 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs
Jan 16, 2026Personalized large language models (LLMs) adapt model behavior to individual users to enhance user satisfaction, yet personalization can inadvertently distort factual reasoning. We show that when personalized LLMs face factual queries, there exists a phenomenon where the model generates answers aligned with a user's prior history rather than the objective truth, resulting in personalization-induced hallucinations that degrade factual reliability and may propagate incorrect beliefs, due to representational entanglement between personalization and factual representations. To address this issue, we propose Factuality-Preserving Personalized Steering (FPPS), a lightweight inference-time approach that mitigates personalization-induced factual distortions while preserving personalized behavior. We further introduce PFQABench, the first benchmark designed to jointly evaluate factual and personalized question answering under personalization. Experiments across multiple LLM backbones and personalization methods show that FPPS substantially improves factual accuracy while maintaining personalized performance.
Discovering autonomous quantum error correction via deep reinforcement learning
Nov 16, 2025Quantum error correction is essential for fault-tolerant quantum computing. However, standard methods relying on active measurements may introduce additional errors. Autonomous quantum error correction (AQEC) circumvents this by utilizing engineered dissipation and drives in bosonic systems, but identifying practical encoding remains challenging due to stringent Knill-Laflamme conditions. In this work, we utilize curriculum learning enabled deep reinforcement learning to discover Bosonic codes under approximate AQEC framework to resist both single-photon and double-photon losses. We present an analytical solution of solving the master equation under approximation conditions, which can significantly accelerate the training process of reinforcement learning. The agent first identifies an encoded subspace surpassing the breakeven point through rapid exploration within a constrained evolutionary time-frame, then strategically fine-tunes its policy to sustain this performance advantage over extended temporal horizons. We find that the two-phase trained agent can discover the optimal set of codewords, i.e., the Fock states $\ket{4}$ and $\ket{7}$ considering the effect of both single-photon and double-photon loss. We identify that the discovered code surpasses the breakeven threshold over a longer evolution time and achieve the state-of-art performance. We also analyze the robustness of the code against the phase damping and amplitude damping noise. Our work highlights the potential of curriculum learning enabled deep reinforcement learning in discovering the optimal quantum error correct code especially in early fault-tolerant quantum systems.
LLaDA-Rec: Discrete Diffusion for Parallel Semantic ID Generation in Generative Recommendation
Nov 09, 2025Generative recommendation represents each item as a semantic ID, i.e., a sequence of discrete tokens, and generates the next item through autoregressive decoding. While effective, existing autoregressive models face two intrinsic limitations: (1) unidirectional constraints, where causal attention restricts each token to attend only to its predecessors, hindering global semantic modeling; and (2) error accumulation, where the fixed left-to-right generation order causes prediction errors in early tokens to propagate to the predictions of subsequent token. To address these issues, we propose LLaDA-Rec, a discrete diffusion framework that reformulates recommendation as parallel semantic ID generation. By combining bidirectional attention with the adaptive generation order, the approach models inter-item and intra-item dependencies more effectively and alleviates error accumulation. Specifically, our approach comprises three key designs: (1) a parallel tokenization scheme that produces semantic IDs for bidirectional modeling, addressing the mismatch between residual quantization and bidirectional architectures; (2) two masking mechanisms at the user-history and next-item levels to capture both inter-item sequential dependencies and intra-item semantic relationships; and (3) an adapted beam search strategy for adaptive-order discrete diffusion decoding, resolving the incompatibility of standard beam search with diffusion-based generation. Experiments on three real-world datasets show that LLaDA-Rec consistently outperforms both ID-based and state-of-the-art generative recommenders, establishing discrete diffusion as a new paradigm for generative recommendation.
ReInAgent: A Context-Aware GUI Agent Enabling Human-in-the-Loop Mobile Task Navigation
Oct 09, 2025



Mobile GUI agents exhibit substantial potential to facilitate and automate the execution of user tasks on mobile phones. However, exist mobile GUI agents predominantly privilege autonomous operation and neglect the necessity of active user engagement during task execution. This omission undermines their adaptability to information dilemmas including ambiguous, dynamically evolving, and conflicting task scenarios, leading to execution outcomes that deviate from genuine user requirements and preferences. To address these shortcomings, we propose ReInAgent, a context-aware multi-agent framework that leverages dynamic information management to enable human-in-the-loop mobile task navigation. ReInAgent integrates three specialized agents around a shared memory module: an information-managing agent for slot-based information management and proactive interaction with the user, a decision-making agent for conflict-aware planning, and a reflecting agent for task reflection and information consistency validation. Through continuous contextual information analysis and sustained user-agent collaboration, ReInAgent overcomes the limitation of existing approaches that rely on clear and static task assumptions. Consequently, it enables more adaptive and reliable mobile task navigation in complex, real-world scenarios. Experimental results demonstrate that ReInAgent effectively resolves information dilemmas and produces outcomes that are more closely aligned with genuine user preferences. Notably, on complex tasks involving information dilemmas, ReInAgent achieves a 25% higher success rate than Mobile-Agent-v2.
Bridging Search and Recommendation through Latent Cross Reasoning
Aug 06, 2025Search and recommendation (S&R) are fundamental components of modern online platforms, yet effectively leveraging search behaviors to improve recommendation remains a challenging problem. User search histories often contain noisy or irrelevant signals that can even degrade recommendation performance, while existing approaches typically encode S&R histories either jointly or separately without explicitly identifying which search behaviors are truly useful. Inspired by the human decision-making process, where one first identifies recommendation intent and then reasons about relevant evidence, we design a latent cross reasoning framework that first encodes user S&R histories to capture global interests and then iteratively reasons over search behaviors to extract signals beneficial for recommendation. Contrastive learning is employed to align latent reasoning states with target items, and reinforcement learning is further introduced to directly optimize ranking performance. Extensive experiments on public benchmarks demonstrate consistent improvements over strong baselines, validating the importance of reasoning in enhancing search-aware recommendation.
Benefit from Rich: Tackling Search Interaction Sparsity in Search Enhanced Recommendation
Aug 06, 2025In modern online platforms, search and recommendation (S&R) often coexist, offering opportunities for performance improvement through search-enhanced approaches. Existing studies show that incorporating search signals boosts recommendation performance. However, the effectiveness of these methods relies heavily on rich search interactions. They primarily benefit a small subset of users with abundant search behavior, while offering limited improvements for the majority of users who exhibit only sparse search activity. To address the problem of sparse search data in search-enhanced recommendation, we face two key challenges: (1) how to learn useful search features for users with sparse search interactions, and (2) how to design effective training objectives under sparse conditions. Our idea is to leverage the features of users with rich search interactions to enhance those of users with sparse search interactions. Based on this idea, we propose GSERec, a method that utilizes message passing on the User-Code Graphs to alleviate data sparsity in Search-Enhanced Recommendation. Specifically, we utilize Large Language Models (LLMs) with vector quantization to generate discrete codes, which connect similar users and thereby construct the graph. Through message passing on this graph, embeddings of users with rich search data are propagated to enhance the embeddings of users with sparse interactions. To further ensure that the message passing captures meaningful information from truly similar users, we introduce a contrastive loss to better model user similarities. The enhanced user representations are then integrated into downstream search-enhanced recommendation models. Experiments on three real-world datasets show that GSERec consistently outperforms baselines, especially for users with sparse search behaviors.
Similarity = Value? Consultation Value Assessment and Alignment for Personalized Search
Jun 17, 2025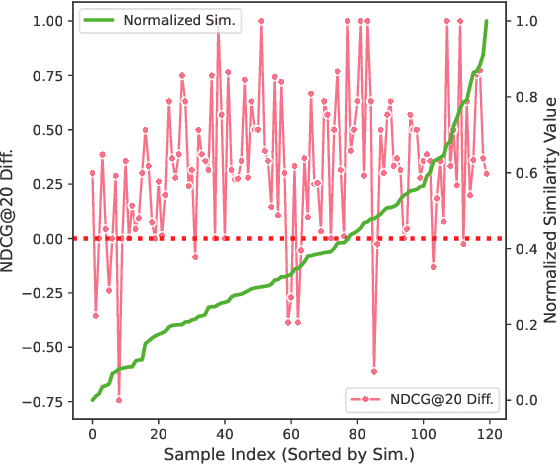

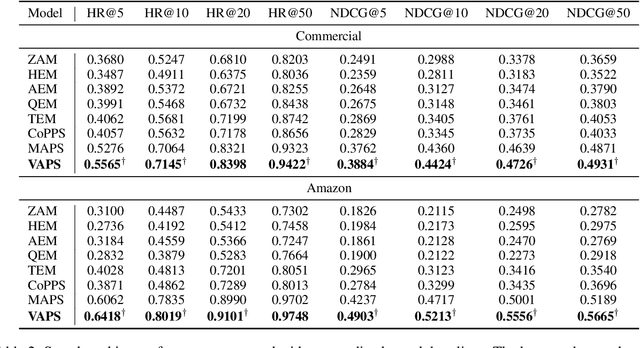
Personalized search systems in e-commerce platforms increasingly involve user interactions with AI assistants, where users consult about products, usage scenarios, and more. Leveraging consultation to personalize search services is trending. Existing methods typically rely on semantic similarity to align historical consultations with current queries due to the absence of 'value' labels, but we observe that semantic similarity alone often fails to capture the true value of consultation for personalization. To address this, we propose a consultation value assessment framework that evaluates historical consultations from three novel perspectives: (1) Scenario Scope Value, (2) Posterior Action Value, and (3) Time Decay Value. Based on this, we introduce VAPS, a value-aware personalized search model that selectively incorporates high-value consultations through a consultation-user action interaction module and an explicit objective that aligns consultations with user actions. Experiments on both public and commercial datasets show that VAPS consistently outperforms baselines in both retrieval and ranking tasks.
Attention Mechanisms Perspective: Exploring LLM Processing of Graph-Structured Data
May 04, 2025Attention mechanisms are critical to the success of large language models (LLMs), driving significant advancements in multiple fields. However, for graph-structured data, which requires emphasis on topological connections, they fall short compared to message-passing mechanisms on fixed links, such as those employed by Graph Neural Networks (GNNs). This raises a question: ``Does attention fail for graphs in natural language settings?'' Motivated by these observations, we embarked on an empirical study from the perspective of attention mechanisms to explore how LLMs process graph-structured data. The goal is to gain deeper insights into the attention behavior of LLMs over graph structures. We uncovered unique phenomena regarding how LLMs apply attention to graph-structured data and analyzed these findings to improve the modeling of such data by LLMs. The primary findings of our research are: 1) While LLMs can recognize graph data and capture text-node interactions, they struggle to model inter-node relationships within graph structures due to inherent architectural constraints. 2) The attention distribution of LLMs across graph nodes does not align with ideal structural patterns, indicating a failure to adapt to graph topology nuances. 3) Neither fully connected attention nor fixed connectivity is optimal; each has specific limitations in its application scenarios. Instead, intermediate-state attention windows improve LLM training performance and seamlessly transition to fully connected windows during inference. Source code: \href{https://github.com/millioniron/LLM_exploration}{LLM4Exploration}
The Dance of Atoms-De Novo Protein Design with Diffusion Model
Apr 23, 2025



The de novo design of proteins refers to creating proteins with specific structures and functions that do not naturally exist. In recent years, the accumulation of high-quality protein structure and sequence data and technological advancements have paved the way for the successful application of generative artificial intelligence (AI) models in protein design. These models have surpassed traditional approaches that rely on fragments and bioinformatics. They have significantly enhanced the success rate of de novo protein design, and reduced experimental costs, leading to breakthroughs in the field. Among various generative AI models, diffusion models have yielded the most promising results in protein design. In the past two to three years, more than ten protein design models based on diffusion models have emerged. Among them, the representative model, RFDiffusion, has demonstrated success rates in 25 protein design tasks that far exceed those of traditional methods, and other AI-based approaches like RFjoint and hallucination. This review will systematically examine the application of diffusion models in generating protein backbones and sequences. We will explore the strengths and limitations of different models, summarize successful cases of protein design using diffusion models, and discuss future development directions.
Decoding Recommendation Behaviors of In-Context Learning LLMs Through Gradient Descent
Apr 06, 2025Recently, there has been a growing trend in utilizing large language models (LLMs) for recommender systems, referred to as LLMRec. A notable approach within this trend is not to fine-tune these models directly but instead to leverage In-Context Learning (ICL) methods tailored for LLMRec, denoted as LLM-ICL Rec. Many contemporary techniques focus on harnessing ICL content to enhance LLMRec performance. However, optimizing LLMRec with ICL content presents unresolved challenges. Specifically, two key issues stand out: (1) the limited understanding of why using a few demonstrations without model fine-tuning can lead to better performance compared to zero-shot recommendations. (2) the lack of evaluation metrics for demonstrations in LLM-ICL Rec and the absence of the theoretical analysis and practical design for optimizing the generation of ICL content for recommendation contexts. To address these two main issues, we propose a theoretical model, the LLM-ICL Recommendation Equivalent Gradient Descent model (LRGD) in this paper, which connects recommendation generation with gradient descent dynamics. We demonstrate that the ICL inference process in LLM aligns with the training procedure of its dual model, producing token predictions equivalent to the dual model's testing outputs. Building on these theoretical insights, we propose an evaluation metric for assessing demonstration quality. We integrate perturbations and regularizations in LRGD to enhance the robustness of the recommender system. To further improve demonstration effectiveness, prevent performance collapse, and ensure long-term adaptability, we also propose a two-stage optimization process in practice. Extensive experiments and detailed analysis on three Amazon datasets validate the theoretical equivalence and support the effectiveness of our theoretical analysis and practical module design.