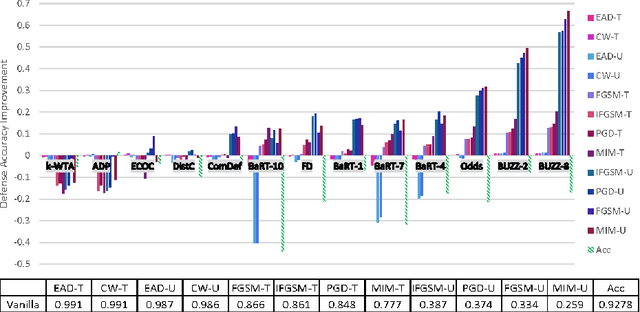
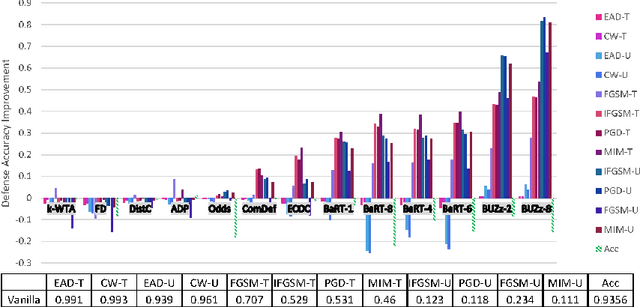
Recent defenses published at venues like NIPS, ICML, ICLR and CVPR are mainly focused on mitigating white-box attacks. These defenses do not properly consider adaptive adversaries. In this paper, we expand the scope of these defenses to include adaptive black-box adversaries. Our evaluation is done on nine defenses including Barrage of Random Transforms, ComDefend, Ensemble Diversity, Feature Distillation, The Odds are Odd, Error Correcting Codes, Distribution Classifier Defense, K-Winner Take All and Buffer Zones. Our investigation is done using two black-box adversarial models and six widely studied adversarial attacks for CIFAR-10 and Fashion-MNIST datasets. Our analyses show most recent defenses provide only marginal improvements in security, as compared to undefended networks. Based on these results, we propose new standards for properly evaluating defenses to black-box adversaries. We provide this security framework to assist researchers in developing future black-box resistant models.