 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Learning Adaptive Priorities for Multi-Objective Alignment in Vision-Language Generation
Jan 10, 2026Multi-objective alignment for text-to-image generation is commonly implemented via static linear scalarization, but fixed weights often fail under heterogeneous rewards, leading to optimization imbalance where models overfit high-variance, high-responsiveness objectives (e.g., OCR) while under-optimizing perceptual goals. We identify two mechanistic causes: variance hijacking, where reward dispersion induces implicit reweighting that dominates the normalized training signal, and gradient conflicts, where competing objectives produce opposing update directions and trigger seesaw-like oscillations. We propose APEX (Adaptive Priority-based Efficient X-objective Alignment), which stabilizes heterogeneous rewards with Dual-Stage Adaptive Normalization and dynamically schedules objectives via P^3 Adaptive Priorities that combine learning potential, conflict penalty, and progress need. On Stable Diffusion 3.5, APEX achieves improved Pareto trade-offs across four heterogeneous objectives, with balanced gains of +1.31 PickScore, +0.35 DeQA, and +0.53 Aesthetics while maintaining competitive OCR accuracy, mitigating the instability of multi-objective alignment.
MM-R5: MultiModal Reasoning-Enhanced ReRanker via Reinforcement Learning for Document Retrieval
Jun 14, 2025Multimodal document retrieval systems enable information access across text, images, and layouts, benefiting various domains like document-based question answering, report analysis, and interactive content summarization. Rerankers improve retrieval precision by reordering retrieved candidates. However, current multimodal reranking methods remain underexplored, with significant room for improvement in both training strategies and overall effectiveness. Moreover, the lack of explicit reasoning makes it difficult to analyze and optimize these methods further. In this paper, We propose MM-R5, a MultiModal Reasoning-Enhanced ReRanker via Reinforcement Learning for Document Retrieval, aiming to provide a more effective and reliable solution for multimodal reranking tasks. MM-R5 is trained in two stages: supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we focus on improving instruction-following and guiding the model to generate complete and high-quality reasoning chains. To support this, we introduce a novel data construction strategy that produces rich, high-quality reasoning data. In the RL stage, we design a task-specific reward framework, including a reranking reward tailored for multimodal candidates and a composite template-based reward to further refine reasoning quality. We conduct extensive experiments on MMDocIR, a challenging public benchmark spanning multiple domains. MM-R5 achieves state-of-the-art performance on most metrics and delivers comparable results to much larger models on the remaining ones. Moreover, compared to the best retrieval-only method, MM-R5 improves recall@1 by over 4%. These results validate the effectiveness of our reasoning-enhanced training pipeline.
A Multi-Granularity Retrieval Framework for Visually-Rich Documents
May 06, 2025Retrieval-augmented generation (RAG) systems have predominantly focused on text-based retrieval, limiting their effectiveness in handling visually-rich documents that encompass text, images, tables, and charts. To bridge this gap, we propose a unified multi-granularity multimodal retrieval framework tailored for two benchmark tasks: MMDocIR and M2KR. Our approach integrates hierarchical encoding strategies, modality-aware retrieval mechanisms, and vision-language model (VLM)-based candidate filtering to effectively capture and utilize the complex interdependencies between textual and visual modalities. By leveraging off-the-shelf vision-language models and implementing a training-free hybrid retrieval strategy, our framework demonstrates robust performance without the need for task-specific fine-tuning. Experimental evaluations reveal that incorporating layout-aware search and VLM-based candidate verification significantly enhances retrieval accuracy, achieving a top performance score of 65.56. This work underscores the potential of scalable and reproducible solutions in advancing multimodal document retrieval systems.
A Multi-Granularity Multimodal Retrieval Framework for Multimodal Document Tasks
May 01, 2025Retrieval-augmented generation (RAG) systems have predominantly focused on text-based retrieval, limiting their effectiveness in handling visually-rich documents that encompass text, images, tables, and charts. To bridge this gap, we propose a unified multi-granularity multimodal retrieval framework tailored for two benchmark tasks: MMDocIR and M2KR. Our approach integrates hierarchical encoding strategies, modality-aware retrieval mechanisms, and reranking modules to effectively capture and utilize the complex interdependencies between textual and visual modalities. By leveraging off-the-shelf vision-language models and implementing a training-free hybridretrieval strategy, our framework demonstrates robust performance without the need for task-specific fine-tuning. Experimental evaluations reveal that incorporating layout-aware search and reranking modules significantly enhances retrieval accuracy, achieving a top performance score of 65.56. This work underscores the potential of scalable and reproducible solutions in advancing multimodal document retrieval systems.
A Survey on Point-of-Interest Recommendations Leveraging Heterogeneous Data
Aug 16, 2023Tourism is an important application domain for recommender systems. In this domain, recommender systems are for example tasked with providing personalized recommendations for transportation, accommodation, points-of-interest (POIs), or tourism services. Among these tasks, in particular the problem of recommending POIs that are of likely interest to individual tourists has gained growing attention in recent years. Providing POI recommendations to tourists \emph{during their trip} can however be especially challenging due to the variability of the users' context. With the rapid development of the Web and today's multitude of online services, vast amounts of data from various sources have become available, and these heterogeneous data sources represent a huge potential to better address the challenges of in-trip POI recommendation problems. In this work, we provide a comprehensive survey of published research on POI recommendation between 2017 and 2022 from the perspective of heterogeneous data sources. Specifically, we investigate which types of data are used in the literature and which technical approaches and evaluation methods are predominant. Among other aspects, we find that today's research works often focus on a narrow range of data sources, leaving great potential for future works that better utilize heterogeneous data sources and diverse data types for improved in-trip recommendations.
Practical Policy Optimization with Personalized Experimentation
Mar 30, 2023

Many organizations measure treatment effects via an experimentation platform to evaluate the casual effect of product variations prior to full-scale deployment. However, standard experimentation platforms do not perform optimally for end user populations that exhibit heterogeneous treatment effects (HTEs). Here we present a personalized experimentation framework, Personalized Experiments (PEX), which optimizes treatment group assignment at the user level via HTE modeling and sequential decision policy optimization to optimize multiple short-term and long-term outcomes simultaneously. We describe an end-to-end workflow that has proven to be successful in practice and can be readily implemented using open-source software.
Looper: An end-to-end ML platform for product decisions
Nov 10, 2021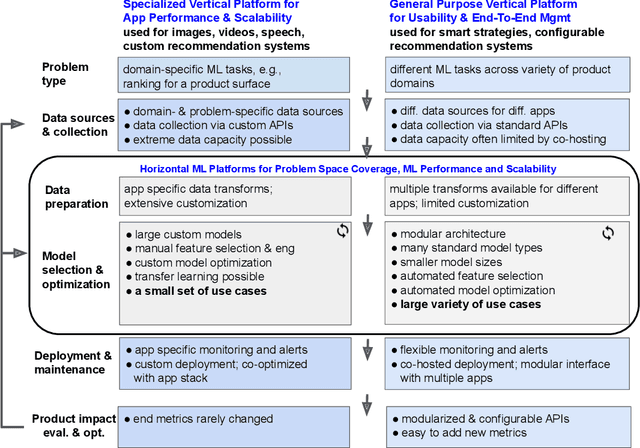
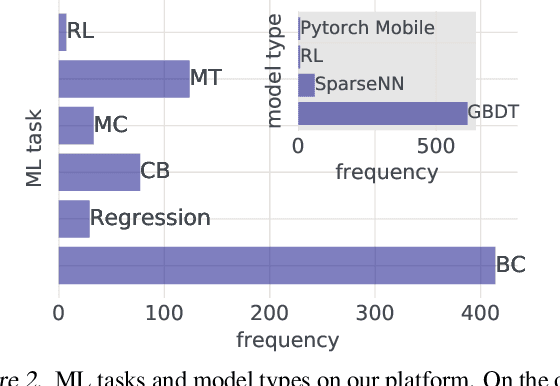
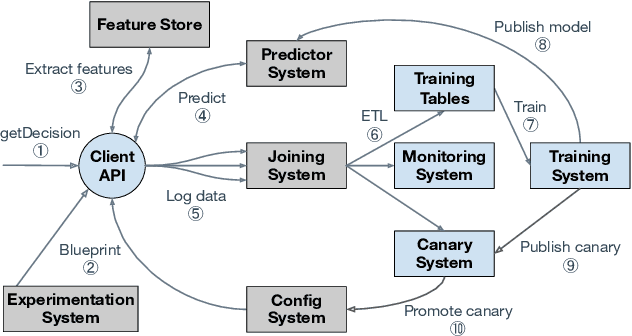
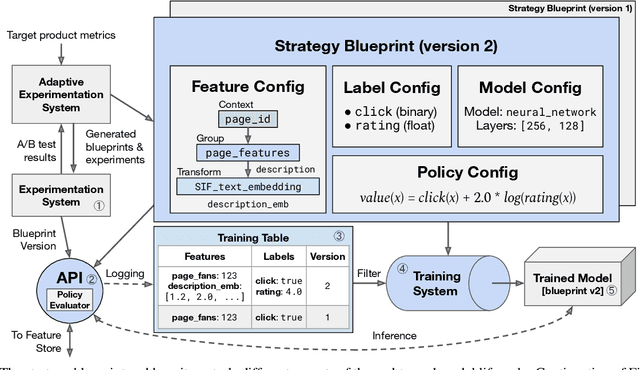
Modern software systems and products increasingly rely on machine learning models to make data-driven decisions based on interactions with users and systems, e.g., compute infrastructure. For broader adoption, this practice must (i) accommodate software engineers without ML backgrounds, and (ii) provide mechanisms to optimize for product goals. In this work, we describe general principles and a specific end-to-end ML platform, Looper, which offers easy-to-use APIs for decision-making and feedback collection. Looper supports the full end-to-end ML lifecycle from online data collection to model training, deployment, inference, and extends support to evaluation and tuning against product goals. We outline the platform architecture and overall impact of production deployment -- Looper currently hosts 700 ML models and makes 6 million decisions per second. We also describe the learning curve and summarize experiences of platform adopters.
Personalization for Web-based Services using Offline Reinforcement Learning
Feb 10, 2021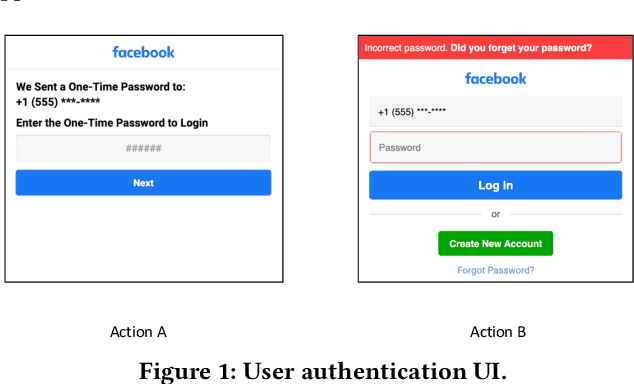

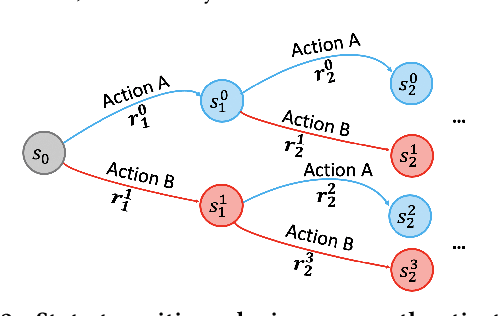
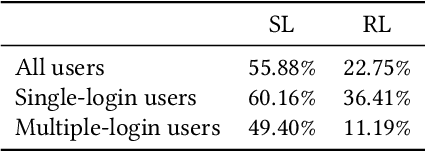
Large-scale Web-based services present opportunities for improving UI policies based on observed user interactions. We address challenges of learning such policies through model-free offline Reinforcement Learning (RL) with off-policy training. Deployed in a production system for user authentication in a major social network, it significantly improves long-term objectives. We articulate practical challenges, compare several ML techniques, provide insights on training and evaluation of RL models, and discuss generalizations.
Predictive Precompute with Recurrent Neural Networks
Dec 14, 2019
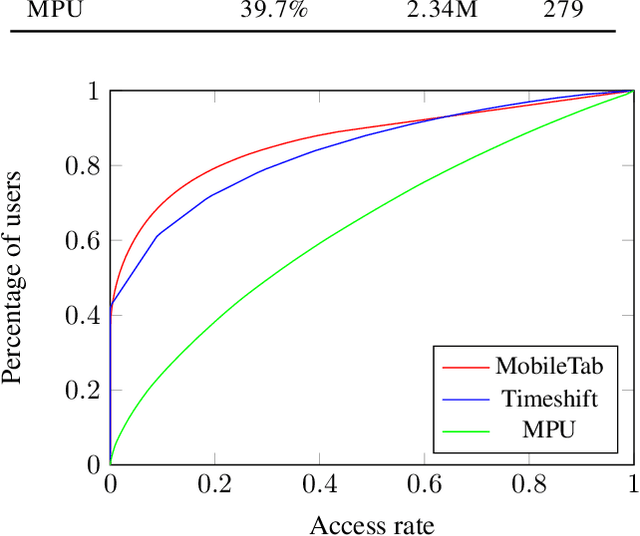
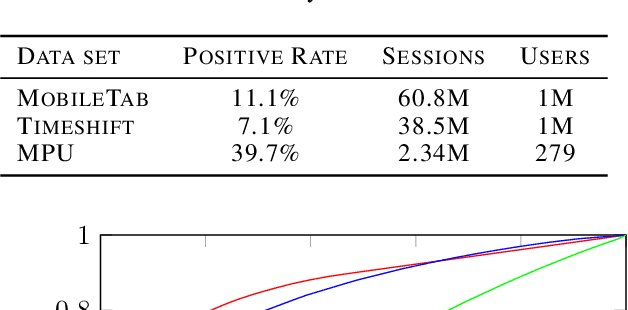
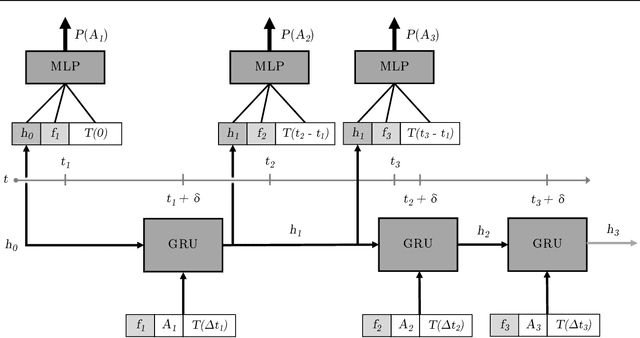
In both mobile and web applications, speeding up user interface response times can often lead to significant improvements in user engagement. A common technique to improve responsiveness is to precompute data ahead of time for specific features. However, simply precomputing data for all user and feature combinations is prohibitive at scale due to both network constraints and server-side computational costs. It is therefore important to accurately predict per-user feature usage in order to minimize wasted precomputation ("predictive precompute''). In this paper, we describe the novel application of recurrent neural networks (RNNs) for predictive precompute. We compare their performance with traditional machine learning models, and share findings from their use in a billion-user scale production environment at Facebook. We demonstrate that RNN models improve prediction accuracy, eliminate most feature engineering steps, and reduce the computational cost of serving predictions by an order of magnitude.