 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Guided Layer Fusion Mitigates Hallucination in Multimodal LLMs
Jan 06, 2026Multimodal large language models (MLLMs) typically rely on a single late-layer feature from a frozen vision encoder, leaving the encoder's rich hierarchy of visual cues under-utilized. MLLMs still suffer from visually ungrounded hallucinations, often relying on language priors rather than image evidence. While many prior mitigation strategies operate on the text side, they leave the visual representation unchanged and do not exploit the rich hierarchy of features encoded across vision layers. Existing multi-layer fusion methods partially address this limitation but remain static, applying the same layer mixture regardless of the query. In this work, we introduce TGIF (Text-Guided Inter-layer Fusion), a lightweight module that treats encoder layers as depth-wise "experts" and predicts a prompt-dependent fusion of visual features. TGIF follows the principle of direct external fusion, requires no vision-encoder updates, and adds minimal overhead. Integrated into LLaVA-1.5-7B, TGIF provides consistent improvements across hallucination, OCR, and VQA benchmarks, while preserving or improving performance on ScienceQA, GQA, and MMBench. These results suggest that query-conditioned, hierarchy-aware fusion is an effective way to strengthen visual grounding and reduce hallucination in modern MLLMs.
Uncertainty Quantification for Collaborative Object Detection Under Adversarial Attacks
Feb 04, 2025



Collaborative Object Detection (COD) and collaborative perception can integrate data or features from various entities, and improve object detection accuracy compared with individual perception. However, adversarial attacks pose a potential threat to the deep learning COD models, and introduce high output uncertainty. With unknown attack models, it becomes even more challenging to improve COD resiliency and quantify the output uncertainty for highly dynamic perception scenes such as autonomous vehicles. In this study, we propose the Trusted Uncertainty Quantification in Collaborative Perception framework (TUQCP). TUQCP leverages both adversarial training and uncertainty quantification techniques to enhance the adversarial robustness of existing COD models. More specifically, TUQCP first adds perturbations to the shared information of randomly selected agents during object detection collaboration by adversarial training. TUQCP then alleviates the impacts of adversarial attacks by providing output uncertainty estimation through learning-based module and uncertainty calibration through conformal prediction. Our framework works for early and intermediate collaboration COD models and single-agent object detection models. We evaluate TUQCP on V2X-Sim, a comprehensive collaborative perception dataset for autonomous driving, and demonstrate a 80.41% improvement in object detection accuracy compared to the baselines under the same adversarial attacks. TUQCP demonstrates the importance of uncertainty quantification to COD under adversarial attacks.
Adaptive Uncertainty Quantification for Trajectory Prediction Under Distributional Shift
Jun 17, 2024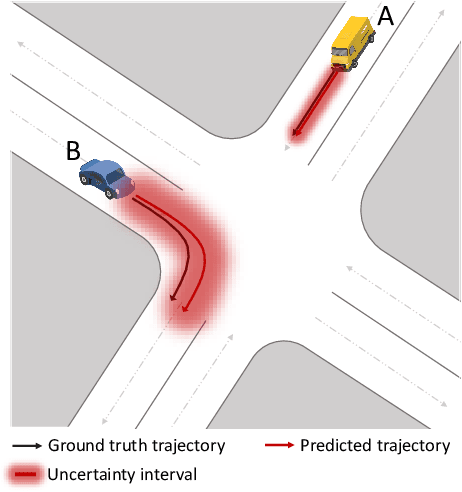

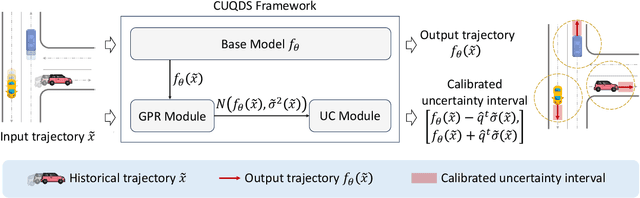

Trajectory prediction models that can infer both finite future trajectories and their associated uncertainties of the target vehicles in an online setting (e.g., real-world application scenarios) is crucial for ensuring the safe and robust navigation and path planning of autonomous vehicle motion. However, the majority of existing trajectory prediction models have neither considered reducing the uncertainty as one objective during the training stage nor provided reliable uncertainty quantification during inference stage under potential distribution shift. Therefore, in this paper, we propose the Conformal Uncertainty Quantification under Distribution Shift framework, CUQDS, to quantify the uncertainty of the predicted trajectories of existing trajectory prediction models under potential data distribution shift, while considering improving the prediction accuracy of the models and reducing the estimated uncertainty during the training stage. Specifically, CUQDS includes 1) a learning-based Gaussian process regression module that models the output distribution of the base model (any existing trajectory prediction or time series forecasting neural networks) and reduces the estimated uncertainty by additional loss term, and 2) a statistical-based Conformal P control module to calibrate the estimated uncertainty from the Gaussian process regression module in an online setting under potential distribution shift between training and testing data.
$α$-SSC: Uncertainty-Aware Camera-based 3D Semantic Scene Completion
Jun 16, 2024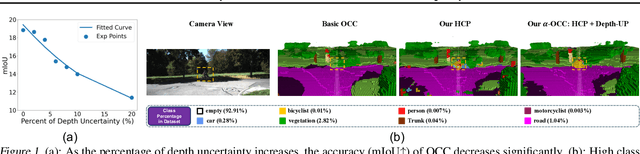
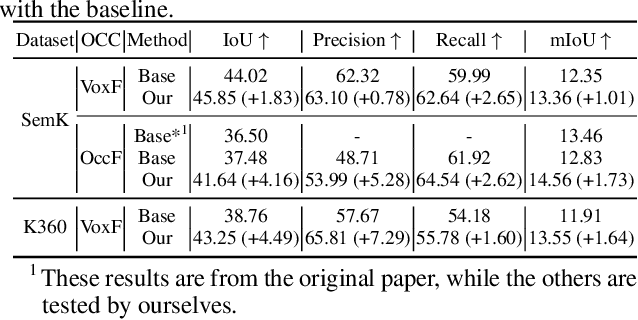
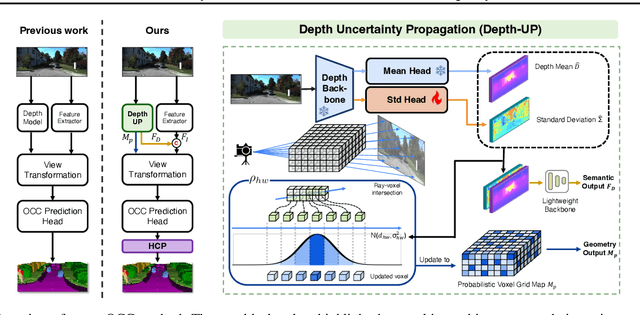
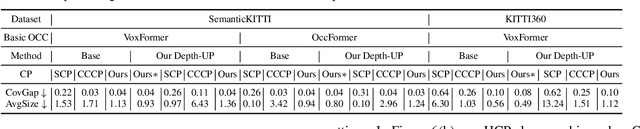
In the realm of autonomous vehicle (AV) perception, comprehending 3D scenes is paramount for tasks such as planning and mapping. Semantic scene completion (SSC) aims to infer scene geometry and semantics from limited observations. While camera-based SSC has gained popularity due to affordability and rich visual cues, existing methods often neglect the inherent uncertainty in models. To address this, we propose an uncertainty-aware camera-based 3D semantic scene completion method ($\alpha$-SSC). Our approach includes an uncertainty propagation framework from depth models (Depth-UP) to enhance geometry completion (up to 11.58% improvement) and semantic segmentation (up to 14.61% improvement). Additionally, we propose a hierarchical conformal prediction (HCP) method to quantify SSC uncertainty, effectively addressing high-level class imbalance in SSC datasets. On the geometry level, we present a novel KL divergence-based score function that significantly improves the occupied recall of safety-critical classes (45% improvement) with minimal performance overhead (3.4% reduction). For uncertainty quantification, we demonstrate the ability to achieve smaller prediction set sizes while maintaining a defined coverage guarantee. Compared with baselines, it achieves up to 85% reduction in set sizes. Our contributions collectively signify significant advancements in SSC accuracy and robustness, marking a noteworthy step forward in autonomous perception systems.
Momentum for the Win: Collaborative Federated Reinforcement Learning across Heterogeneous Environments
May 29, 2024



We explore a Federated Reinforcement Learning (FRL) problem where $N$ agents collaboratively learn a common policy without sharing their trajectory data. To date, existing FRL work has primarily focused on agents operating in the same or ``similar" environments. In contrast, our problem setup allows for arbitrarily large levels of environment heterogeneity. To obtain the optimal policy which maximizes the average performance across all potentially completely different environments, we propose two algorithms: FedSVRPG-M and FedHAPG-M. In contrast to existing results, we demonstrate that both FedSVRPG-M and FedHAPG-M, both of which leverage momentum mechanisms, can exactly converge to a stationary point of the average performance function, regardless of the magnitude of environment heterogeneity. Furthermore, by incorporating the benefits of variance-reduction techniques or Hessian approximation, both algorithms achieve state-of-the-art convergence results, characterized by a sample complexity of $\mathcal{O}\left(\epsilon^{-\frac{3}{2}}/N\right)$. Notably, our algorithms enjoy linear convergence speedups with respect to the number of agents, highlighting the benefit of collaboration among agents in finding a common policy.
Constrained Reinforcement Learning Under Model Mismatch
May 02, 2024



Existing studies on constrained reinforcement learning (RL) may obtain a well-performing policy in the training environment. However, when deployed in a real environment, it may easily violate constraints that were originally satisfied during training because there might be model mismatch between the training and real environments. To address the above challenge, we formulate the problem as constrained RL under model uncertainty, where the goal is to learn a good policy that optimizes the reward and at the same time satisfy the constraint under model mismatch. We develop a Robust Constrained Policy Optimization (RCPO) algorithm, which is the first algorithm that applies to large/continuous state space and has theoretical guarantees on worst-case reward improvement and constraint violation at each iteration during the training. We demonstrate the effectiveness of our algorithm on a set of RL tasks with constraints.
Safe and Robust Multi-Agent Reinforcement Learning for Connected Autonomous Vehicles under State Perturbations
Sep 20, 2023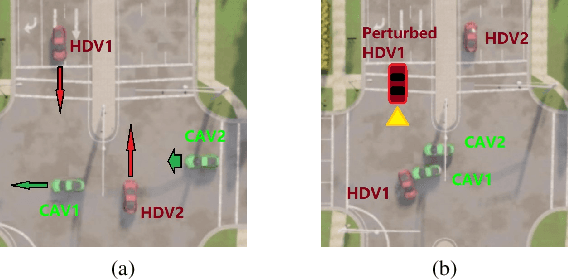

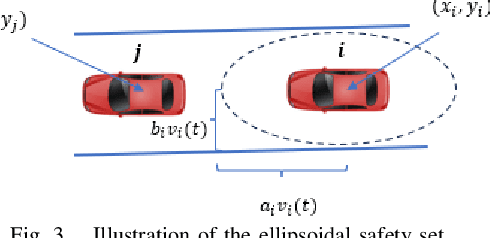

Sensing and communication technologies have enhanced learning-based decision making methodologies for multi-agent systems such as connected autonomous vehicles (CAV). However, most existing safe reinforcement learning based methods assume accurate state information. It remains challenging to achieve safety requirement under state uncertainties for CAVs, considering the noisy sensor measurements and the vulnerability of communication channels. In this work, we propose a Robust Multi-Agent Proximal Policy Optimization with robust Safety Shield (SR-MAPPO) for CAVs in various driving scenarios. Both robust MARL algorithm and control barrier function (CBF)-based safety shield are used in our approach to cope with the perturbed or uncertain state inputs. The robust policy is trained with a worst-case Q function regularization module that pursues higher lower-bounded reward in the former, whereas the latter, i.e., the robust CBF safety shield accounts for CAVs' collision-free constraints in complicated driving scenarios with even perturbed vehicle state information. We validate the advantages of SR-MAPPO in robustness and safety and compare it with baselines under different driving and state perturbation scenarios in CARLA simulator. The SR-MAPPO policy is verified to maintain higher safety rates and efficiency (reward) when threatened by both state perturbations and unconnected vehicles' dangerous behaviors.
Robust Multi-Agent Reinforcement Learning with State Uncertainty
Jul 30, 2023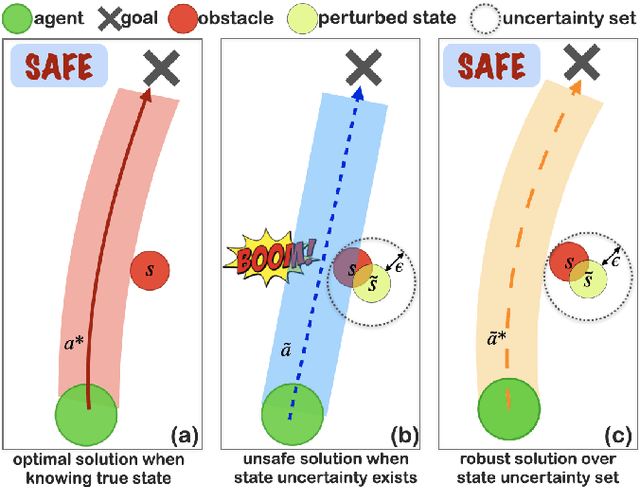

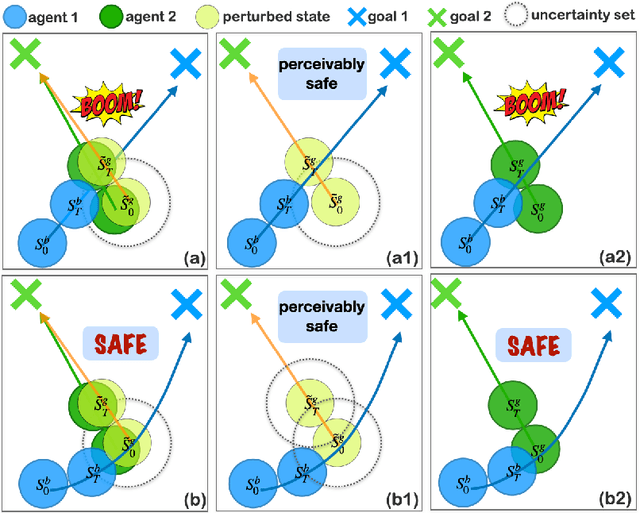

In real-world multi-agent reinforcement learning (MARL) applications, agents may not have perfect state information (e.g., due to inaccurate measurement or malicious attacks), which challenges the robustness of agents' policies. Though robustness is getting important in MARL deployment, little prior work has studied state uncertainties in MARL, neither in problem formulation nor algorithm design. Motivated by this robustness issue and the lack of corresponding studies, we study the problem of MARL with state uncertainty in this work. We provide the first attempt to the theoretical and empirical analysis of this challenging problem. We first model the problem as a Markov Game with state perturbation adversaries (MG-SPA) by introducing a set of state perturbation adversaries into a Markov Game. We then introduce robust equilibrium (RE) as the solution concept of an MG-SPA. We conduct a fundamental analysis regarding MG-SPA such as giving conditions under which such a robust equilibrium exists. Then we propose a robust multi-agent Q-learning (RMAQ) algorithm to find such an equilibrium, with convergence guarantees. To handle high-dimensional state-action space, we design a robust multi-agent actor-critic (RMAAC) algorithm based on an analytical expression of the policy gradient derived in the paper. Our experiments show that the proposed RMAQ algorithm converges to the optimal value function; our RMAAC algorithm outperforms several MARL and robust MARL methods in multiple multi-agent environments when state uncertainty is present. The source code is public on \url{https://github.com/sihongho/robust_marl_with_state_uncertainty}.
Robust Electric Vehicle Balancing of Autonomous Mobility-On-Demand System: A Multi-Agent Reinforcement Learning Approach
Jul 30, 2023



Electric autonomous vehicles (EAVs) are getting attention in future autonomous mobility-on-demand (AMoD) systems due to their economic and societal benefits. However, EAVs' unique charging patterns (long charging time, high charging frequency, unpredictable charging behaviors, etc.) make it challenging to accurately predict the EAVs supply in E-AMoD systems. Furthermore, the mobility demand's prediction uncertainty makes it an urgent and challenging task to design an integrated vehicle balancing solution under supply and demand uncertainties. Despite the success of reinforcement learning-based E-AMoD balancing algorithms, state uncertainties under the EV supply or mobility demand remain unexplored. In this work, we design a multi-agent reinforcement learning (MARL)-based framework for EAVs balancing in E-AMoD systems, with adversarial agents to model both the EAVs supply and mobility demand uncertainties that may undermine the vehicle balancing solutions. We then propose a robust E-AMoD Balancing MARL (REBAMA) algorithm to train a robust EAVs balancing policy to balance both the supply-demand ratio and charging utilization rate across the whole city. Experiments show that our proposed robust method performs better compared with a non-robust MARL method that does not consider state uncertainties; it improves the reward, charging utilization fairness, and supply-demand fairness by 19.28%, 28.18%, and 3.97%, respectively. Compared with a robust optimization-based method, the proposed MARL algorithm can improve the reward, charging utilization fairness, and supply-demand fairness by 8.21%, 8.29%, and 9.42%, respectively.
Multi-Agent Reinforcement Learning Guided by Signal Temporal Logic Specifications
Jun 11, 2023
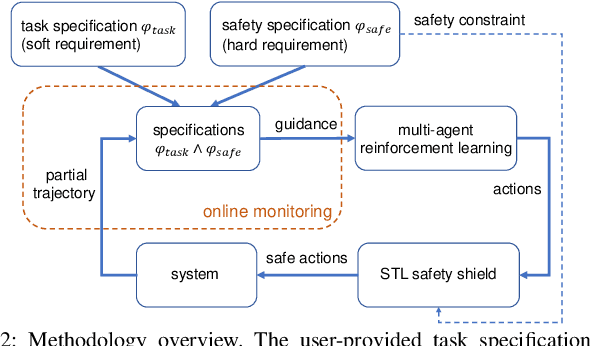
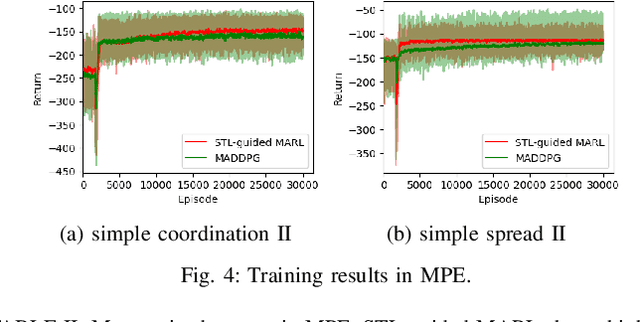
There has been growing interest in deep reinforcement learning (DRL) algorithm design, and reward design is one key component of DRL. Among the various techniques, formal methods integrated with DRL have garnered considerable attention due to their expressiveness and ability to define the requirements for the states and actions of the agent. However, the literature of Signal Temporal Logic (STL) in guiding multi-agent reinforcement learning (MARL) reward design remains limited. In this paper, we propose a novel STL-guided multi-agent reinforcement learning algorithm. The STL specifications are designed to include both task specifications according to the objective of each agent and safety specifications, and the robustness values of the STL specifications are leveraged to generate rewards. We validate the advantages of our method through empirical studies. The experimental results demonstrate significant performance improvements compared to MARL without STL guidance, along with a remarkable increase in the overall safety rate of the multi-agent systems.