 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk, Clarify, Optimize: Human-LLM Agent Collaboration for Smarter Inventory Control
Dec 31, 2025Inventory management remains a challenge for many small and medium-sized businesses that lack the expertise to deploy advanced optimization methods. This paper investigates whether Large Language Models (LLMs) can help bridge this gap. We show that employing LLMs as direct, end-to-end solvers incurs a significant "hallucination tax": a performance gap arising from the model's inability to perform grounded stochastic reasoning. To address this, we propose a hybrid agentic framework that strictly decouples semantic reasoning from mathematical calculation. In this architecture, the LLM functions as an intelligent interface, eliciting parameters from natural language and interpreting results while automatically calling rigorous algorithms to build the optimization engine. To evaluate this interactive system against the ambiguity and inconsistency of real-world managerial dialogue, we introduce the Human Imitator, a fine-tuned "digital twin" of a boundedly rational manager that enables scalable, reproducible stress-testing. Our empirical analysis reveals that the hybrid agentic framework reduces total inventory costs by 32.1% relative to an interactive baseline using GPT-4o as an end-to-end solver. Moreover, we find that providing perfect ground-truth information alone is insufficient to improve GPT-4o's performance, confirming that the bottleneck is fundamentally computational rather than informational. Our results position LLMs not as replacements for operations research, but as natural-language interfaces that make rigorous, solver-based policies accessible to non-experts.
Learning Fair And Effective Points-Based Rewards Programs
Jun 04, 2025Points-based rewards programs are a prevalent way to incentivize customer loyalty; in these programs, customers who make repeated purchases from a seller accumulate points, working toward eventual redemption of a free reward. These programs have recently come under scrutiny due to accusations of unfair practices in their implementation. Motivated by these concerns, we study the problem of fairly designing points-based rewards programs, with a focus on two obstacles that put fairness at odds with their effectiveness. First, due to customer heterogeneity, the seller should set different redemption thresholds for different customers to generate high revenue. Second, the relationship between customer behavior and the number of accumulated points is typically unknown; this requires experimentation which may unfairly devalue customers' previously earned points. We first show that an individually fair rewards program that uses the same redemption threshold for all customers suffers a loss in revenue of at most a factor of $1+\ln 2$, compared to the optimal personalized strategy that differentiates between customers. We then tackle the problem of designing temporally fair learning algorithms in the presence of demand uncertainty. Toward this goal, we design a learning algorithm that limits the risk of point devaluation due to experimentation by only changing the redemption threshold $O(\log T)$ times, over a horizon of length $T$. This algorithm achieves the optimal (up to polylogarithmic factors) $\widetilde{O}(\sqrt{T})$ regret in expectation. We then modify this algorithm to only ever decrease redemption thresholds, leading to improved fairness at a cost of only a constant factor in regret. Extensive numerical experiments show the limited value of personalization in average-case settings, in addition to demonstrating the strong practical performance of our proposed learning algorithms.
Beyond Entropy: Region Confidence Proxy for Wild Test-Time Adaptation
May 27, 2025Wild Test-Time Adaptation (WTTA) is proposed to adapt a source model to unseen domains under extreme data scarcity and multiple shifts. Previous approaches mainly focused on sample selection strategies, while overlooking the fundamental problem on underlying optimization. Initially, we critically analyze the widely-adopted entropy minimization framework in WTTA and uncover its significant limitations in noisy optimization dynamics that substantially hinder adaptation efficiency. Through our analysis, we identify region confidence as a superior alternative to traditional entropy, however, its direct optimization remains computationally prohibitive for real-time applications. In this paper, we introduce a novel region-integrated method ReCAP that bypasses the lengthy process. Specifically, we propose a probabilistic region modeling scheme that flexibly captures semantic changes in embedding space. Subsequently, we develop a finite-to-infinite asymptotic approximation that transforms the intractable region confidence into a tractable and upper-bounded proxy. These innovations significantly unlock the overlooked potential dynamics in local region in a concise solution. Our extensive experiments demonstrate the consistent superiority of ReCAP over existing methods across various datasets and wild scenarios.
SEVA: Leveraging Single-Step Ensemble of Vicinal Augmentations for Test-Time Adaptation
May 07, 2025Test-Time adaptation (TTA) aims to enhance model robustness against distribution shifts through rapid model adaptation during inference. While existing TTA methods often rely on entropy-based unsupervised training and achieve promising results, the common practice of a single round of entropy training is typically unable to adequately utilize reliable samples, hindering adaptation efficiency. In this paper, we discover augmentation strategies can effectively unleash the potential of reliable samples, but the rapidly growing computational cost impedes their real-time application. To address this limitation, we propose a novel TTA approach named Single-step Ensemble of Vicinal Augmentations (SEVA), which can take advantage of data augmentations without increasing the computational burden. Specifically, instead of explicitly utilizing the augmentation strategy to generate new data, SEVA develops a theoretical framework to explore the impacts of multiple augmentations on model adaptation and proposes to optimize an upper bound of the entropy loss to integrate the effects of multiple rounds of augmentation training into a single step. Furthermore, we discover and verify that using the upper bound as the loss is more conducive to the selection mechanism, as it can effectively filter out harmful samples that confuse the model. Combining these two key advantages, the proposed efficient loss and a complementary selection strategy can simultaneously boost the potential of reliable samples and meet the stringent time requirements of TTA. The comprehensive experiments on various network architectures across challenging testing scenarios demonstrate impressive performances and the broad adaptability of SEVA. The code will be publicly available.
Contextual Linear Optimization with Bandit Feedback
May 26, 2024Contextual linear optimization (CLO) uses predictive observations to reduce uncertainty in random cost coefficients and thereby improve average-cost performance. An example is a stochastic shortest path with random edge costs (e.g., traffic) and predictive features (e.g., lagged traffic, weather). Existing work on CLO assumes the data has fully observed cost coefficient vectors, but in many applications, we can only see the realized cost of a historical decision, that is, just one projection of the random cost coefficient vector, to which we refer as bandit feedback. We study a class of algorithms for CLO with bandit feedback, which we term induced empirical risk minimization (IERM), where we fit a predictive model to directly optimize the downstream performance of the policy it induces. We show a fast-rate regret bound for IERM that allows for misspecified model classes and flexible choices of the optimization estimate, and we develop computationally tractable surrogate losses. A byproduct of our theory of independent interest is fast-rate regret bound for IERM with full feedback and misspecified policy class. We compare the performance of different modeling choices numerically using a stochastic shortest path example and provide practical insights from the empirical results.
Practical Policy Optimization with Personalized Experimentation
Mar 30, 2023

Many organizations measure treatment effects via an experimentation platform to evaluate the casual effect of product variations prior to full-scale deployment. However, standard experimentation platforms do not perform optimally for end user populations that exhibit heterogeneous treatment effects (HTEs). Here we present a personalized experimentation framework, Personalized Experiments (PEX), which optimizes treatment group assignment at the user level via HTE modeling and sequential decision policy optimization to optimize multiple short-term and long-term outcomes simultaneously. We describe an end-to-end workflow that has proven to be successful in practice and can be readily implemented using open-source software.
Fast Rates for the Regret of Offline Reinforcement Learning
Jan 31, 2021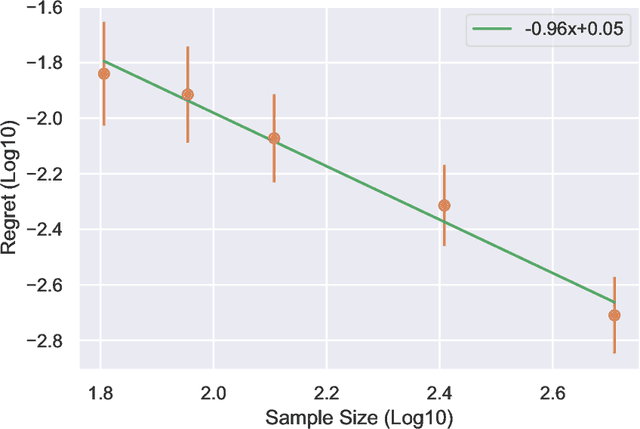
We study the regret of reinforcement learning from offline data generated by a fixed behavior policy in an infinite-horizon discounted Markov decision process (MDP). While existing analyses of common approaches, such as fitted $Q$-iteration (FQI), suggest a $O(1/\sqrt{n})$ convergence for regret, empirical behavior exhibits much faster convergence. In this paper, we present a finer regret analysis that exactly characterizes this phenomenon by providing fast rates for the regret convergence. First, we show that given any estimate for the optimal quality function $Q^*$, the regret of the policy it defines converges at a rate given by the exponentiation of the $Q^*$-estimate's pointwise convergence rate, thus speeding it up. The level of exponentiation depends on the level of noise in the decision-making problem, rather than the estimation problem. We establish such noise levels for linear and tabular MDPs as examples. Second, we provide new analyses of FQI and Bellman residual minimization to establish the correct pointwise convergence guarantees. As specific cases, our results imply $O(1/n)$ regret rates in linear cases and $\exp(-\Omega(n))$ regret rates in tabular cases.
Fast Rates for Contextual Linear Optimization
Nov 05, 2020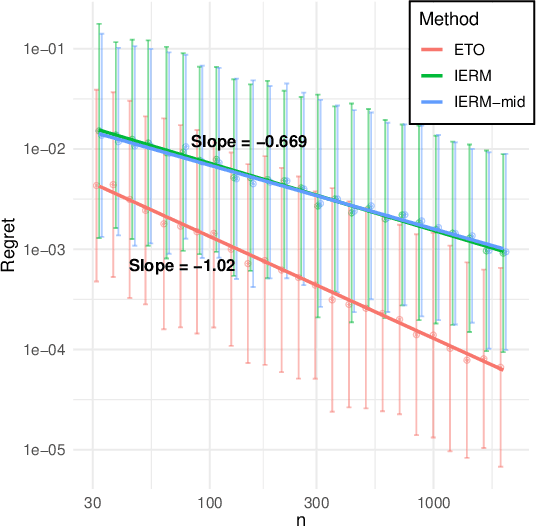
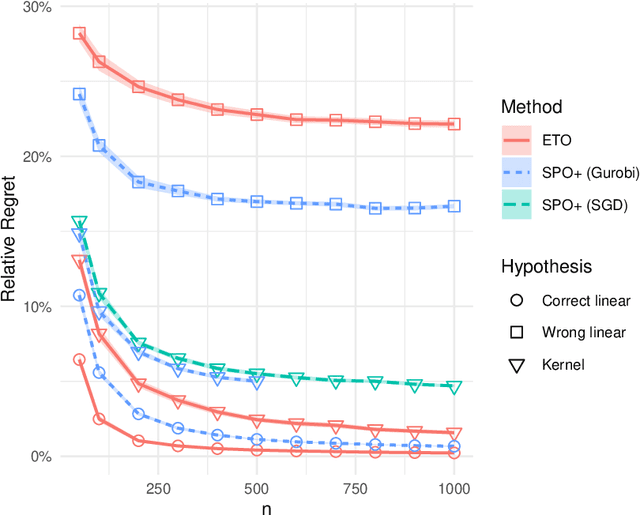
Incorporating side observations of predictive features can help reduce uncertainty in operational decision making, but it also requires we tackle a potentially complex predictive relationship. Although one may use a variety of off-the-shelf machine learning methods to learn a predictive model and then plug it into our decision-making problem, a variety of recent work has instead advocated integrating estimation and optimization by taking into consideration downstream decision performance. Surprisingly, in the case of contextual linear optimization, we show that the naive plug-in approach actually achieves regret convergence rates that are significantly faster than the best-possible by methods that directly optimize down-stream decision performance. We show this by leveraging the fact that specific problem instances do not have arbitrarily bad near-degeneracy. While there are other pros and cons to consider as we discuss, our results highlight a very nuanced landscape for the enterprise to integrate estimation and optimization.
DTR Bandit: Learning to Make Response-Adaptive Decisions With Low Regret
Jun 05, 2020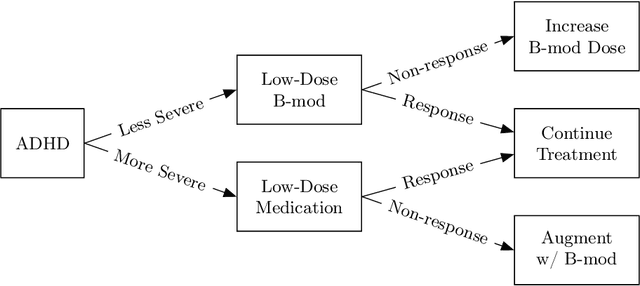
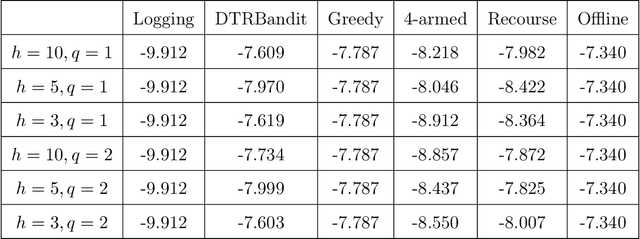
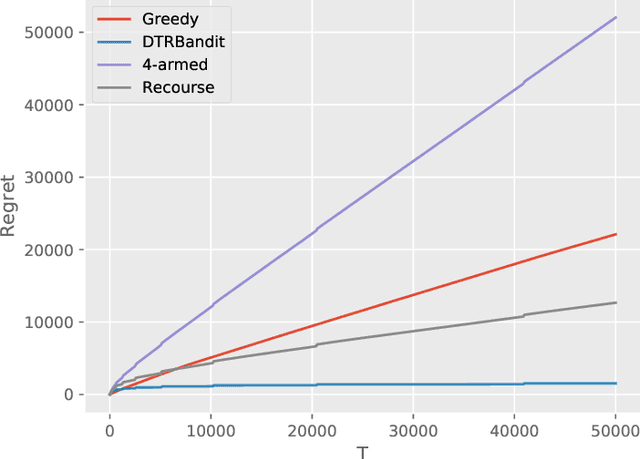
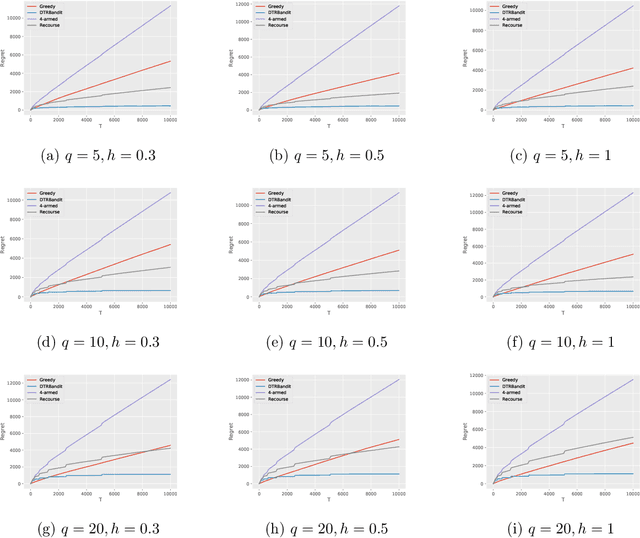
Dynamic treatment regimes (DTRs) are personalized, adaptive, multi-stage treatment plans that adapt treatment decisions both to an individual's initial features and to intermediate outcomes and features at each subsequent stage, which are affected by decisions in prior stages. Examples include personalized first- and second-line treatments of chronic conditions like diabetes, cancer, and depression, which adapt to patient response to first-line treatment, disease progression, and individual characteristics. While existing literature mostly focuses on estimating the optimal DTR from offline data such as from sequentially randomized trials, we study the problem of developing the optimal DTR in an online manner, where the interaction with each individual affect both our cumulative reward and our data collection for future learning. We term this the DTR bandit problem. We propose a novel algorithm that, by carefully balancing exploration and exploitation, is guaranteed to achieve rate-optimal regret when the transition and reward models are linear. We demonstrate our algorithm and its benefits both in synthetic experiments and in a case study of adaptive treatment of major depressive disorder using real-world data.
Smooth Contextual Bandits: Bridging the Parametric and Non-differentiable Regret Regimes
Sep 05, 2019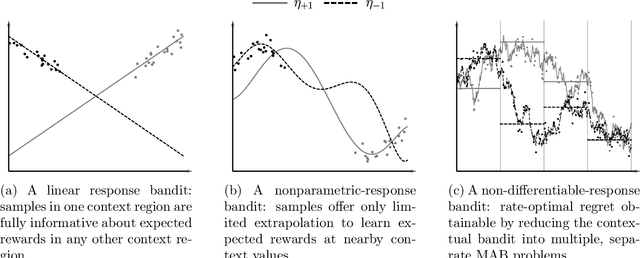

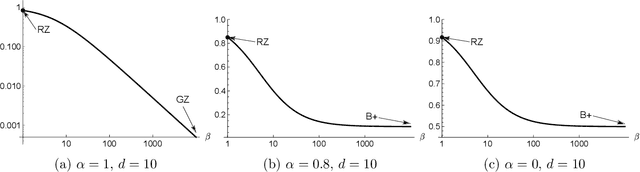
We study a nonparametric contextual bandit problem where the expected reward functions belong to a H\"older class with smoothness parameter $\beta$. We show how this interpolates between two extremes that were previously studied in isolation: non-differentiable bandits ($\beta\leq1$), where rate-optimal regret is achieved by running separate non-contextual bandits in different context regions, and parametric-response bandits ($\beta=\infty$), where rate-optimal regret can be achieved with minimal or no exploration due to infinite extrapolatability. We develop a novel algorithm that carefully adjusts to all smoothness settings and we prove its regret is rate-optimal by establishing matching upper and lower bounds, recovering the existing results at the two extremes. In this sense, our work bridges the gap between the existing literature on parametric and non-differentiable contextual bandit problems and between bandit algorithms that exclusively use global or local information, shedding light on the crucial interplay of complexity and regret in contextual bandits.