 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Lagrangian Relaxation: A Path To Retrain-free Deep Neural Network Pruning
Apr 08, 2023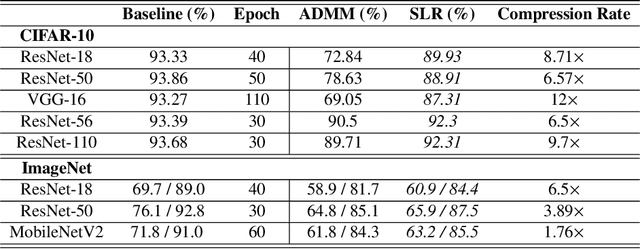
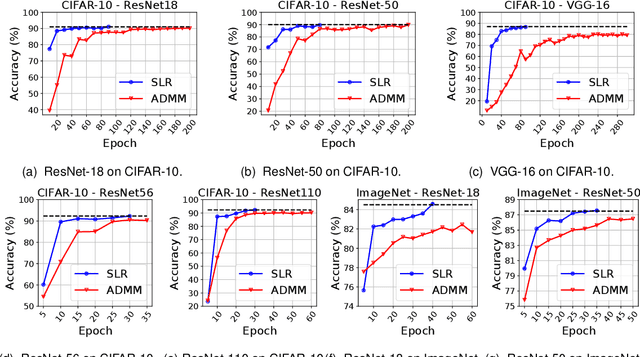
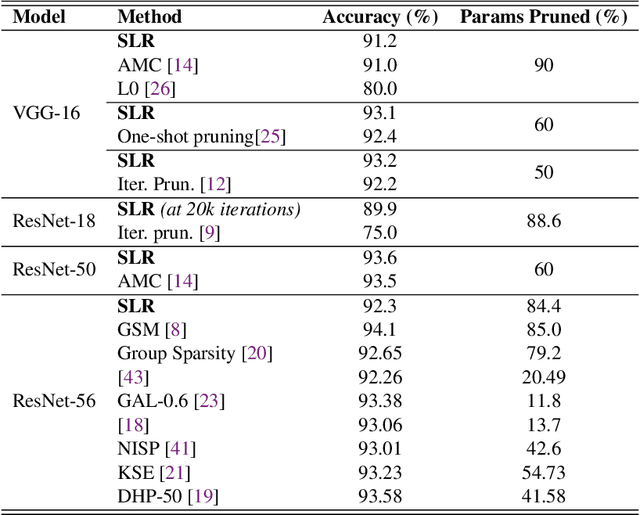
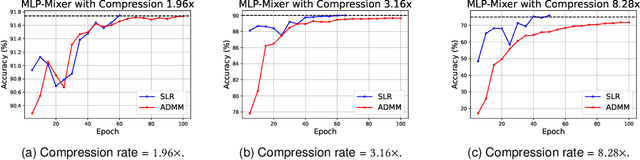
Network pruning is a widely used technique to reduce computation cost and model size for deep neural networks. However, the typical three-stage pipeline significantly increases the overall training time. In this paper, we develop a systematic weight-pruning optimization approach based on Surrogate Lagrangian relaxation, which is tailored to overcome difficulties caused by the discrete nature of the weight-pruning problem. We prove that our method ensures fast convergence of the model compression problem, and the convergence of the SLR is accelerated by using quadratic penalties. Model parameters obtained by SLR during the training phase are much closer to their optimal values as compared to those obtained by other state-of-the-art methods. We evaluate our method on image classification tasks using CIFAR-10 and ImageNet with state-of-the-art MLP-Mixer, Swin Transformer, and VGG-16, ResNet-18, ResNet-50 and ResNet-110, MobileNetV2. We also evaluate object detection and segmentation tasks on COCO, KITTI benchmark, and TuSimple lane detection dataset using a variety of models. Experimental results demonstrate that our SLR-based weight-pruning optimization approach achieves a higher compression rate than state-of-the-art methods under the same accuracy requirement and also can achieve higher accuracy under the same compression rate requirement. Under classification tasks, our SLR approach converges to the desired accuracy $3\times$ faster on both of the datasets. Under object detection and segmentation tasks, SLR also converges $2\times$ faster to the desired accuracy. Further, our SLR achieves high model accuracy even at the hard-pruning stage without retraining, which reduces the traditional three-stage pruning into a two-stage process. Given a limited budget of retraining epochs, our approach quickly recovers the model's accuracy.
Shared Information-Based Safe And Efficient Behavior Planning For Connected Autonomous Vehicles
Feb 15, 2023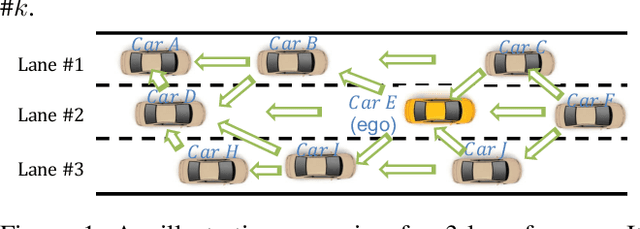

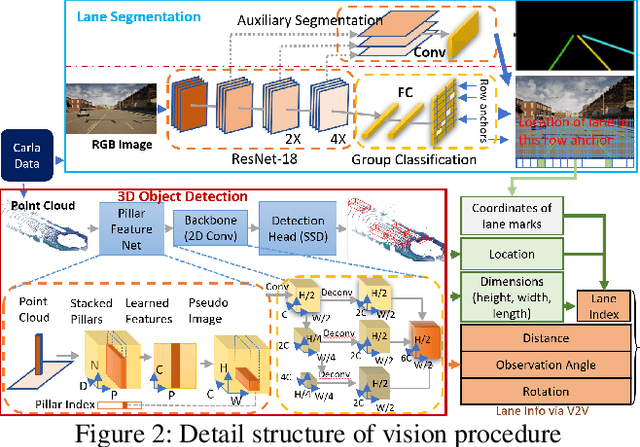
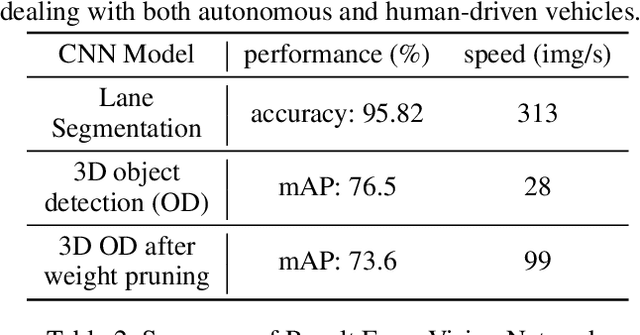
The recent advancements in wireless technology enable connected autonomous vehicles (CAVs) to gather data via vehicle-to-vehicle (V2V) communication, such as processed LIDAR and camera data from other vehicles. In this work, we design an integrated information sharing and safe multi-agent reinforcement learning (MARL) framework for CAVs, to take advantage of the extra information when making decisions to improve traffic efficiency and safety. We first use weight pruned convolutional neural networks (CNN) to process the raw image and point cloud LIDAR data locally at each autonomous vehicle, and share CNN-output data with neighboring CAVs. We then design a safe actor-critic algorithm that utilizes both a vehicle's local observation and the information received via V2V communication to explore an efficient behavior planning policy with safety guarantees. Using the CARLA simulator for experiments, we show that our approach improves the CAV system's efficiency in terms of average velocity and comfort under different CAV ratios and different traffic densities. We also show that our approach avoids the execution of unsafe actions and always maintains a safe distance from other vehicles. We construct an obstacle-at-corner scenario to show that the shared vision can help CAVs to observe obstacles earlier and take action to avoid traffic jams.
Data-Driven Distributionally Robust Electric Vehicle Balancing for Autonomous Mobility-on-Demand Systems under Demand and Supply Uncertainties
Nov 24, 2022
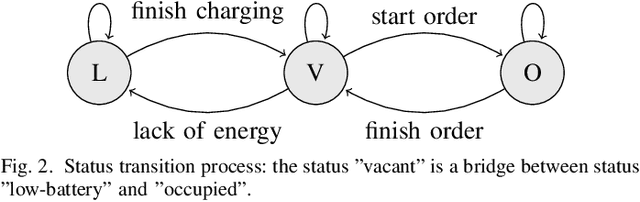
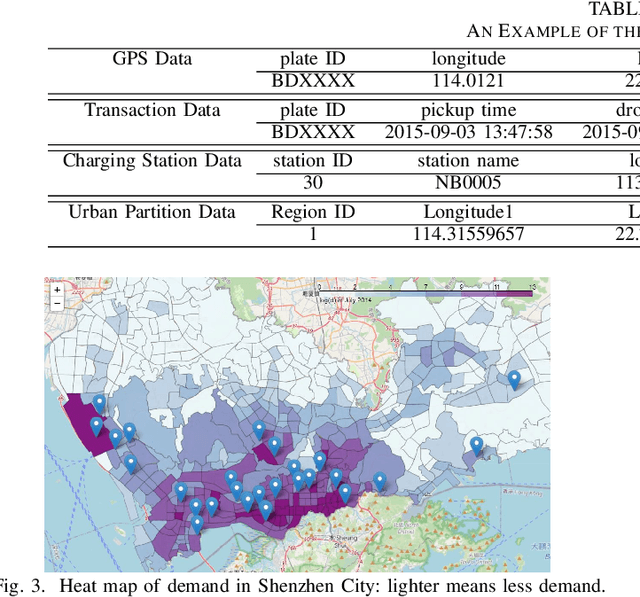
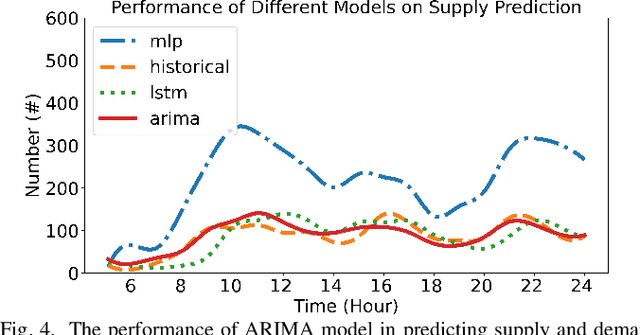
Electric vehicles (EVs) are being rapidly adopted due to their economic and societal benefits. Autonomous mobility-on-demand (AMoD) systems also embrace this trend. However, the long charging time and high recharging frequency of EVs pose challenges to efficiently managing EV AMoD systems. The complicated dynamic charging and mobility process of EV AMoD systems makes the demand and supply uncertainties significant when designing vehicle balancing algorithms. In this work, we design a data-driven distributionally robust optimization (DRO) approach to balance EVs for both the mobility service and the charging process. The optimization goal is to minimize the worst-case expected cost under both passenger mobility demand uncertainties and EV supply uncertainties. We then propose a novel distributional uncertainty sets construction algorithm that guarantees the produced parameters are contained in desired confidence regions with a given probability. To solve the proposed DRO AMoD EV balancing problem, we derive an equivalent computationally tractable convex optimization problem. Based on real-world EV data of a taxi system, we show that with our solution the average total balancing cost is reduced by 14.49%, and the average mobility fairness and charging fairness are improved by 15.78% and 34.51%, respectively, compared to solutions that do not consider uncertainties.
Data-Driven Distributionally Robust Electric Vehicle Balancing for Mobility-on-Demand Systems under Demand and Supply Uncertainties
Oct 19, 2022



As electric vehicle (EV) technologies become mature, EV has been rapidly adopted in modern transportation systems, and is expected to provide future autonomous mobility-on-demand (AMoD) service with economic and societal benefits. However, EVs require frequent recharges due to their limited and unpredictable cruising ranges, and they have to be managed efficiently given the dynamic charging process. It is urgent and challenging to investigate a computationally efficient algorithm that provide EV AMoD system performance guarantees under model uncertainties, instead of using heuristic demand or charging models. To accomplish this goal, this work designs a data-driven distributionally robust optimization approach for vehicle supply-demand ratio and charging station utilization balancing, while minimizing the worst-case expected cost considering both passenger mobility demand uncertainties and EV supply uncertainties. We then derive an equivalent computationally tractable form for solving the distributionally robust problem in a computationally efficient way under ellipsoid uncertainty sets constructed from data. Based on E-taxi system data of Shenzhen city, we show that the average total balancing cost is reduced by 14.49%, the average unfairness of supply-demand ratio and utilization is reduced by 15.78% and 34.51% respectively with the distributionally robust vehicle balancing method, compared with solutions which do not consider model uncertainties.
A Surrogate Lagrangian Relaxation-based Model Compression for Deep Neural Networks
Dec 18, 2020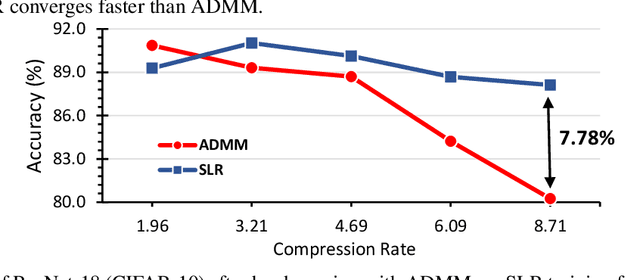
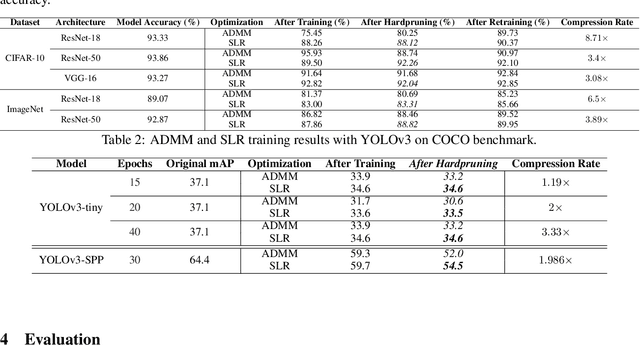
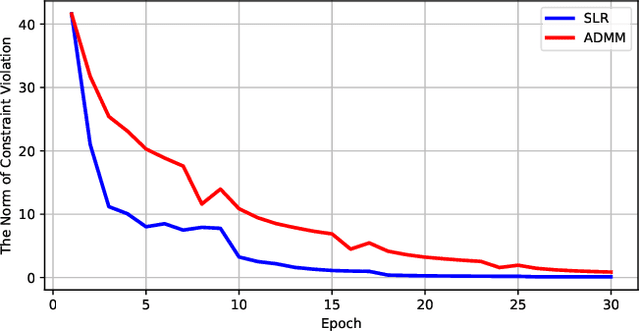
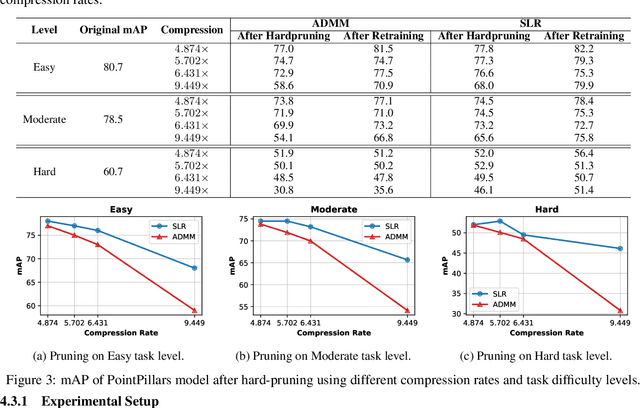
Network pruning is a widely used technique to reduce computation cost and model size for deep neural networks. However, the typical three-stage pipeline, i.e., training, pruning and retraining (fine-tuning) significantly increases the overall training trails. For instance, the retraining process could take up to 80 epochs for ResNet-18 on ImageNet, that is 70% of the original model training trails. In this paper, we develop a systematic weight-pruning optimization approach based on Surrogate Lagrangian relaxation (SLR), which is tailored to overcome difficulties caused by the discrete nature of the weight-pruning problem while ensuring fast convergence. We decompose the weight-pruning problem into subproblems, which are coordinated by updating Lagrangian multipliers. Convergence is then accelerated by using quadratic penalty terms. We evaluate the proposed method on image classification tasks, i.e., ResNet-18, ResNet-50 and VGG-16 using ImageNet and CIFAR-10, as well as object detection tasks, i.e., YOLOv3 and YOLOv3-tiny using COCO 2014, PointPillars using KITTI 2017, and Ultra-Fast-Lane-Detection using TuSimple lane detection dataset. Numerical testing results demonstrate that with the adoption of the Surrogate Lagrangian Relaxation method, our SLR-based weight-pruning optimization approach achieves a high model accuracy even at the hard-pruning stage without retraining for many epochs, such as on PointPillars object detection model on KITTI dataset where we achieve 9.44x compression rate by only retraining for 3 epochs with less than 1% accuracy loss. As the compression rate increases, SLR starts to perform better than ADMM and the accuracy gap between them increases. SLR achieves 15.2% better accuracy than ADMM on PointPillars after pruning under 9.49x compression. Given a limited budget of retraining epochs, our approach quickly recovers the model accuracy.