 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Robust Multitask Adaptive Control
Nov 07, 2025We study adversarially robust multitask adaptive linear quadratic control; a setting where multiple systems collaboratively learn control policies under model uncertainty and adversarial corruption. We propose a clustered multitask approach that integrates clustering and system identification with resilient aggregation to mitigate corrupted model updates. Our analysis characterizes how clustering accuracy, intra-cluster heterogeneity, and adversarial behavior affect the expected regret of certainty-equivalent (CE) control across LQR tasks. We establish non-asymptotic bounds demonstrating that the regret decreases inversely with the number of honest systems per cluster and that this reduction is preserved under a bounded fraction of adversarial systems within each cluster.
Learning Stabilizing Policies via an Unstable Subspace Representation
May 02, 2025We study the problem of learning to stabilize (LTS) a linear time-invariant (LTI) system. Policy gradient (PG) methods for control assume access to an initial stabilizing policy. However, designing such a policy for an unknown system is one of the most fundamental problems in control, and it may be as hard as learning the optimal policy itself. Existing work on the LTS problem requires large data as it scales quadratically with the ambient dimension. We propose a two-phase approach that first learns the left unstable subspace of the system and then solves a series of discounted linear quadratic regulator (LQR) problems on the learned unstable subspace, targeting to stabilize only the system's unstable dynamics and reduce the effective dimension of the control space. We provide non-asymptotic guarantees for both phases and demonstrate that operating on the unstable subspace reduces sample complexity. In particular, when the number of unstable modes is much smaller than the state dimension, our analysis reveals that LTS on the unstable subspace substantially speeds up the stabilization process. Numerical experiments are provided to support this sample complexity reduction achieved by our approach.
Collaborative Bayesian Optimization via Wasserstein Barycenters
Apr 15, 2025



Motivated by the growing need for black-box optimization and data privacy, we introduce a collaborative Bayesian optimization (BO) framework that addresses both of these challenges. In this framework agents work collaboratively to optimize a function they only have oracle access to. In order to mitigate against communication and privacy constraints, agents are not allowed to share their data but can share their Gaussian process (GP) surrogate models. To enable collaboration under these constraints, we construct a central model to approximate the objective function by leveraging the concept of Wasserstein barycenters of GPs. This central model integrates the shared models without accessing the underlying data. A key aspect of our approach is a collaborative acquisition function that balances exploration and exploitation, allowing for the optimization of decision variables collaboratively in each iteration. We prove that our proposed algorithm is asymptotically consistent and that its implementation via Monte Carlo methods is numerically accurate. Through numerical experiments, we demonstrate that our approach outperforms other baseline collaborative frameworks and is competitive with centralized approaches that do not consider data privacy.
Coreset-Based Task Selection for Sample-Efficient Meta-Reinforcement Learning
Feb 04, 2025


We study task selection to enhance sample efficiency in model-agnostic meta-reinforcement learning (MAML-RL). Traditional meta-RL typically assumes that all available tasks are equally important, which can lead to task redundancy when they share significant similarities. To address this, we propose a coreset-based task selection approach that selects a weighted subset of tasks based on how diverse they are in gradient space, prioritizing the most informative and diverse tasks. Such task selection reduces the number of samples needed to find an $\epsilon$-close stationary solution by a factor of O(1/$\epsilon$). Consequently, it guarantees a faster adaptation to unseen tasks while focusing training on the most relevant tasks. As a case study, we incorporate task selection to MAML-LQR (Toso et al., 2024b), and prove a sample complexity reduction proportional to O(log(1/$\epsilon$)) when the task specific cost also satisfy gradient dominance. Our theoretical guarantees underscore task selection as a key component for scalable and sample-efficient meta-RL. We numerically validate this trend across multiple RL benchmark problems, illustrating the benefits of task selection beyond the LQR baseline.
Regret Analysis of Multi-task Representation Learning for Linear-Quadratic Adaptive Control
Jul 08, 2024Representation learning is a powerful tool that enables learning over large multitudes of agents or domains by enforcing that all agents operate on a shared set of learned features. However, many robotics or controls applications that would benefit from collaboration operate in settings with changing environments and goals, whereas most guarantees for representation learning are stated for static settings. Toward rigorously establishing the benefit of representation learning in dynamic settings, we analyze the regret of multi-task representation learning for linear-quadratic control. This setting introduces unique challenges. Firstly, we must account for and balance the $\textit{misspecification}$ introduced by an approximate representation. Secondly, we cannot rely on the parameter update schemes of single-task online LQR, for which least-squares often suffices, and must devise a novel scheme to ensure sufficient improvement. We demonstrate that for settings where exploration is "benign", the regret of any agent after $T$ timesteps scales as $\tilde O(\sqrt{T/H})$, where $H$ is the number of agents. In settings with "difficult" exploration, the regret scales as $\tilde{\mathcal O}(\sqrt{d_u d_\theta} \sqrt{T} + T^{3/4}/H^{1/5})$, where $d_x$ is the state-space dimension, $d_u$ is the input dimension, and $d_\theta$ is the task-specific parameter count. In both cases, by comparing to the minimax single-task regret $\tilde{\mathcal O}(\sqrt{d_x d_u^2}\sqrt{T})$, we see a benefit of a large number of agents. Notably, in the difficult exploration case, by sharing a representation across tasks, the effective task-specific parameter count can often be small $d_\theta < d_x d_u$. Lastly, we provide numerical validation of the trends we predict.
Momentum for the Win: Collaborative Federated Reinforcement Learning across Heterogeneous Environments
May 29, 2024



We explore a Federated Reinforcement Learning (FRL) problem where $N$ agents collaboratively learn a common policy without sharing their trajectory data. To date, existing FRL work has primarily focused on agents operating in the same or ``similar" environments. In contrast, our problem setup allows for arbitrarily large levels of environment heterogeneity. To obtain the optimal policy which maximizes the average performance across all potentially completely different environments, we propose two algorithms: FedSVRPG-M and FedHAPG-M. In contrast to existing results, we demonstrate that both FedSVRPG-M and FedHAPG-M, both of which leverage momentum mechanisms, can exactly converge to a stationary point of the average performance function, regardless of the magnitude of environment heterogeneity. Furthermore, by incorporating the benefits of variance-reduction techniques or Hessian approximation, both algorithms achieve state-of-the-art convergence results, characterized by a sample complexity of $\mathcal{O}\left(\epsilon^{-\frac{3}{2}}/N\right)$. Notably, our algorithms enjoy linear convergence speedups with respect to the number of agents, highlighting the benefit of collaboration among agents in finding a common policy.
Data-Efficient and Robust Task Selection for Meta-Learning
May 11, 2024Meta-learning methods typically learn tasks under the assumption that all tasks are equally important. However, this assumption is often not valid. In real-world applications, tasks can vary both in their importance during different training stages and in whether they contain noisy labeled data or not, making a uniform approach suboptimal. To address these issues, we propose the Data-Efficient and Robust Task Selection (DERTS) algorithm, which can be incorporated into both gradient and metric-based meta-learning algorithms. DERTS selects weighted subsets of tasks from task pools by minimizing the approximation error of the full gradient of task pools in the meta-training stage. The selected tasks are efficient for rapid training and robust towards noisy label scenarios. Unlike existing algorithms, DERTS does not require any architecture modification for training and can handle noisy label data in both the support and query sets. Analysis of DERTS shows that the algorithm follows similar training dynamics as learning on the full task pools. Experiments show that DERTS outperforms existing sampling strategies for meta-learning on both gradient-based and metric-based meta-learning algorithms in limited data budget and noisy task settings.
Finite-Time Analysis of On-Policy Heterogeneous Federated Reinforcement Learning
Jan 27, 2024
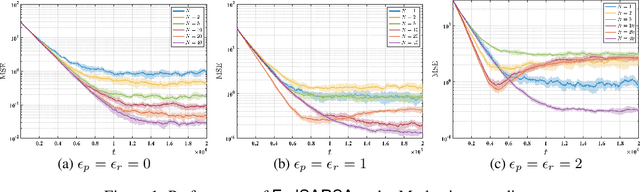


Federated reinforcement learning (FRL) has emerged as a promising paradigm for reducing the sample complexity of reinforcement learning tasks by exploiting information from different agents. However, when each agent interacts with a potentially different environment, little to nothing is known theoretically about the non-asymptotic performance of FRL algorithms. The lack of such results can be attributed to various technical challenges and their intricate interplay: Markovian sampling, linear function approximation, multiple local updates to save communication, heterogeneity in the reward functions and transition kernels of the agents' MDPs, and continuous state-action spaces. Moreover, in the on-policy setting, the behavior policies vary with time, further complicating the analysis. In response, we introduce FedSARSA, a novel federated on-policy reinforcement learning scheme, equipped with linear function approximation, to address these challenges and provide a comprehensive finite-time error analysis. Notably, we establish that FedSARSA converges to a policy that is near-optimal for all agents, with the extent of near-optimality proportional to the level of heterogeneity. Furthermore, we prove that FedSARSA leverages agent collaboration to enable linear speedups as the number of agents increases, which holds for both fixed and adaptive step-size configurations.
Meta-Learning Linear Quadratic Regulators: A Policy Gradient MAML Approach for the Model-free LQR
Jan 25, 2024
We investigate the problem of learning Linear Quadratic Regulators (LQR) in a multi-task, heterogeneous, and model-free setting. We characterize the stability and personalization guarantees of a Policy Gradient-based (PG) Model-Agnostic Meta-Learning (MAML) (Finn et al., 2017) approach for the LQR problem under different task-heterogeneity settings. We show that the MAML-LQR approach produces a stabilizing controller close to each task-specific optimal controller up to a task-heterogeneity bias for both model-based and model-free settings. Moreover, in the model-based setting, we show that this controller is achieved with a linear convergence rate, which improves upon sub-linear rates presented in existing MAML-LQR work. In contrast to existing MAML-LQR results, our theoretical guarantees demonstrate that the learned controller can efficiently adapt to unseen LQR tasks.
Oracle Complexity Reduction for Model-free LQR: A Stochastic Variance-Reduced Policy Gradient Approach
Sep 19, 2023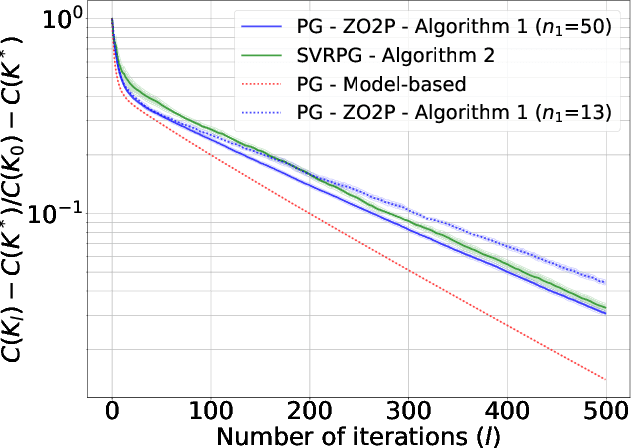

We investigate the problem of learning an $\epsilon$-approximate solution for the discrete-time Linear Quadratic Regulator (LQR) problem via a Stochastic Variance-Reduced Policy Gradient (SVRPG) approach. Whilst policy gradient methods have proven to converge linearly to the optimal solution of the model-free LQR problem, the substantial requirement for two-point cost queries in gradient estimations may be intractable, particularly in applications where obtaining cost function evaluations at two distinct control input configurations is exceptionally costly. To this end, we propose an oracle-efficient approach. Our method combines both one-point and two-point estimations in a dual-loop variance-reduced algorithm. It achieves an approximate optimal solution with only $O\left(\log\left(1/\epsilon\right)^{\beta}\right)$ two-point cost information for $\beta \in (0,1)$.