 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Defense against Harmful Fine-Tuning for Large Language Models via Bayesian Data Scheduler
Oct 31, 2025Harmful fine-tuning poses critical safety risks to fine-tuning-as-a-service for large language models. Existing defense strategies preemptively build robustness via attack simulation but suffer from fundamental limitations: (i) the infeasibility of extending attack simulations beyond bounded threat models due to the inherent difficulty of anticipating unknown attacks, and (ii) limited adaptability to varying attack settings, as simulation fails to capture their variability and complexity. To address these challenges, we propose Bayesian Data Scheduler (BDS), an adaptive tuning-stage defense strategy with no need for attack simulation. BDS formulates harmful fine-tuning defense as a Bayesian inference problem, learning the posterior distribution of each data point's safety attribute, conditioned on the fine-tuning and alignment datasets. The fine-tuning process is then constrained by weighting data with their safety attributes sampled from the posterior, thus mitigating the influence of harmful data. By leveraging the post hoc nature of Bayesian inference, the posterior is conditioned on the fine-tuning dataset, enabling BDS to tailor its defense to the specific dataset, thereby achieving adaptive defense. Furthermore, we introduce a neural scheduler based on amortized Bayesian learning, enabling efficient transfer to new data without retraining. Comprehensive results across diverse attack and defense settings demonstrate the state-of-the-art performance of our approach. Code is available at https://github.com/Egg-Hu/Bayesian-Data-Scheduler.
Sparse Model Inversion: Efficient Inversion of Vision Transformers for Data-Free Applications
Oct 31, 2025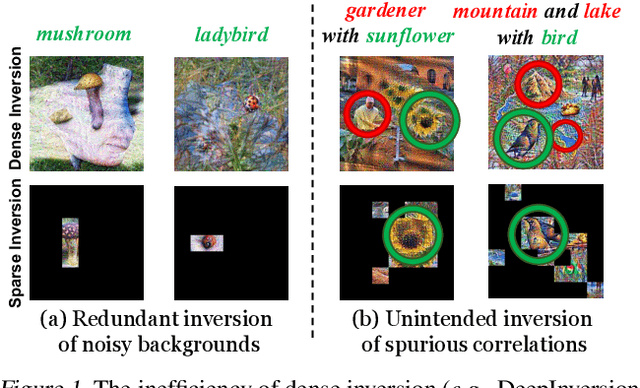
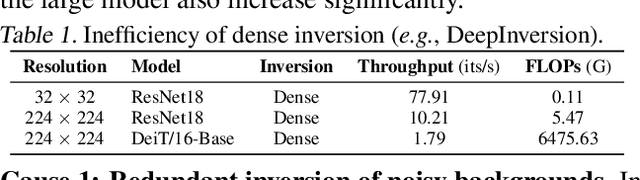
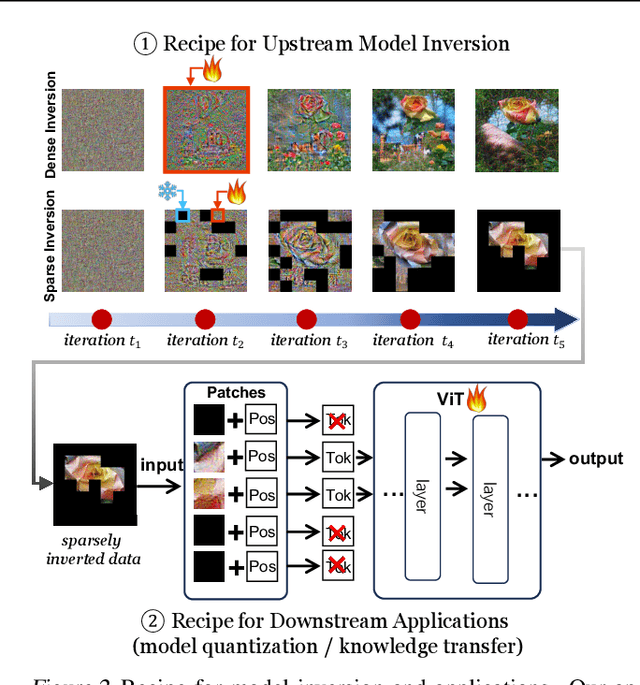
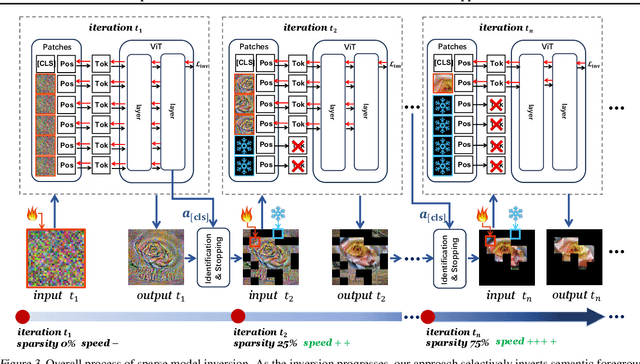
Model inversion, which aims to reconstruct the original training data from pre-trained discriminative models, is especially useful when the original training data is unavailable due to privacy, usage rights, or size constraints. However, existing dense inversion methods attempt to reconstruct the entire image area, making them extremely inefficient when inverting high-resolution images from large-scale Vision Transformers (ViTs). We further identify two underlying causes of this inefficiency: the redundant inversion of noisy backgrounds and the unintended inversion of spurious correlations--a phenomenon we term "hallucination" in model inversion. To address these limitations, we propose a novel sparse model inversion strategy, as a plug-and-play extension to speed up existing dense inversion methods with no need for modifying their original loss functions. Specifically, we selectively invert semantic foregrounds while stopping the inversion of noisy backgrounds and potential spurious correlations. Through both theoretical and empirical studies, we validate the efficacy of our approach in achieving significant inversion acceleration (up to 3.79 faster) while maintaining comparable or even enhanced downstream performance in data-free model quantization and data-free knowledge transfer. Code is available at https://github.com/Egg-Hu/SMI.
Position: Intelligent Science Laboratory Requires the Integration of Cognitive and Embodied AI
Jun 24, 2025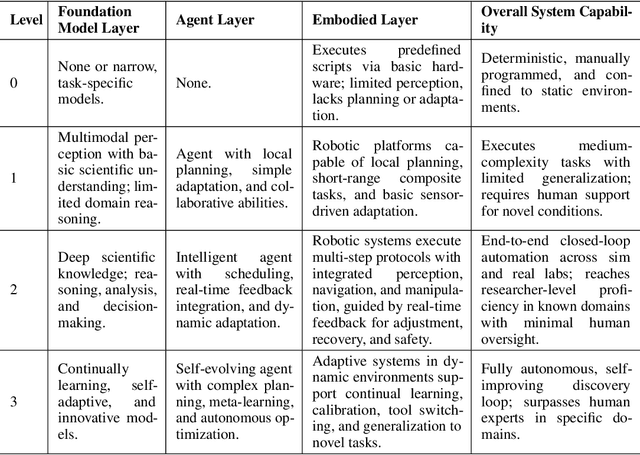
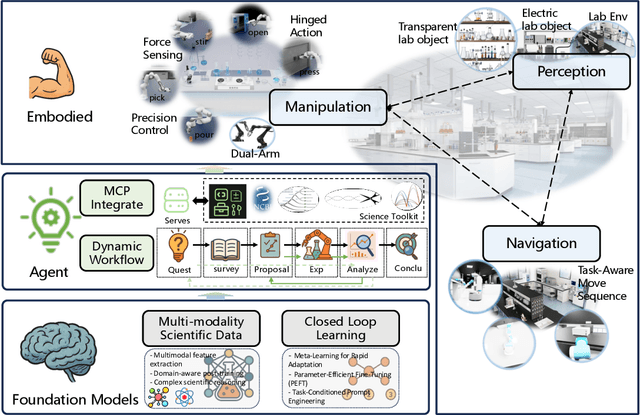
Scientific discovery has long been constrained by human limitations in expertise, physical capability, and sleep cycles. The recent rise of AI scientists and automated laboratories has accelerated both the cognitive and operational aspects of research. However, key limitations persist: AI systems are often confined to virtual environments, while automated laboratories lack the flexibility and autonomy to adaptively test new hypotheses in the physical world. Recent advances in embodied AI, such as generalist robot foundation models, diffusion-based action policies, fine-grained manipulation learning, and sim-to-real transfer, highlight the promise of integrating cognitive and embodied intelligence. This convergence opens the door to closed-loop systems that support iterative, autonomous experimentation and the possibility of serendipitous discovery. In this position paper, we propose the paradigm of Intelligent Science Laboratories (ISLs): a multi-layered, closed-loop framework that deeply integrates cognitive and embodied intelligence. ISLs unify foundation models for scientific reasoning, agent-based workflow orchestration, and embodied agents for robust physical experimentation. We argue that such systems are essential for overcoming the current limitations of scientific discovery and for realizing the full transformative potential of AI-driven science.
LabUtopia: High-Fidelity Simulation and Hierarchical Benchmark for Scientific Embodied Agents
May 28, 2025

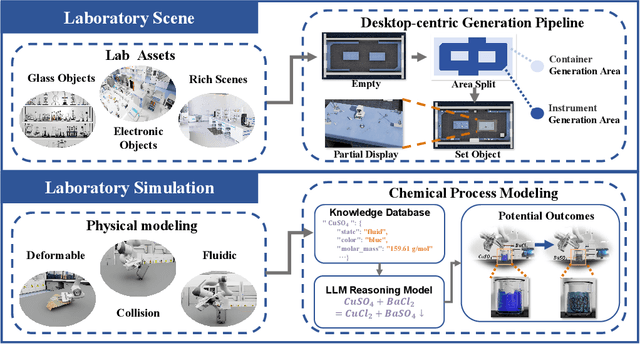
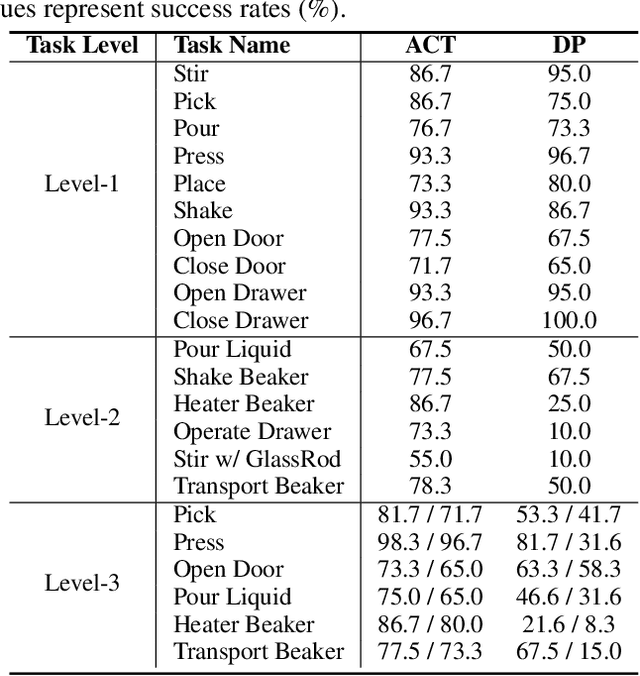
Scientific embodied agents play a crucial role in modern laboratories by automating complex experimental workflows. Compared to typical household environments, laboratory settings impose significantly higher demands on perception of physical-chemical transformations and long-horizon planning, making them an ideal testbed for advancing embodied intelligence. However, its development has been long hampered by the lack of suitable simulator and benchmarks. In this paper, we address this gap by introducing LabUtopia, a comprehensive simulation and benchmarking suite designed to facilitate the development of generalizable, reasoning-capable embodied agents in laboratory settings. Specifically, it integrates i) LabSim, a high-fidelity simulator supporting multi-physics and chemically meaningful interactions; ii) LabScene, a scalable procedural generator for diverse scientific scenes; and iii) LabBench, a hierarchical benchmark spanning five levels of complexity from atomic actions to long-horizon mobile manipulation. LabUtopia supports 30 distinct tasks and includes more than 200 scene and instrument assets, enabling large-scale training and principled evaluation in high-complexity environments. We demonstrate that LabUtopia offers a powerful platform for advancing the integration of perception, planning, and control in scientific-purpose agents and provides a rigorous testbed for exploring the practical capabilities and generalization limits of embodied intelligence in future research.
Beyond Entropy: Region Confidence Proxy for Wild Test-Time Adaptation
May 27, 2025Wild Test-Time Adaptation (WTTA) is proposed to adapt a source model to unseen domains under extreme data scarcity and multiple shifts. Previous approaches mainly focused on sample selection strategies, while overlooking the fundamental problem on underlying optimization. Initially, we critically analyze the widely-adopted entropy minimization framework in WTTA and uncover its significant limitations in noisy optimization dynamics that substantially hinder adaptation efficiency. Through our analysis, we identify region confidence as a superior alternative to traditional entropy, however, its direct optimization remains computationally prohibitive for real-time applications. In this paper, we introduce a novel region-integrated method ReCAP that bypasses the lengthy process. Specifically, we propose a probabilistic region modeling scheme that flexibly captures semantic changes in embedding space. Subsequently, we develop a finite-to-infinite asymptotic approximation that transforms the intractable region confidence into a tractable and upper-bounded proxy. These innovations significantly unlock the overlooked potential dynamics in local region in a concise solution. Our extensive experiments demonstrate the consistent superiority of ReCAP over existing methods across various datasets and wild scenarios.
SEVA: Leveraging Single-Step Ensemble of Vicinal Augmentations for Test-Time Adaptation
May 07, 2025Test-Time adaptation (TTA) aims to enhance model robustness against distribution shifts through rapid model adaptation during inference. While existing TTA methods often rely on entropy-based unsupervised training and achieve promising results, the common practice of a single round of entropy training is typically unable to adequately utilize reliable samples, hindering adaptation efficiency. In this paper, we discover augmentation strategies can effectively unleash the potential of reliable samples, but the rapidly growing computational cost impedes their real-time application. To address this limitation, we propose a novel TTA approach named Single-step Ensemble of Vicinal Augmentations (SEVA), which can take advantage of data augmentations without increasing the computational burden. Specifically, instead of explicitly utilizing the augmentation strategy to generate new data, SEVA develops a theoretical framework to explore the impacts of multiple augmentations on model adaptation and proposes to optimize an upper bound of the entropy loss to integrate the effects of multiple rounds of augmentation training into a single step. Furthermore, we discover and verify that using the upper bound as the loss is more conducive to the selection mechanism, as it can effectively filter out harmful samples that confuse the model. Combining these two key advantages, the proposed efficient loss and a complementary selection strategy can simultaneously boost the potential of reliable samples and meet the stringent time requirements of TTA. The comprehensive experiments on various network architectures across challenging testing scenarios demonstrate impressive performances and the broad adaptability of SEVA. The code will be publicly available.
Unlocking Tuning-Free Few-Shot Adaptability in Visual Foundation Models by Recycling Pre-Tuned LoRAs
Dec 03, 2024



Large Language Models (LLMs) such as ChatGPT demonstrate strong few-shot adaptability without requiring fine-tuning, positioning them ideal for data-limited and real-time applications. However, this adaptability has not yet been replicated in current Visual Foundation Models (VFMs), which require explicit fine-tuning with sufficient tuning data. Besides, the pretraining-finetuning paradigm has led to the surge of numerous task-specific modular components, such as Low-Rank Adaptation (LoRA). For the first time, we explore the potential of reusing diverse pre-tuned LoRAs without accessing their original training data, to achieve tuning-free few-shot adaptation in VFMs. Our framework, LoRA Recycle, distills a meta-LoRA from diverse pre-tuned LoRAs with a meta-learning objective, using surrogate data generated inversely from pre-tuned LoRAs themselves. The VFM, once equipped with the meta-LoRA, is empowered to solve new few-shot tasks in a single forward pass, akin to the in-context learning of LLMs. Additionally, we incorporate a double-efficient mechanism tailored to our framework, significantly accelerating the meta-training process while maintaining or even improving performance. Extensive experiments across various few-shot classification benchmarks across both in- and cross-domain scenarios demonstrate the superiority of our framework.
Coding for Intelligence from the Perspective of Category
Jul 02, 2024



Coding, which targets compressing and reconstructing data, and intelligence, often regarded at an abstract computational level as being centered around model learning and prediction, interweave recently to give birth to a series of significant progress. The recent trends demonstrate the potential homogeneity of these two fields, especially when deep-learning models aid these two categories for better probability modeling. For better understanding and describing from a unified perspective, inspired by the basic generally recognized principles in cognitive psychology, we formulate a novel problem of Coding for Intelligence from the category theory view. Based on the three axioms: existence of ideal coding, existence of practical coding, and compactness promoting generalization, we derive a general framework to understand existing methodologies, namely that, coding captures the intrinsic relationships of objects as much as possible, while ignoring information irrelevant to downstream tasks. This framework helps identify the challenges and essential elements in solving the specific derived Minimal Description Length (MDL) optimization problem from a broader range, providing opportunities to build a more intelligent system for handling multiple tasks/applications with coding ideas/tools. Centering on those elements, we systematically review recent processes of towards optimizing the MDL problem in more comprehensive ways from data, model, and task perspectives, and reveal their impacts on the potential CfI technical routes. After that, we also present new technique paths to fulfill CfI and provide potential solutions with preliminary experimental evidence. Last, further directions and remaining issues are discussed as well. The discussion shows our theory can reveal many phenomena and insights about large foundation models, which mutually corroborate with recent practices in feature learning.
Task Groupings Regularization: Data-Free Meta-Learning with Heterogeneous Pre-trained Models
May 26, 2024
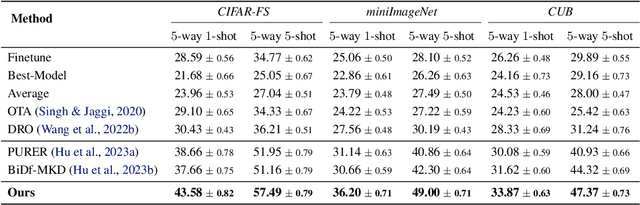

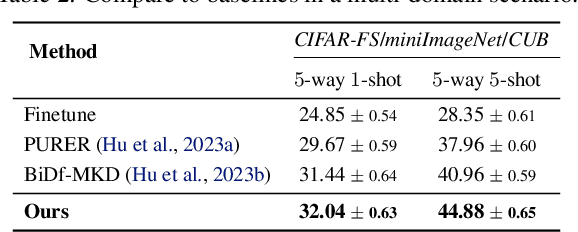
Data-Free Meta-Learning (DFML) aims to derive knowledge from a collection of pre-trained models without accessing their original data, enabling the rapid adaptation to new unseen tasks. Current methods often overlook the heterogeneity among pre-trained models, which leads to performance degradation due to task conflicts. In this paper, we empirically and theoretically identify and analyze the model heterogeneity in DFML. We find that model heterogeneity introduces a heterogeneity-homogeneity trade-off, where homogeneous models reduce task conflicts but also increase the overfitting risk. Balancing this trade-off is crucial for learning shared representations across tasks. Based on our findings, we propose Task Groupings Regularization, a novel approach that benefits from model heterogeneity by grouping and aligning conflicting tasks. Specifically, we embed pre-trained models into a task space to compute dissimilarity, and group heterogeneous models together based on this measure. Then, we introduce implicit gradient regularization within each group to mitigate potential conflicts. By encouraging a gradient direction suitable for all tasks, the meta-model captures shared representations that generalize across tasks. Comprehensive experiments showcase the superiority of our approach in multiple benchmarks, effectively tackling the model heterogeneity in challenging multi-domain and multi-architecture scenarios.
FREE: Faster and Better Data-Free Meta-Learning
May 02, 2024Data-Free Meta-Learning (DFML) aims to extract knowledge from a collection of pre-trained models without requiring the original data, presenting practical benefits in contexts constrained by data privacy concerns. Current DFML methods primarily focus on the data recovery from these pre-trained models. However, they suffer from slow recovery speed and overlook gaps inherent in heterogeneous pre-trained models. In response to these challenges, we introduce the Faster and Better Data-Free Meta-Learning (FREE) framework, which contains: (i) a meta-generator for rapidly recovering training tasks from pre-trained models; and (ii) a meta-learner for generalizing to new unseen tasks. Specifically, within the module Faster Inversion via Meta-Generator, each pre-trained model is perceived as a distinct task. The meta-generator can rapidly adapt to a specific task in just five steps, significantly accelerating the data recovery. Furthermore, we propose Better Generalization via Meta-Learner and introduce an implicit gradient alignment algorithm to optimize the meta-learner. This is achieved as aligned gradient directions alleviate potential conflicts among tasks from heterogeneous pre-trained models. Empirical experiments on multiple benchmarks affirm the superiority of our approach, marking a notable speed-up (20$\times$) and performance enhancement (1.42\% $\sim$ 4.78\%) in comparison to the state-of-the-art.