 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Bayesian Optimization via Wasserstein Barycenters
Apr 15, 2025



Motivated by the growing need for black-box optimization and data privacy, we introduce a collaborative Bayesian optimization (BO) framework that addresses both of these challenges. In this framework agents work collaboratively to optimize a function they only have oracle access to. In order to mitigate against communication and privacy constraints, agents are not allowed to share their data but can share their Gaussian process (GP) surrogate models. To enable collaboration under these constraints, we construct a central model to approximate the objective function by leveraging the concept of Wasserstein barycenters of GPs. This central model integrates the shared models without accessing the underlying data. A key aspect of our approach is a collaborative acquisition function that balances exploration and exploitation, allowing for the optimization of decision variables collaboratively in each iteration. We prove that our proposed algorithm is asymptotically consistent and that its implementation via Monte Carlo methods is numerically accurate. Through numerical experiments, we demonstrate that our approach outperforms other baseline collaborative frameworks and is competitive with centralized approaches that do not consider data privacy.
Coreset-Based Task Selection for Sample-Efficient Meta-Reinforcement Learning
Feb 04, 2025


We study task selection to enhance sample efficiency in model-agnostic meta-reinforcement learning (MAML-RL). Traditional meta-RL typically assumes that all available tasks are equally important, which can lead to task redundancy when they share significant similarities. To address this, we propose a coreset-based task selection approach that selects a weighted subset of tasks based on how diverse they are in gradient space, prioritizing the most informative and diverse tasks. Such task selection reduces the number of samples needed to find an $\epsilon$-close stationary solution by a factor of O(1/$\epsilon$). Consequently, it guarantees a faster adaptation to unseen tasks while focusing training on the most relevant tasks. As a case study, we incorporate task selection to MAML-LQR (Toso et al., 2024b), and prove a sample complexity reduction proportional to O(log(1/$\epsilon$)) when the task specific cost also satisfy gradient dominance. Our theoretical guarantees underscore task selection as a key component for scalable and sample-efficient meta-RL. We numerically validate this trend across multiple RL benchmark problems, illustrating the benefits of task selection beyond the LQR baseline.
Daily Physical Activity Monitoring -- Adaptive Learning from Multi-source Motion Sensor Data
May 26, 2024



In healthcare applications, there is a growing need to develop machine learning models that use data from a single source, such as that from a wrist wearable device, to monitor physical activities, assess health risks, and provide immediate health recommendations or interventions. However, the limitation of using single-source data often compromises the model's accuracy, as it fails to capture the full scope of human activities. While a more comprehensive dataset can be gathered in a lab setting using multiple sensors attached to various body parts, this approach is not practical for everyday use due to the impracticality of wearing multiple sensors. To address this challenge, we introduce a transfer learning framework that optimizes machine learning models for everyday applications by leveraging multi-source data collected in a laboratory setting. We introduce a novel metric to leverage the inherent relationship between these multiple data sources, as they are all paired to capture aspects of the same physical activity. Through numerical experiments, our framework outperforms existing methods in classification accuracy and robustness to noise, offering a promising avenue for the enhancement of daily activity monitoring.
Data-Efficient and Robust Task Selection for Meta-Learning
May 11, 2024Meta-learning methods typically learn tasks under the assumption that all tasks are equally important. However, this assumption is often not valid. In real-world applications, tasks can vary both in their importance during different training stages and in whether they contain noisy labeled data or not, making a uniform approach suboptimal. To address these issues, we propose the Data-Efficient and Robust Task Selection (DERTS) algorithm, which can be incorporated into both gradient and metric-based meta-learning algorithms. DERTS selects weighted subsets of tasks from task pools by minimizing the approximation error of the full gradient of task pools in the meta-training stage. The selected tasks are efficient for rapid training and robust towards noisy label scenarios. Unlike existing algorithms, DERTS does not require any architecture modification for training and can handle noisy label data in both the support and query sets. Analysis of DERTS shows that the algorithm follows similar training dynamics as learning on the full task pools. Experiments show that DERTS outperforms existing sampling strategies for meta-learning on both gradient-based and metric-based meta-learning algorithms in limited data budget and noisy task settings.
Meta-Learning Linear Quadratic Regulators: A Policy Gradient MAML Approach for the Model-free LQR
Jan 25, 2024
We investigate the problem of learning Linear Quadratic Regulators (LQR) in a multi-task, heterogeneous, and model-free setting. We characterize the stability and personalization guarantees of a Policy Gradient-based (PG) Model-Agnostic Meta-Learning (MAML) (Finn et al., 2017) approach for the LQR problem under different task-heterogeneity settings. We show that the MAML-LQR approach produces a stabilizing controller close to each task-specific optimal controller up to a task-heterogeneity bias for both model-based and model-free settings. Moreover, in the model-based setting, we show that this controller is achieved with a linear convergence rate, which improves upon sub-linear rates presented in existing MAML-LQR work. In contrast to existing MAML-LQR results, our theoretical guarantees demonstrate that the learned controller can efficiently adapt to unseen LQR tasks.
Meta-Learning with Less Forgetting on Large-Scale Non-Stationary Task Distributions
Sep 03, 2022

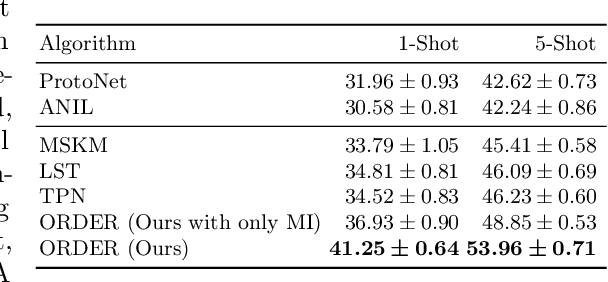
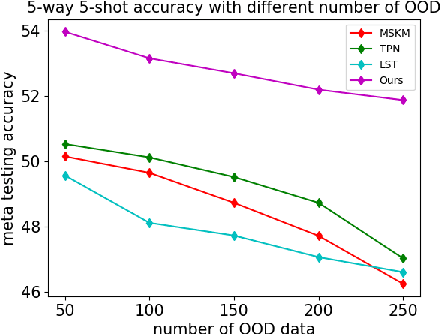
The paradigm of machine intelligence moves from purely supervised learning to a more practical scenario when many loosely related unlabeled data are available and labeled data is scarce. Most existing algorithms assume that the underlying task distribution is stationary. Here we consider a more realistic and challenging setting in that task distributions evolve over time. We name this problem as Semi-supervised meta-learning with Evolving Task diStributions, abbreviated as SETS. Two key challenges arise in this more realistic setting: (i) how to use unlabeled data in the presence of a large amount of unlabeled out-of-distribution (OOD) data; and (ii) how to prevent catastrophic forgetting on previously learned task distributions due to the task distribution shift. We propose an OOD Robust and knowleDge presErved semi-supeRvised meta-learning approach (ORDER), to tackle these two major challenges. Specifically, our ORDER introduces a novel mutual information regularization to robustify the model with unlabeled OOD data and adopts an optimal transport regularization to remember previously learned knowledge in feature space. In addition, we test our method on a very challenging dataset: SETS on large-scale non-stationary semi-supervised task distributions consisting of (at least) 72K tasks. With extensive experiments, we demonstrate the proposed ORDER alleviates forgetting on evolving task distributions and is more robust to OOD data than related strong baselines.
Adaptive Transfer Learning of Multi-View Time Series Classification
Oct 14, 2019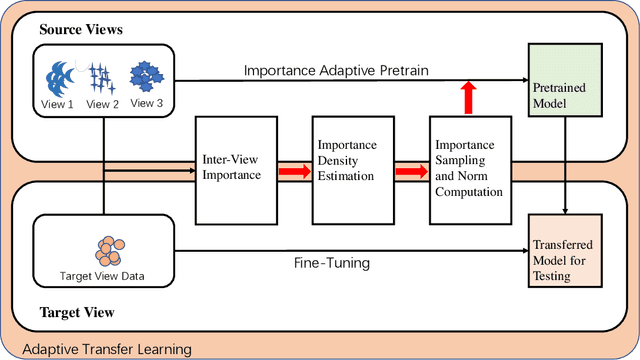


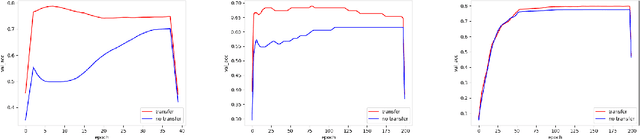
Time Series Classification (TSC) has been an important and challenging task in data mining, especially on multivariate time series and multi-view time series data sets. Meanwhile, transfer learning has been widely applied in computer vision and natural language processing applications to improve deep neural network's generalization capabilities. However, very few previous works applied transfer learning framework to time series mining problems. Particularly, the technique of measuring similarities between source domain and target domain based on dynamic representation such as density estimation with importance sampling has never been combined with transfer learning framework. In this paper, we first proposed a general adaptive transfer learning framework for multi-view time series data, which shows strong ability in storing inter-view importance value in the process of knowledge transfer. Next, we represented inter-view importance through some time series similarity measurements and approximated the posterior distribution in latent space for the importance sampling via density estimation techniques. We then computed the matrix norm of sampled importance value, which controls the degree of knowledge transfer in pre-training process. We further evaluated our work, applied it to many other time series classification tasks, and observed that our architecture maintained desirable generalization ability. Finally, we concluded that our framework could be adapted with deep learning techniques to receive significant model performance improvements.
FIS-GAN: GAN with Flow-based Importance Sampling
Oct 06, 2019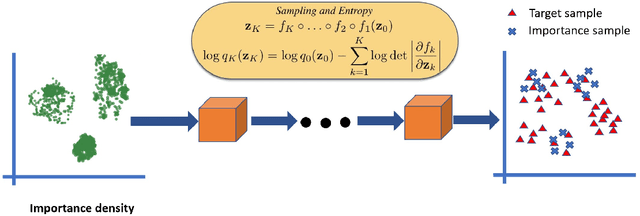
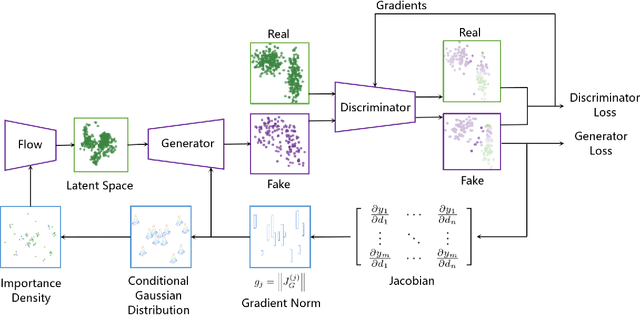
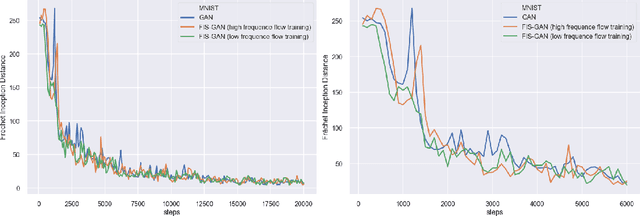
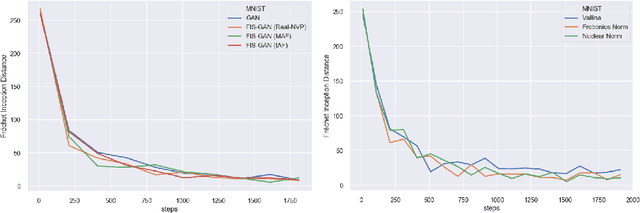
Generative Adversarial Networks (GAN) training process, in most cases, apply uniform and Gaussian sampling methods in latent space, which probably spends most of the computation on examples that can be properly handled and easy to generate. Theoretically, importance sampling speeds up stochastic gradient algorithms for supervised learning by prioritizing training examples. In this paper, we explore the possibility for adapting importance sampling into adversarial learning. We use importance sampling to replace uniform and Gaussian sampling methods in latent space and combine normalizing flow with importance sampling to approximate latent space posterior distribution by density estimation. Empirically, results on MNIST and Fashion-MNIST demonstrate that our method significantly accelerates the convergence of generative process while retaining visual fidelity in generated samples.