 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Tokens: A Systematic Study of Latent Action Supervision for Vision-Language-Action Models
May 06, 2026Latent actions serve as an intermediate representation that enables consistent modeling of vision-language-action (VLA) models across heterogeneous datasets. However, approaches to supervising VLAs with latent actions are fragmented and lack a systematic comparison. This work structures the study of latent action supervision from two perspectives: (i) regularizing the trajectory via image-based latent actions, and (ii) unifying the target space with action-based latent actions. Under a unified VLA baseline, we instantiate and compare four representative integration strategies. Our results reveal a formulation-task correspondence: image-based latent actions benefit long-horizon reasoning and scene-level generalization, whereas action-based latent actions excel at complex motor coordination. Furthermore, we find that directly supervising the VLM with discrete latent action tokens yields the most effective performance. Finally, our experiments offer initial insights into the benefits of latent action supervision in mixed-data, suggesting a promising direction for VLA training. Code is available at https://github.com/RUCKBReasoning/From_Pixels_to_Tokens.
VisualSimpleQA: A Benchmark for Decoupled Evaluation of Large Vision-Language Models in Fact-Seeking Question Answering
Mar 09, 2025Large vision-language models (LVLMs) have demonstrated remarkable achievements, yet the generation of non-factual responses remains prevalent in fact-seeking question answering (QA). Current multimodal fact-seeking benchmarks primarily focus on comparing model outputs to ground truth answers, providing limited insights into the performance of modality-specific modules. To bridge this gap, we introduce VisualSimpleQA, a multimodal fact-seeking benchmark with two key features. First, it enables streamlined and decoupled evaluation of LVLMs in visual and linguistic modalities. Second, it incorporates well-defined difficulty criteria to guide human annotation and facilitates the extraction of a challenging subset, VisualSimpleQA-hard. Experiments on 15 LVLMs show that even state-of-the-art models such as GPT-4o achieve merely 60%+ correctness in multimodal fact-seeking QA on VisualSimpleQA and 30%+ on VisualSimpleQA-hard. Furthermore, the decoupled evaluation across these models highlights substantial opportunities for improvement in both visual and linguistic modules. The dataset is available at https://huggingface.co/datasets/WYLing/VisualSimpleQA.
MobileExperts: A Dynamic Tool-Enabled Agent Team in Mobile Devices
Jul 04, 2024



The attainment of autonomous operations in mobile computing devices has consistently been a goal of human pursuit. With the development of Large Language Models (LLMs) and Visual Language Models (VLMs), this aspiration is progressively turning into reality. While contemporary research has explored automation of simple tasks on mobile devices via VLMs, there remains significant room for improvement in handling complex tasks and reducing high reasoning costs. In this paper, we introduce MobileExperts, which for the first time introduces tool formulation and multi-agent collaboration to address the aforementioned challenges. More specifically, MobileExperts dynamically assembles teams based on the alignment of agent portraits with the human requirements. Following this, each agent embarks on an independent exploration phase, formulating its tools to evolve into an expert. Lastly, we develop a dual-layer planning mechanism to establish coordinate collaboration among experts. To validate our effectiveness, we design a new benchmark of hierarchical intelligence levels, offering insights into algorithm's capability to address tasks across a spectrum of complexity. Experimental results demonstrate that MobileExperts performs better on all intelligence levels and achieves ~ 22% reduction in reasoning costs, thus verifying the superiority of our design.
UFDA: Universal Federated Domain Adaptation with Practical Assumptions
Nov 27, 2023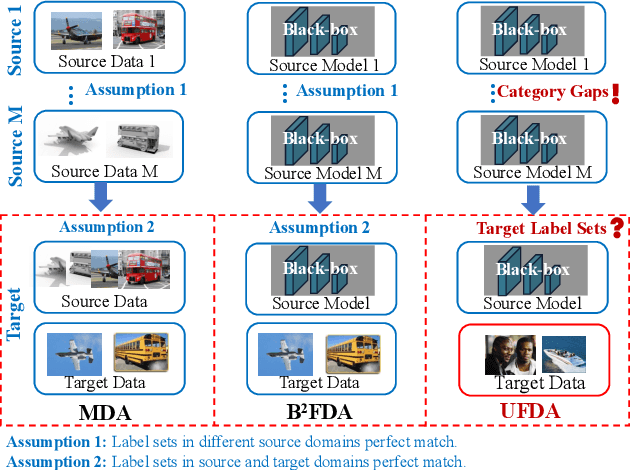
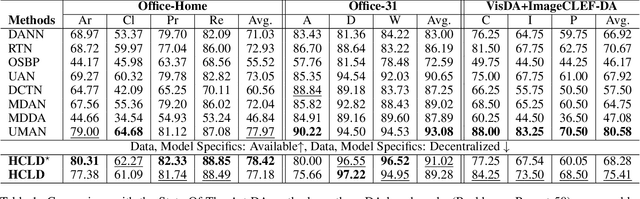
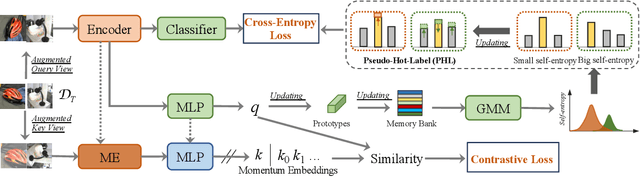
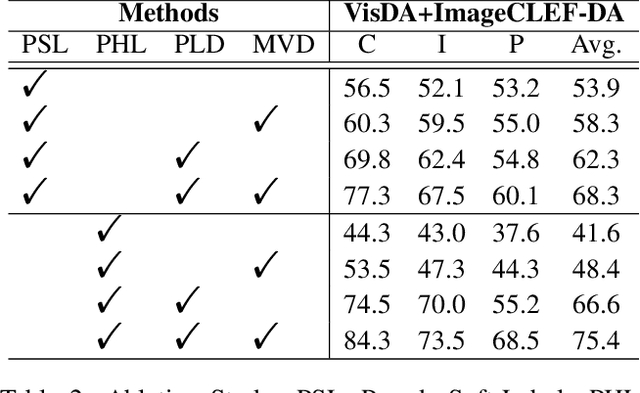
Conventional Federated Domain Adaptation (FDA) approaches usually demand an abundance of assumptions, such as label set consistency, which makes them significantly less feasible for real-world situations and introduces security hazards. In this work, we propose a more practical scenario named Universal Federated Domain Adaptation (UFDA). It only requires the black-box model and the label set information of each source domain, while the label sets of different source domains could be inconsistent and the target-domain label set is totally blind. This relaxes the assumptions made by FDA, which are often challenging to meet in real-world cases and diminish model security. To address the UFDA scenario, we propose a corresponding framework called Hot-Learning with Contrastive Label Disambiguation (HCLD), which tackles UFDA's domain shifts and category gaps problem by using one-hot outputs from the black-box models of various source domains. Moreover, to better distinguish the shared and unknown classes, we further present a cluster-level strategy named Mutual-Voting Decision (MVD) to extract robust consensus knowledge across peer classes from both source and target domains. The extensive experiments on three benchmarks demonstrate that our HCLD achieves comparable performance for our UFDA scenario with much fewer assumptions, compared to the previous methodologies with many additional assumptions.
LATTE: Label-efficient Incident Phenotyping from Longitudinal Electronic Health Records
May 19, 2023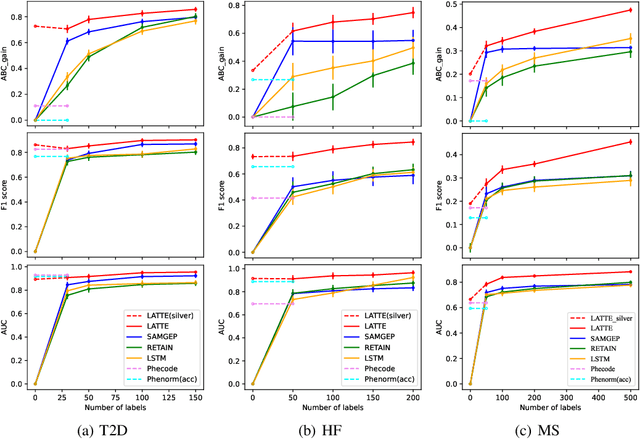
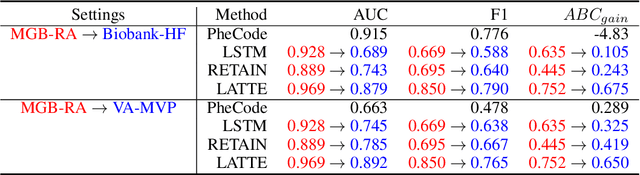
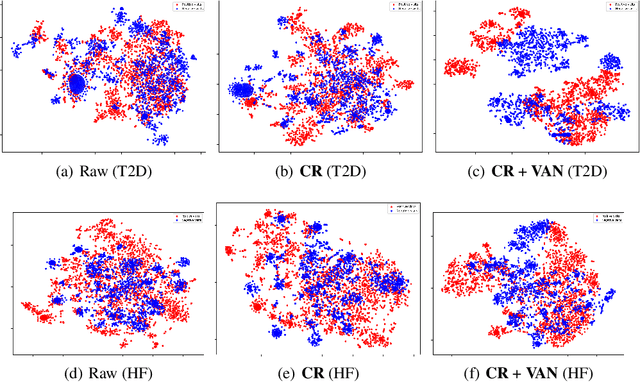

Electronic health record (EHR) data are increasingly used to support real-world evidence (RWE) studies. Yet its ability to generate reliable RWE is limited by the lack of readily available precise information on the timing of clinical events such as the onset time of heart failure. We propose a LAbel-efficienT incidenT phEnotyping (LATTE) algorithm to accurately annotate the timing of clinical events from longitudinal EHR data. By leveraging the pre-trained semantic embedding vectors from large-scale EHR data as prior knowledge, LATTE selects predictive EHR features in a concept re-weighting module by mining their relationship to the target event and compresses their information into longitudinal visit embeddings through a visit attention learning network. LATTE employs a recurrent neural network to capture the sequential dependency between the target event and visit embeddings before/after it. To improve label efficiency, LATTE constructs highly informative longitudinal silver-standard labels from large-scale unlabeled patients to perform unsupervised pre-training and semi-supervised joint training. Finally, LATTE enhances cross-site portability via contrastive representation learning. LATTE is evaluated on three analyses: the onset of type-2 diabetes, heart failure, and the onset and relapses of multiple sclerosis. We use various evaluation metrics present in the literature including the $ABC_{gain}$, the proportion of reduction in the area between the observed event indicator and the predicted cumulative incidences in reference to the prediction per incident prevalence. LATTE consistently achieves substantial improvement over benchmark methods such as SAMGEP and RETAIN in all settings.