 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoRubric: Self-Evolving Rubric-Driven RL for Open-Ended Generation
May 28, 2026Reinforcement Learning (RL) has significantly advanced Large Language Models (LLMs) in verifiable domains, but aligning models for open-ended generation remains profoundly challenging due to the lack of definitive rewards. Current rubric-based RL methods mitigate this by employing explicit criteria; however, they rely heavily on static, human-annotated rubrics that inevitably cause policy lag, or expensive external proprietary models for dynamic updates. In this paper, we propose EvoRubric, a novel single-policy co-evolutionary RL framework that eliminates the reliance on static criteria and on external rubric generators. By unifying response generation and rubric generation under a single parameterized policy, EvoRubric dynamically alternates between a Reasoner and a Rubric Generator. To prevent reward hacking and ensure the reliability of generated signals, we introduce a multi-level verification pipeline featuring a meta-verifier, zero-variance pruning, and a Leave-One-Out peer consensus mechanism. Validated criteria are dynamically archived into a memory pool, yielding dense, multi-objective rewards to continuously co-optimize both roles. Extensive experiments across Medical, Writing, and Science domains demonstrate that EvoRubric consistently outperforms traditional static and external-LLM-driven alignment methods. Notably, our framework is compatible with human-expert priors. When initialized with expert-annotated rubrics, EvoRubric can further uncover novel, discriminative dimensions, achieving better performance than relying solely on static expert annotations.
Dystruct: Dynamically Structured Diffusion Language Model Decoding via Bayesian Inference
May 10, 2026Diffusion language models (DLMs) have recently emerged as a promising alternative to autoregressive models, primarily due to their ability to enable parallel decoding. Despite this advantage, most existing DLMs rely on a fixed generation length specified prior to decoding, which restricts their flexibility in real-world applications. While a few recent works attempt to support flexible-length generation, they typically suffer from notable limitations: some require costly retraining to accommodate variable-length outputs, while others depend solely on local confidence signals during decoding. Such local criteria fail to capture the evolving structure of the sequence, often resulting in suboptimal generation quality. In this paper, we propose a training-free, Bayesian structured decoding framework that formulates flexible-length generation as a dynamic structural inference problem. Our approach formulates flexible-length generation as a dynamic structural inference problem, jointly computing the expansion length, the block boundaries, and the decoding schedule. At each window expansion step, the method integrates local uncertainty with structural signals via a unified mechanism that supports dynamic structured generation, including both flexible block expansion and block organization, while maintaining coherence. Extensive experiments across multiple benchmarks demonstrate that our approach significantly improves generation quality and flexibility over existing fixed-length and flexible-length baselines. These results highlight the advantage of Bayesian structured decoding for diffusion language model, providing a principled and efficient solution for structured text generation.
Seeing to Ground: Visual Attention for Hallucination-Resilient MDLLMs
Mar 26, 2026Multimodal Diffusion Large Language Models (MDLLMs) achieve high-concurrency generation through parallel masked decoding, yet the architectures remain prone to multimodal hallucinations. This structural vulnerability stems from an algorithmic flaw: the decoder ranks candidate tokens based on textual likelihood without verifying localized visual support. We establish that this language-only ranking induces an objective mismatch, where language probability mass acts as a misspecified proxy for the intended multimodal task. Consequently, we reinterpret hallucination as a localized optimization error, a phenomenon where the decoder exploits language shortcuts to maximize a proxy score at the expense of visual grounding. To address this objective mismatch, we introduce VISAGE, a training-free decoding framework that calibrates the objective at inference time. VISAGE estimates the proxy discrepancy by quantifying the spatial entropy of cross-attention distributions. By enforcing a localization consensus across attention heads, the method penalizes spatially uniform distributions and re-ranks token commitments to favor visually grounded outcomes. We provide an analytical stability guarantee establishing that VISAGE maintains a bounded objective loss under estimation error. Evaluations across hallucination-sensitive and general-purpose benchmarks demonstrate the robustness of the framework, yielding relative gains of 8.59% on MMMU-val and 7.75% on HallusionBench.
AI Security in the Foundation Model Era: A Comprehensive Survey from a Unified Perspective
Mar 25, 2026As machine learning (ML) systems expand in both scale and functionality, the security landscape has become increasingly complex, with a proliferation of attacks and defenses. However, existing studies largely treat these threats in isolation, lacking a coherent framework to expose their shared principles and interdependencies. This fragmented view hinders systematic understanding and limits the design of comprehensive defenses. Crucially, the two foundational assets of ML -- \textbf{data} and \textbf{models} -- are no longer independent; vulnerabilities in one directly compromise the other. The absence of a holistic framework leaves open questions about how these bidirectional risks propagate across the ML pipeline. To address this critical gap, we propose a \emph{unified closed-loop threat taxonomy} that explicitly frames model-data interactions along four directional axes. Our framework offers a principled lens for analyzing and defending foundation models. The resulting four classes of security threats represent distinct but interrelated categories of attacks: (1) Data$\rightarrow$Data (D$\rightarrow$D): including \emph{data decryption attacks and watermark removal attacks}; (2) Data$\rightarrow$Model (D$\rightarrow$M): including \emph{poisoning, harmful fine-tuning attacks, and jailbreak attacks}; (3) Model$\rightarrow$Data (M$\rightarrow$D): including \emph{model inversion, membership inference attacks, and training data extraction attacks}; (4) Model$\rightarrow$Model (M$\rightarrow$M): including \emph{model extraction attacks}. Our unified framework elucidates the underlying connections among these security threats and establishes a foundation for developing scalable, transferable, and cross-modal security strategies, particularly within the landscape of foundation models.
CoRe: Context-Robust Remasking for Diffusion Language Models
Feb 04, 2026Standard decoding in Masked Diffusion Models (MDMs) is hindered by context rigidity: tokens are retained based on transient high confidence, often ignoring that early predictions lack full context. This creates cascade effects where initial inconsistencies misguide the remaining generation. Existing revision strategies attempt to mitigate this by relying on static confidence scores, but these signals are inherently myopic; inconsistent tokens can appear confident to the model itself. We propose Context-Robust Remasking (CoRe), a training-free framework for inference-time revision. Rather than trusting static token probabilities, CoRe identifies context-brittle tokens by probing their sensitivity to targeted masked-context perturbations. We formalize revision as a robust optimization objective over context shifts and efficiently approximate this objective to prioritize unstable tokens for revision. On LLaDA-8B-Base, CoRe delivers consistent improvements across reasoning and code benchmarks, outperforming compute-matched baselines and improving MBPP by up to 9.2 percentage points.
Medical SAM3: A Foundation Model for Universal Prompt-Driven Medical Image Segmentation
Jan 15, 2026Promptable segmentation foundation models such as SAM3 have demonstrated strong generalization capabilities through interactive and concept-based prompting. However, their direct applicability to medical image segmentation remains limited by severe domain shifts, the absence of privileged spatial prompts, and the need to reason over complex anatomical and volumetric structures. Here we present Medical SAM3, a foundation model for universal prompt-driven medical image segmentation, obtained by fully fine-tuning SAM3 on large-scale, heterogeneous 2D and 3D medical imaging datasets with paired segmentation masks and text prompts. Through a systematic analysis of vanilla SAM3, we observe that its performance degrades substantially on medical data, with its apparent competitiveness largely relying on strong geometric priors such as ground-truth-derived bounding boxes. These findings motivate full model adaptation beyond prompt engineering alone. By fine-tuning SAM3's model parameters on 33 datasets spanning 10 medical imaging modalities, Medical SAM3 acquires robust domain-specific representations while preserving prompt-driven flexibility. Extensive experiments across organs, imaging modalities, and dimensionalities demonstrate consistent and significant performance gains, particularly in challenging scenarios characterized by semantic ambiguity, complex morphology, and long-range 3D context. Our results establish Medical SAM3 as a universal, text-guided segmentation foundation model for medical imaging and highlight the importance of holistic model adaptation for achieving robust prompt-driven segmentation under severe domain shift. Code and model will be made available at https://github.com/AIM-Research-Lab/Medical-SAM3.
RAIR: A Rule-Aware Benchmark Uniting Challenging Long-Tail and Visual Salience Subset for E-commerce Relevance Assessment
Dec 31, 2025Search relevance plays a central role in web e-commerce. While large language models (LLMs) have shown significant results on relevance task, existing benchmarks lack sufficient complexity for comprehensive model assessment, resulting in an absence of standardized relevance evaluation metrics across the industry. To address this limitation, we propose Rule-Aware benchmark with Image for Relevance assessment(RAIR), a Chinese dataset derived from real-world scenarios. RAIR established a standardized framework for relevance assessment and provides a set of universal rules, which forms the foundation for standardized evaluation. Additionally, RAIR analyzes essential capabilities required for current relevance models and introduces a comprehensive dataset consists of three subset: (1) a general subset with industry-balanced sampling to evaluate fundamental model competencies; (2) a long-tail hard subset focus on challenging cases to assess performance limits; (3) a visual salience subset for evaluating multimodal understanding capabilities. We conducted experiments on RAIR using 14 open and closed-source models. The results demonstrate that RAIR presents sufficient challenges even for GPT-5, which achieved the best performance. RAIR data are now available, serving as an industry benchmark for relevance assessment while providing new insights into general LLM and Visual Language Model(VLM) evaluation.
Dynamic Feedback Engines: Layer-Wise Control for Self-Regulating Continual Learning
Dec 25, 2025Continual learning aims to acquire new tasks while preserving performance on previously learned ones, but most methods struggle with catastrophic forgetting. Existing approaches typically treat all layers uniformly, often trading stability for plasticity or vice versa. However, different layers naturally exhibit varying levels of uncertainty (entropy) when classifying tasks. High-entropy layers tend to underfit by failing to capture task-specific patterns, while low-entropy layers risk overfitting by becoming overly confident and specialized. To address this imbalance, we propose an entropy-aware continual learning method that employs a dynamic feedback mechanism to regulate each layer based on its entropy. Specifically, our approach reduces entropy in high-entropy layers to mitigate underfitting and increases entropy in overly confident layers to alleviate overfitting. This adaptive regulation encourages the model to converge to wider local minima, which have been shown to improve generalization. Our method is general and can be seamlessly integrated with both replay- and regularization-based approaches. Experiments on various datasets demonstrate substantial performance gains over state-of-the-art continual learning baselines.
From Efficiency to Adaptivity: A Deeper Look at Adaptive Reasoning in Large Language Models
Nov 13, 2025
Recent advances in large language models (LLMs) have made reasoning a central benchmark for evaluating intelligence. While prior surveys focus on efficiency by examining how to shorten reasoning chains or reduce computation, this view overlooks a fundamental challenge: current LLMs apply uniform reasoning strategies regardless of task complexity, generating long traces for trivial problems while failing to extend reasoning for difficult tasks. This survey reframes reasoning through the lens of {adaptivity}: the capability to allocate reasoning effort based on input characteristics such as difficulty and uncertainty. We make three contributions. First, we formalize deductive, inductive, and abductive reasoning within the LLM context, connecting these classical cognitive paradigms with their algorithmic realizations. Second, we formalize adaptive reasoning as a control-augmented policy optimization problem balancing task performance with computational cost, distinguishing learned policies from inference-time control mechanisms. Third, we propose a systematic taxonomy organizing existing methods into training-based approaches that internalize adaptivity through reinforcement learning, supervised fine-tuning, and learned controllers, and training-free approaches that achieve adaptivity through prompt conditioning, feedback-driven halting, and modular composition. This framework clarifies how different mechanisms realize adaptive reasoning in practice and enables systematic comparison across diverse strategies. We conclude by identifying open challenges in self-evaluation, meta-reasoning, and human-aligned reasoning control.
Sparse Model Inversion: Efficient Inversion of Vision Transformers for Data-Free Applications
Oct 31, 2025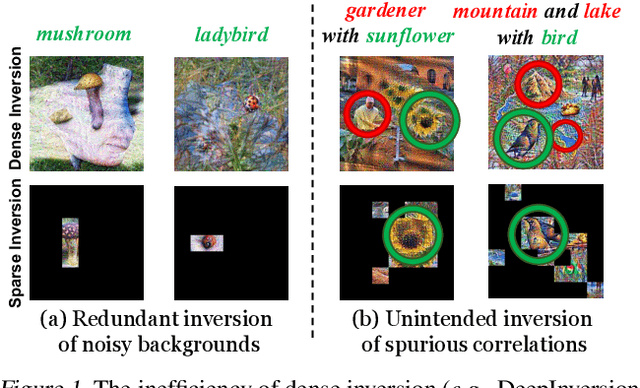
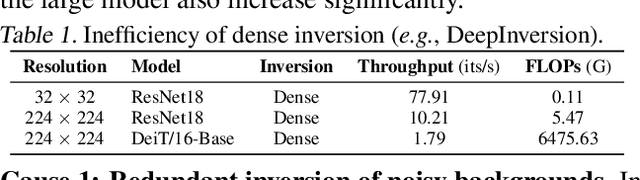
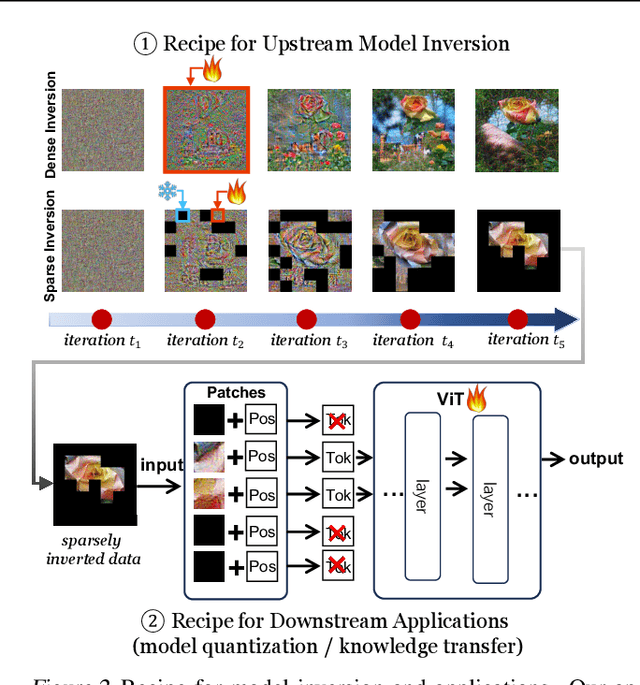
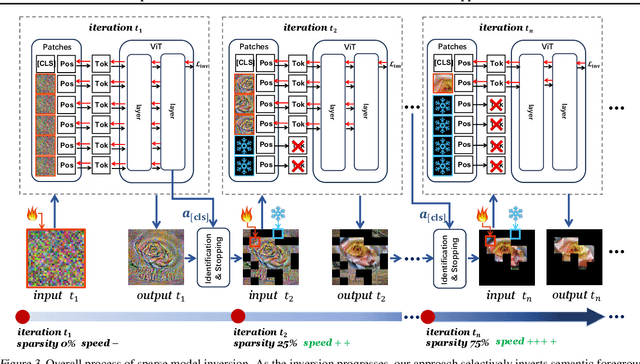
Model inversion, which aims to reconstruct the original training data from pre-trained discriminative models, is especially useful when the original training data is unavailable due to privacy, usage rights, or size constraints. However, existing dense inversion methods attempt to reconstruct the entire image area, making them extremely inefficient when inverting high-resolution images from large-scale Vision Transformers (ViTs). We further identify two underlying causes of this inefficiency: the redundant inversion of noisy backgrounds and the unintended inversion of spurious correlations--a phenomenon we term "hallucination" in model inversion. To address these limitations, we propose a novel sparse model inversion strategy, as a plug-and-play extension to speed up existing dense inversion methods with no need for modifying their original loss functions. Specifically, we selectively invert semantic foregrounds while stopping the inversion of noisy backgrounds and potential spurious correlations. Through both theoretical and empirical studies, we validate the efficacy of our approach in achieving significant inversion acceleration (up to 3.79 faster) while maintaining comparable or even enhanced downstream performance in data-free model quantization and data-free knowledge transfer. Code is available at https://github.com/Egg-Hu/SMI.