 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Model Editing to Generative Recommendation in Cold-Start Scenarios
Mar 15, 2026Generative recommendation (GR) has shown strong potential for sequential recommendation in an end-to-end generation paradigm. However, existing GR models suffer from severe cold-start collapse: their recommendation accuracy on cold-start items can drop to near zero. Current solutions typically rely on retraining with cold-start interactions, which is hindered by sparse feedback, high computational cost, and delayed updates, limiting practical utility in rapidly evolving recommendation catalogs. Inspired by model editing in NLP, which enables training-free knowledge injection into large language models, we explore how to bring this paradigm to generative recommendation. This, however, faces two key challenges: GR lacks the explicit subject-object binding common in natural language, making targeted edits difficult; and GR does not exhibit stable token co-occurrence patterns, making the injection of multi-token item representations unreliable. To address these challenges, we propose GenRecEdit, a model editing framework tailored for generative recommendation. GenRecEdit explicitly models the relationship between the full sequence context and next-token generation, adopts iterative token-level editing to inject multi-token item representations, and introduces a one-to-one trigger mechanism to reduce interference among multiple edits during inference. Extensive experiments on multiple datasets show that GenRecEdit substantially improves recommendation performance on cold-start items while preserving the model's original recommendation quality. Moreover, it achieves these gains using only about 9.5% of the training time required for retraining, enabling more efficient and frequent model updates.
Enhancing Bandit Algorithms with LLMs for Time-varying User Preferences in Streaming Recommendations
Feb 08, 2026In real-world streaming recommender systems, user preferences evolve dynamically over time. Existing bandit-based methods treat time merely as a timestamp, neglecting its explicit relationship with user preferences and leading to suboptimal performance. Moreover, online learning methods often suffer from inefficient exploration-exploitation during the early online phase. To address these issues, we propose HyperBandit+, a novel contextual bandit policy that integrates a time-aware hypernetwork to adapt to time-varying user preferences and employs a large language model-assisted warm-start mechanism (LLM Start) to enhance exploration-exploitation efficiency in the early online phase. Specifically, HyperBandit+ leverages a neural network that takes time features as input and generates parameters for estimating time-varying rewards by capturing the correlation between time and user preferences. Additionally, the LLM Start mechanism employs multi-step data augmentation to simulate realistic interaction data for effective offline learning, providing warm-start parameters for the bandit policy in the early online phase. To meet real-time streaming recommendation demands, we adopt low-rank factorization to reduce hypernetwork training complexity. Theoretically, we rigorously establish a sublinear regret upper bound that accounts for both the hypernetwork and the LLM warm-start mechanism. Extensive experiments on real-world datasets demonstrate that HyperBandit+ consistently outperforms state-of-the-art baselines in terms of accumulated rewards.
Deep Search with Hierarchical Meta-Cognitive Monitoring Inspired by Cognitive Neuroscience
Jan 30, 2026Deep search agents powered by large language models have demonstrated strong capabilities in multi-step retrieval, reasoning, and long-horizon task execution. However, their practical failures often stem from the lack of mechanisms to monitor and regulate reasoning and retrieval states as tasks evolve under uncertainty. Insights from cognitive neuroscience suggest that human metacognition is hierarchically organized, integrating fast anomaly detection with selectively triggered, experience-driven reflection. In this work, we propose Deep Search with Meta-Cognitive Monitoring (DS-MCM), a deep search framework augmented with an explicit hierarchical metacognitive monitoring mechanism. DS-MCM integrates a Fast Consistency Monitor, which performs lightweight checks on the alignment between external evidence and internal reasoning confidence, and a Slow Experience-Driven Monitor, which is selectively activated to guide corrective intervention based on experience memory from historical agent trajectories. By embedding monitoring directly into the reasoning-retrieval loop, DS-MCM determines both when intervention is warranted and how corrective actions should be informed by prior experience. Experiments across multiple deep search benchmarks and backbone models demonstrate that DS-MCM consistently improves performance and robustness.
When Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs
Jan 16, 2026Personalized large language models (LLMs) adapt model behavior to individual users to enhance user satisfaction, yet personalization can inadvertently distort factual reasoning. We show that when personalized LLMs face factual queries, there exists a phenomenon where the model generates answers aligned with a user's prior history rather than the objective truth, resulting in personalization-induced hallucinations that degrade factual reliability and may propagate incorrect beliefs, due to representational entanglement between personalization and factual representations. To address this issue, we propose Factuality-Preserving Personalized Steering (FPPS), a lightweight inference-time approach that mitigates personalization-induced factual distortions while preserving personalized behavior. We further introduce PFQABench, the first benchmark designed to jointly evaluate factual and personalized question answering under personalization. Experiments across multiple LLM backbones and personalization methods show that FPPS substantially improves factual accuracy while maintaining personalized performance.
LLaDA-Rec: Discrete Diffusion for Parallel Semantic ID Generation in Generative Recommendation
Nov 09, 2025Generative recommendation represents each item as a semantic ID, i.e., a sequence of discrete tokens, and generates the next item through autoregressive decoding. While effective, existing autoregressive models face two intrinsic limitations: (1) unidirectional constraints, where causal attention restricts each token to attend only to its predecessors, hindering global semantic modeling; and (2) error accumulation, where the fixed left-to-right generation order causes prediction errors in early tokens to propagate to the predictions of subsequent token. To address these issues, we propose LLaDA-Rec, a discrete diffusion framework that reformulates recommendation as parallel semantic ID generation. By combining bidirectional attention with the adaptive generation order, the approach models inter-item and intra-item dependencies more effectively and alleviates error accumulation. Specifically, our approach comprises three key designs: (1) a parallel tokenization scheme that produces semantic IDs for bidirectional modeling, addressing the mismatch between residual quantization and bidirectional architectures; (2) two masking mechanisms at the user-history and next-item levels to capture both inter-item sequential dependencies and intra-item semantic relationships; and (3) an adapted beam search strategy for adaptive-order discrete diffusion decoding, resolving the incompatibility of standard beam search with diffusion-based generation. Experiments on three real-world datasets show that LLaDA-Rec consistently outperforms both ID-based and state-of-the-art generative recommenders, establishing discrete diffusion as a new paradigm for generative recommendation.
PrLM: Learning Explicit Reasoning for Personalized RAG via Contrastive Reward Optimization
Aug 10, 2025Personalized retrieval-augmented generation (RAG) aims to produce user-tailored responses by incorporating retrieved user profiles alongside the input query. Existing methods primarily focus on improving retrieval and rely on large language models (LLMs) to implicitly integrate the retrieved context with the query. However, such models are often sensitive to retrieval quality and may generate responses that are misaligned with user preferences. To address this limitation, we propose PrLM, a reinforcement learning framework that trains LLMs to explicitly reason over retrieved user profiles. Guided by a contrastively trained personalization reward model, PrLM effectively learns from user responses without requiring annotated reasoning paths. Experiments on three personalized text generation datasets show that PrLM outperforms existing methods and remains robust across varying numbers of retrieved profiles and different retrievers.
Benefit from Rich: Tackling Search Interaction Sparsity in Search Enhanced Recommendation
Aug 06, 2025In modern online platforms, search and recommendation (S&R) often coexist, offering opportunities for performance improvement through search-enhanced approaches. Existing studies show that incorporating search signals boosts recommendation performance. However, the effectiveness of these methods relies heavily on rich search interactions. They primarily benefit a small subset of users with abundant search behavior, while offering limited improvements for the majority of users who exhibit only sparse search activity. To address the problem of sparse search data in search-enhanced recommendation, we face two key challenges: (1) how to learn useful search features for users with sparse search interactions, and (2) how to design effective training objectives under sparse conditions. Our idea is to leverage the features of users with rich search interactions to enhance those of users with sparse search interactions. Based on this idea, we propose GSERec, a method that utilizes message passing on the User-Code Graphs to alleviate data sparsity in Search-Enhanced Recommendation. Specifically, we utilize Large Language Models (LLMs) with vector quantization to generate discrete codes, which connect similar users and thereby construct the graph. Through message passing on this graph, embeddings of users with rich search data are propagated to enhance the embeddings of users with sparse interactions. To further ensure that the message passing captures meaningful information from truly similar users, we introduce a contrastive loss to better model user similarities. The enhanced user representations are then integrated into downstream search-enhanced recommendation models. Experiments on three real-world datasets show that GSERec consistently outperforms baselines, especially for users with sparse search behaviors.
Bridging Search and Recommendation through Latent Cross Reasoning
Aug 06, 2025Search and recommendation (S&R) are fundamental components of modern online platforms, yet effectively leveraging search behaviors to improve recommendation remains a challenging problem. User search histories often contain noisy or irrelevant signals that can even degrade recommendation performance, while existing approaches typically encode S&R histories either jointly or separately without explicitly identifying which search behaviors are truly useful. Inspired by the human decision-making process, where one first identifies recommendation intent and then reasons about relevant evidence, we design a latent cross reasoning framework that first encodes user S&R histories to capture global interests and then iteratively reasons over search behaviors to extract signals beneficial for recommendation. Contrastive learning is employed to align latent reasoning states with target items, and reinforcement learning is further introduced to directly optimize ranking performance. Extensive experiments on public benchmarks demonstrate consistent improvements over strong baselines, validating the importance of reasoning in enhancing search-aware recommendation.
Similarity = Value? Consultation Value Assessment and Alignment for Personalized Search
Jun 17, 2025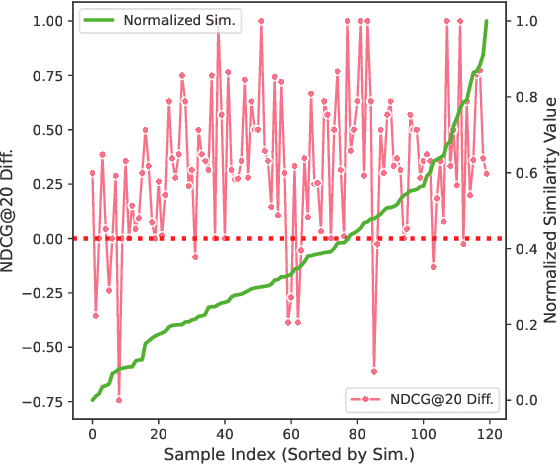

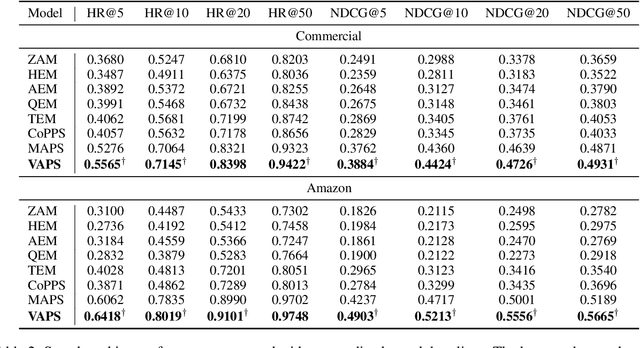
Personalized search systems in e-commerce platforms increasingly involve user interactions with AI assistants, where users consult about products, usage scenarios, and more. Leveraging consultation to personalize search services is trending. Existing methods typically rely on semantic similarity to align historical consultations with current queries due to the absence of 'value' labels, but we observe that semantic similarity alone often fails to capture the true value of consultation for personalization. To address this, we propose a consultation value assessment framework that evaluates historical consultations from three novel perspectives: (1) Scenario Scope Value, (2) Posterior Action Value, and (3) Time Decay Value. Based on this, we introduce VAPS, a value-aware personalized search model that selectively incorporates high-value consultations through a consultation-user action interaction module and an explicit objective that aligns consultations with user actions. Experiments on both public and commercial datasets show that VAPS consistently outperforms baselines in both retrieval and ranking tasks.
Decoding Recommendation Behaviors of In-Context Learning LLMs Through Gradient Descent
Apr 06, 2025Recently, there has been a growing trend in utilizing large language models (LLMs) for recommender systems, referred to as LLMRec. A notable approach within this trend is not to fine-tune these models directly but instead to leverage In-Context Learning (ICL) methods tailored for LLMRec, denoted as LLM-ICL Rec. Many contemporary techniques focus on harnessing ICL content to enhance LLMRec performance. However, optimizing LLMRec with ICL content presents unresolved challenges. Specifically, two key issues stand out: (1) the limited understanding of why using a few demonstrations without model fine-tuning can lead to better performance compared to zero-shot recommendations. (2) the lack of evaluation metrics for demonstrations in LLM-ICL Rec and the absence of the theoretical analysis and practical design for optimizing the generation of ICL content for recommendation contexts. To address these two main issues, we propose a theoretical model, the LLM-ICL Recommendation Equivalent Gradient Descent model (LRGD) in this paper, which connects recommendation generation with gradient descent dynamics. We demonstrate that the ICL inference process in LLM aligns with the training procedure of its dual model, producing token predictions equivalent to the dual model's testing outputs. Building on these theoretical insights, we propose an evaluation metric for assessing demonstration quality. We integrate perturbations and regularizations in LRGD to enhance the robustness of the recommender system. To further improve demonstration effectiveness, prevent performance collapse, and ensure long-term adaptability, we also propose a two-stage optimization process in practice. Extensive experiments and detailed analysis on three Amazon datasets validate the theoretical equivalence and support the effectiveness of our theoretical analysis and practical module design.