 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-R5: MultiModal Reasoning-Enhanced ReRanker via Reinforcement Learning for Document Retrieval
Jun 14, 2025Multimodal document retrieval systems enable information access across text, images, and layouts, benefiting various domains like document-based question answering, report analysis, and interactive content summarization. Rerankers improve retrieval precision by reordering retrieved candidates. However, current multimodal reranking methods remain underexplored, with significant room for improvement in both training strategies and overall effectiveness. Moreover, the lack of explicit reasoning makes it difficult to analyze and optimize these methods further. In this paper, We propose MM-R5, a MultiModal Reasoning-Enhanced ReRanker via Reinforcement Learning for Document Retrieval, aiming to provide a more effective and reliable solution for multimodal reranking tasks. MM-R5 is trained in two stages: supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we focus on improving instruction-following and guiding the model to generate complete and high-quality reasoning chains. To support this, we introduce a novel data construction strategy that produces rich, high-quality reasoning data. In the RL stage, we design a task-specific reward framework, including a reranking reward tailored for multimodal candidates and a composite template-based reward to further refine reasoning quality. We conduct extensive experiments on MMDocIR, a challenging public benchmark spanning multiple domains. MM-R5 achieves state-of-the-art performance on most metrics and delivers comparable results to much larger models on the remaining ones. Moreover, compared to the best retrieval-only method, MM-R5 improves recall@1 by over 4%. These results validate the effectiveness of our reasoning-enhanced training pipeline.
Implicit assessment of language learning during practice as accurate as explicit testing
Sep 24, 2024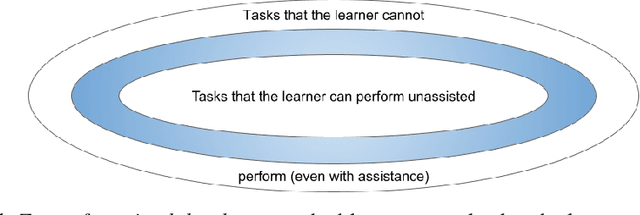
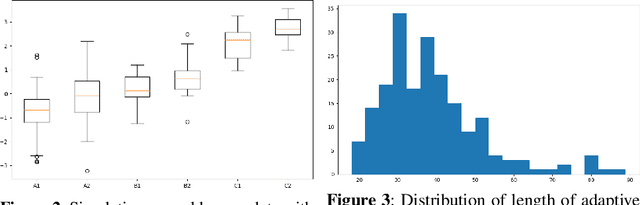
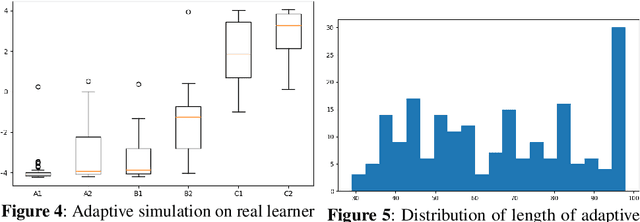
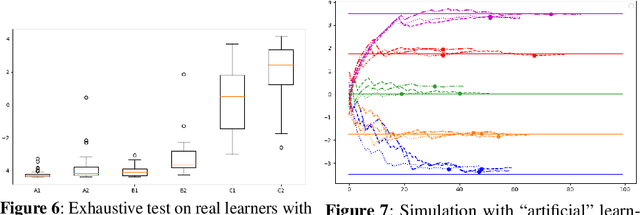
Assessment of proficiency of the learner is an essential part of Intelligent Tutoring Systems (ITS). We use Item Response Theory (IRT) in computer-aided language learning for assessment of student ability in two contexts: in test sessions, and in exercises during practice sessions. Exhaustive testing across a wide range of skills can provide a detailed picture of proficiency, but may be undesirable for a number of reasons. Therefore, we first aim to replace exhaustive tests with efficient but accurate adaptive tests. We use learner data collected from exhaustive tests under imperfect conditions, to train an IRT model to guide adaptive tests. Simulations and experiments with real learner data confirm that this approach is efficient and accurate. Second, we explore whether we can accurately estimate learner ability directly from the context of practice with exercises, without testing. We transform learner data collected from exercise sessions into a form that can be used for IRT modeling. This is done by linking the exercises to {\em linguistic constructs}; the constructs are then treated as "items" within IRT. We present results from large-scale studies with thousands of learners. Using teacher assessments of student ability as "ground truth," we compare the estimates obtained from tests vs. those from exercises. The experiments confirm that the IRT models can produce accurate ability estimation based on exercises.
What do Transformers Know about Government?
Apr 22, 2024
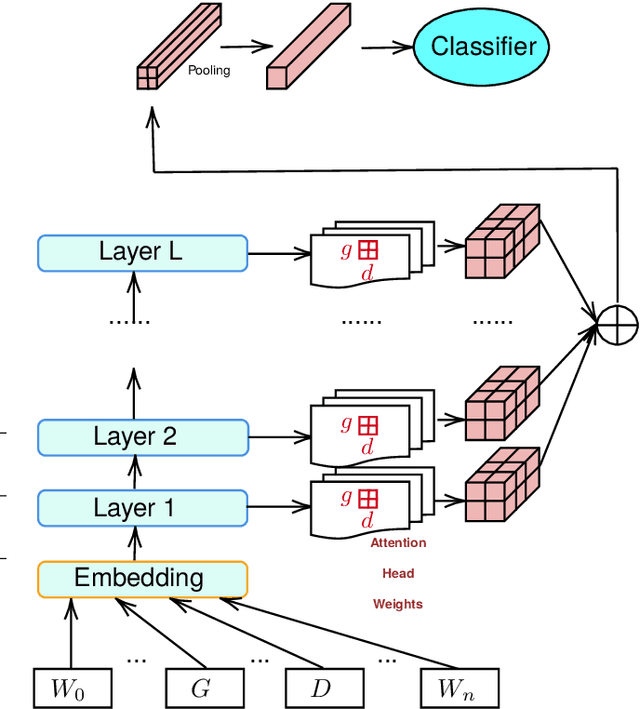
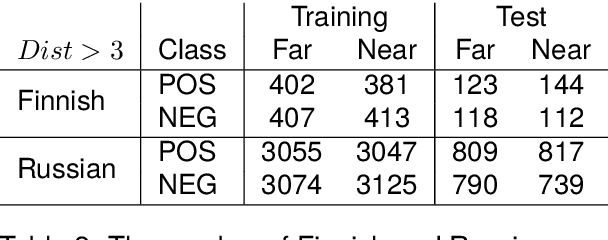
This paper investigates what insights about linguistic features and what knowledge about the structure of natural language can be obtained from the encodings in transformer language models.In particular, we explore how BERT encodes the government relation between constituents in a sentence. We use several probing classifiers, and data from two morphologically rich languages. Our experiments show that information about government is encoded across all transformer layers, but predominantly in the early layers of the model. We find that, for both languages, a small number of attention heads encode enough information about the government relations to enable us to train a classifier capable of discovering new, previously unknown types of government, never seen in the training data. Currently, data is lacking for the research community working on grammatical constructions, and government in particular. We release the Government Bank -- a dataset defining the government relations for thousands of lemmas in the languages in our experiments.
LATTE: Label-efficient Incident Phenotyping from Longitudinal Electronic Health Records
May 19, 2023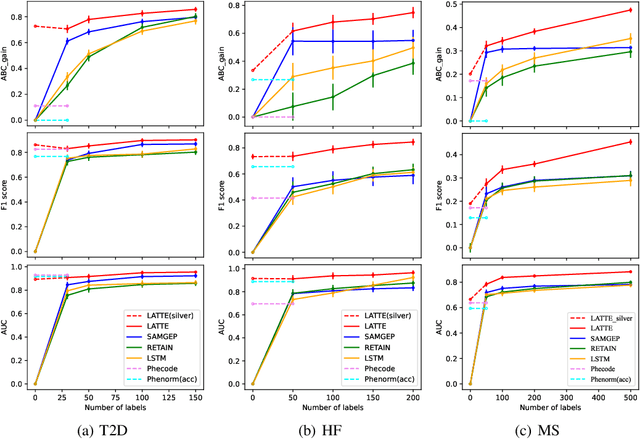
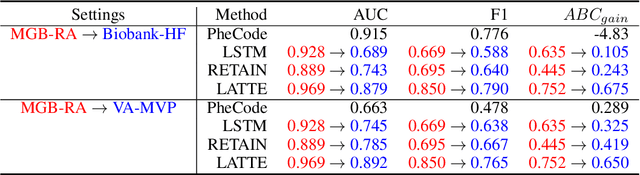

Electronic health record (EHR) data are increasingly used to support real-world evidence (RWE) studies. Yet its ability to generate reliable RWE is limited by the lack of readily available precise information on the timing of clinical events such as the onset time of heart failure. We propose a LAbel-efficienT incidenT phEnotyping (LATTE) algorithm to accurately annotate the timing of clinical events from longitudinal EHR data. By leveraging the pre-trained semantic embedding vectors from large-scale EHR data as prior knowledge, LATTE selects predictive EHR features in a concept re-weighting module by mining their relationship to the target event and compresses their information into longitudinal visit embeddings through a visit attention learning network. LATTE employs a recurrent neural network to capture the sequential dependency between the target event and visit embeddings before/after it. To improve label efficiency, LATTE constructs highly informative longitudinal silver-standard labels from large-scale unlabeled patients to perform unsupervised pre-training and semi-supervised joint training. Finally, LATTE enhances cross-site portability via contrastive representation learning. LATTE is evaluated on three analyses: the onset of type-2 diabetes, heart failure, and the onset and relapses of multiple sclerosis. We use various evaluation metrics present in the literature including the $ABC_{gain}$, the proportion of reduction in the area between the observed event indicator and the predicted cumulative incidences in reference to the prediction per incident prevalence. LATTE consistently achieves substantial improvement over benchmark methods such as SAMGEP and RETAIN in all settings.
Investigating the effect of sub-word segmentation on the performance of transformer language models
May 09, 2023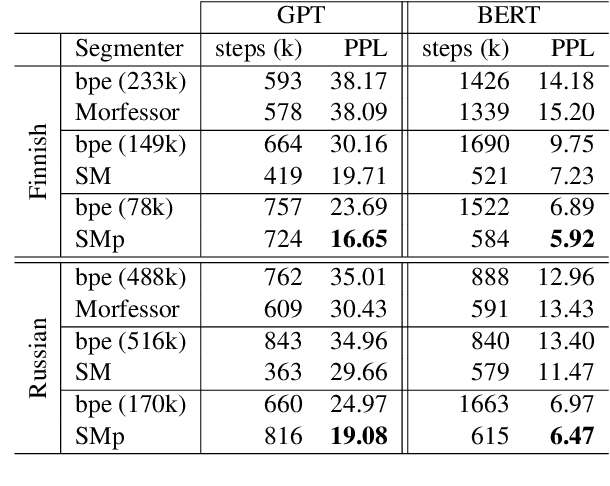
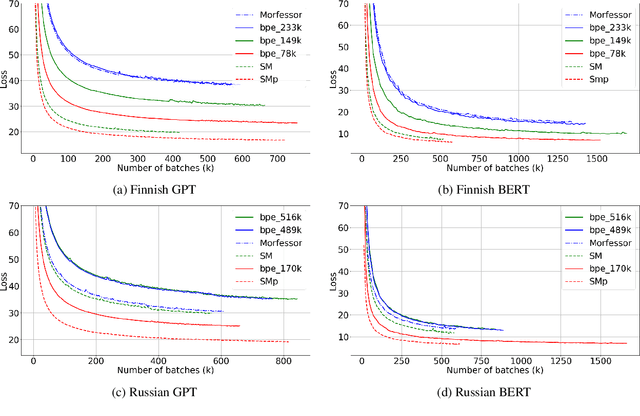
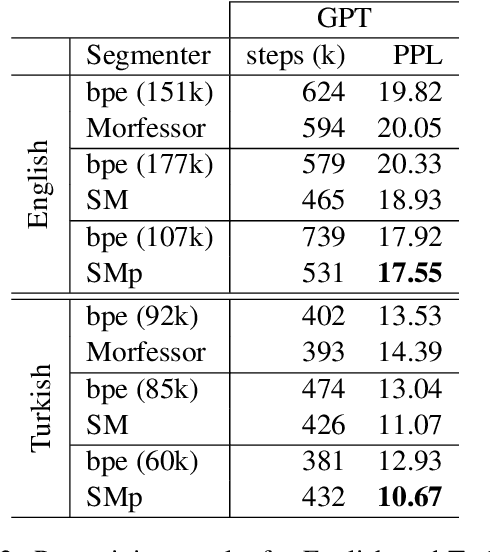
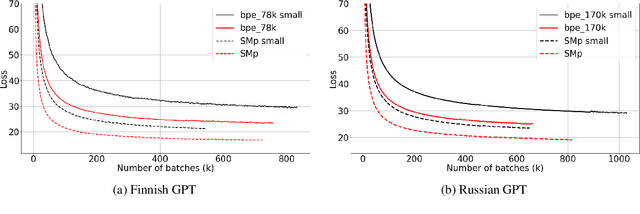
We would like to explore how morphemes can affect the performance of a language model. We trained GPT-2 and Bert model with StateMorph for both Finnish and Russian, which is a morpheme segmenting algorithm. As a comparison, we also trained a model with BPE and Morfessor. Our preliminary result shows that StateMorph can help the model to converge more efficiently and achieve a better validation score.
Linguistic Constructs as the Representation of the Domain Model in an Intelligent Language Tutoring System
Dec 03, 2022

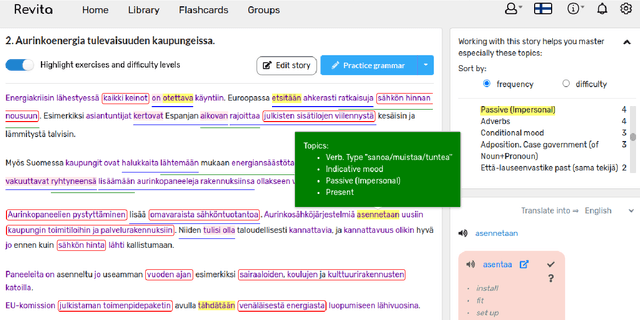
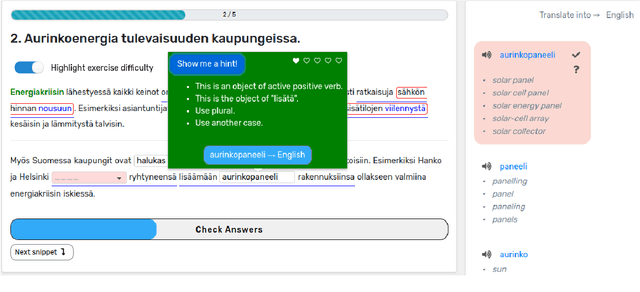
This paper presents the development of an AI-based language learning platform Revita. It is a freely available intelligent online tutor, developed to support learners of multiple languages, from low-intermediate to advanced levels. It has been in pilot use by hundreds of students at several universities, whose feedback and needs are shaping the development. One of the main emerging features of Revita is the introduction of a system of linguistic constructs as the representation of domain knowledge. The system of constructs is developed in close collaboration with experts in language teaching. Constructs define the types of exercises, the content of the feedback, and enable the detailed modeling and evaluation of learning progress.
High-Resolution Boundary Detection for Medical Image Segmentation with Piece-Wise Two-Sample T-Test Augmented Loss
Nov 04, 2022



Deep learning methods have contributed substantially to the rapid advancement of medical image segmentation, the quality of which relies on the suitable design of loss functions. Popular loss functions, including the cross-entropy and dice losses, often fall short of boundary detection, thereby limiting high-resolution downstream applications such as automated diagnoses and procedures. We developed a novel loss function that is tailored to reflect the boundary information to enhance the boundary detection. As the contrast between segmentation and background regions along the classification boundary naturally induces heterogeneity over the pixels, we propose the piece-wise two-sample t-test augmented (PTA) loss that is infused with the statistical test for such heterogeneity. We demonstrate the improved boundary detection power of the PTA loss compared to benchmark losses without a t-test component.
Surrogate Assisted Semi-supervised Inference for High Dimensional Risk Prediction
May 04, 2021
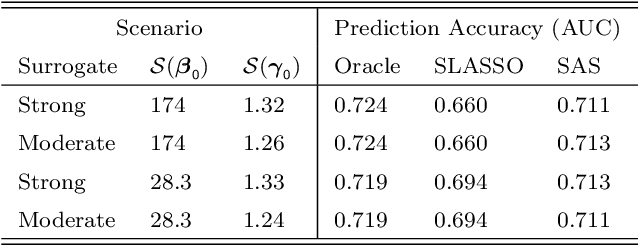
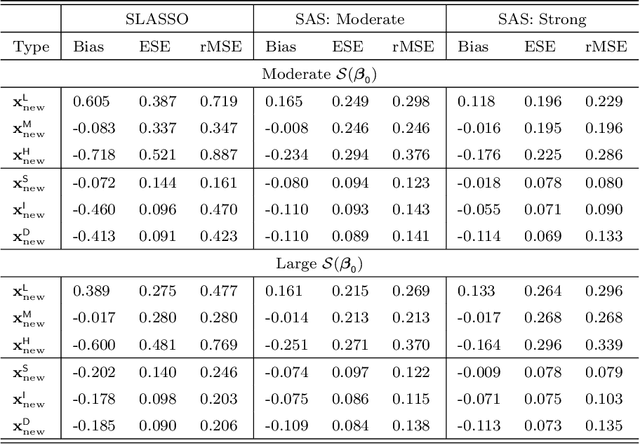
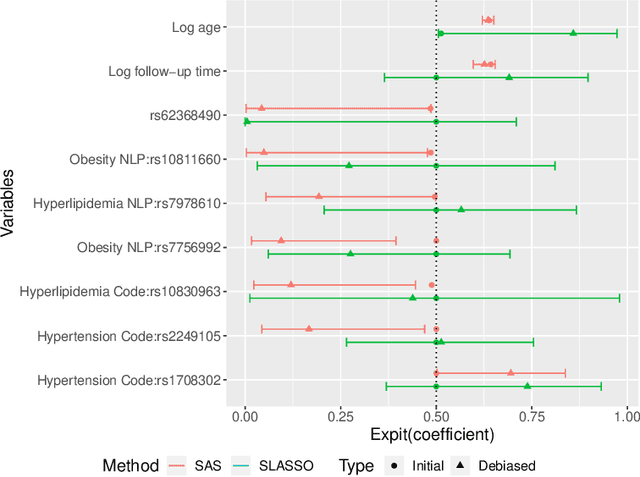
Risk modeling with EHR data is challenging due to a lack of direct observations on the disease outcome, and the high dimensionality of the candidate predictors. In this paper, we develop a surrogate assisted semi-supervised-learning (SAS) approach to risk modeling with high dimensional predictors, leveraging a large unlabeled data on candidate predictors and surrogates of outcome, as well as a small labeled data with annotated outcomes. The SAS procedure borrows information from surrogates along with candidate predictors to impute the unobserved outcomes via a sparse working imputation model with moment conditions to achieve robustness against mis-specification in the imputation model and a one-step bias correction to enable interval estimation for the predicted risk. We demonstrate that the SAS procedure provides valid inference for the predicted risk derived from a high dimensional working model, even when the underlying risk prediction model is dense and the risk model is mis-specified. We present an extensive simulation study to demonstrate the superiority of our SSL approach compared to existing supervised methods. We apply the method to derive genetic risk prediction of type-2 diabetes mellitus using a EHR biobank cohort.
Estimating Treatment Effect under Additive Hazards Models with High-dimensional Covariates
Jun 29, 2019


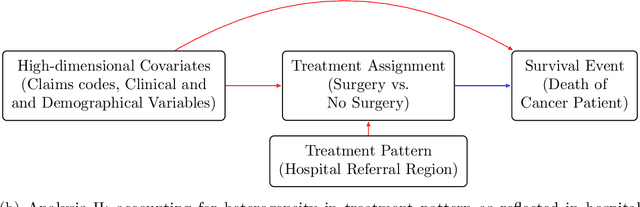
Estimating causal effects for survival outcomes in the high-dimensional setting is an extremely important topic for many biomedical applications as well as areas of social sciences. We propose a new orthogonal score method for treatment effect estimation and inference that results in asymptotically valid confidence intervals assuming only good estimation properties of the hazard outcome model and the conditional probability of treatment. This guarantee allows us to provide valid inference for the conditional treatment effect under the high-dimensional additive hazards model under considerably more generality than existing approaches. In addition, we develop a new Hazards Difference (HDi), estimator. We showcase that our approach has double-robustness properties in high dimensions: with cross-fitting, the HDi estimate is consistent under a wide variety of treatment assignment models; the HDi estimate is also consistent when the hazards model is misspecified and instead the true data generating mechanism follows a partially linear additive hazards model. We further develop a novel sparsity doubly robust result, where either the outcome or the treatment model can be a fully dense high-dimensional model. We apply our methods to study the treatment effect of radical prostatectomy versus conservative management for prostate cancer patients using the SEER-Medicare Linked Data.
Fine-Gray competing risks model with high-dimensional covariates: estimation and Inference
Jul 29, 2017



The purpose of this paper is to construct confidence intervals for the regression coefficients in the Fine-Gray model for competing risks data with random censoring, where the number of covariates can be larger than the sample size. Despite strong motivation from biostatistics applications, high-dimensional Fine-Gray model has attracted relatively little attention among the methodological or theoretical literatures. We fill in this blank by proposing first a consistent regularized estimator and then the confidence intervals based on the one-step bias-correcting estimator. We are able to generalize the partial likelihood approach for the Fine-Gray model under random censoring despite many technical difficulties. We lay down a methodological and theoretical framework for the one-step bias-correcting estimator with the partial likelihood, which does not have independent and identically distributed entries. We also handle for our theory the approximation error from the inverse probability weighting (IPW), proposing novel concentration results for time dependent processes. In addition to the theoretical results and algorithms, we present extensive numerical experiments and an application to a study of non-cancer mortality among prostate cancer patients using the linked Medicare-SEER data.