 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Search and Recommendation through Latent Cross Reasoning
Aug 06, 2025Search and recommendation (S&R) are fundamental components of modern online platforms, yet effectively leveraging search behaviors to improve recommendation remains a challenging problem. User search histories often contain noisy or irrelevant signals that can even degrade recommendation performance, while existing approaches typically encode S&R histories either jointly or separately without explicitly identifying which search behaviors are truly useful. Inspired by the human decision-making process, where one first identifies recommendation intent and then reasons about relevant evidence, we design a latent cross reasoning framework that first encodes user S&R histories to capture global interests and then iteratively reasons over search behaviors to extract signals beneficial for recommendation. Contrastive learning is employed to align latent reasoning states with target items, and reinforcement learning is further introduced to directly optimize ranking performance. Extensive experiments on public benchmarks demonstrate consistent improvements over strong baselines, validating the importance of reasoning in enhancing search-aware recommendation.
Similarity = Value? Consultation Value Assessment and Alignment for Personalized Search
Jun 17, 2025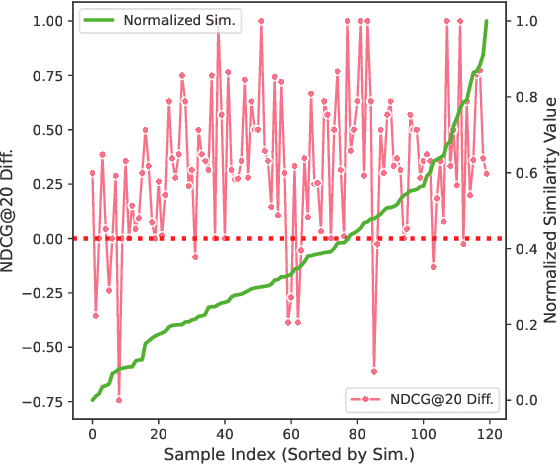

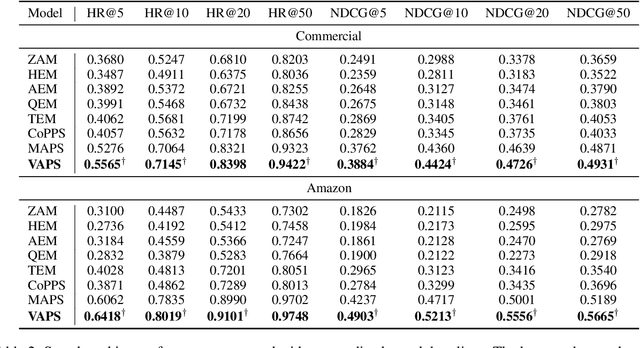
Personalized search systems in e-commerce platforms increasingly involve user interactions with AI assistants, where users consult about products, usage scenarios, and more. Leveraging consultation to personalize search services is trending. Existing methods typically rely on semantic similarity to align historical consultations with current queries due to the absence of 'value' labels, but we observe that semantic similarity alone often fails to capture the true value of consultation for personalization. To address this, we propose a consultation value assessment framework that evaluates historical consultations from three novel perspectives: (1) Scenario Scope Value, (2) Posterior Action Value, and (3) Time Decay Value. Based on this, we introduce VAPS, a value-aware personalized search model that selectively incorporates high-value consultations through a consultation-user action interaction module and an explicit objective that aligns consultations with user actions. Experiments on both public and commercial datasets show that VAPS consistently outperforms baselines in both retrieval and ranking tasks.
Decoding Recommendation Behaviors of In-Context Learning LLMs Through Gradient Descent
Apr 06, 2025Recently, there has been a growing trend in utilizing large language models (LLMs) for recommender systems, referred to as LLMRec. A notable approach within this trend is not to fine-tune these models directly but instead to leverage In-Context Learning (ICL) methods tailored for LLMRec, denoted as LLM-ICL Rec. Many contemporary techniques focus on harnessing ICL content to enhance LLMRec performance. However, optimizing LLMRec with ICL content presents unresolved challenges. Specifically, two key issues stand out: (1) the limited understanding of why using a few demonstrations without model fine-tuning can lead to better performance compared to zero-shot recommendations. (2) the lack of evaluation metrics for demonstrations in LLM-ICL Rec and the absence of the theoretical analysis and practical design for optimizing the generation of ICL content for recommendation contexts. To address these two main issues, we propose a theoretical model, the LLM-ICL Recommendation Equivalent Gradient Descent model (LRGD) in this paper, which connects recommendation generation with gradient descent dynamics. We demonstrate that the ICL inference process in LLM aligns with the training procedure of its dual model, producing token predictions equivalent to the dual model's testing outputs. Building on these theoretical insights, we propose an evaluation metric for assessing demonstration quality. We integrate perturbations and regularizations in LRGD to enhance the robustness of the recommender system. To further improve demonstration effectiveness, prevent performance collapse, and ensure long-term adaptability, we also propose a two-stage optimization process in practice. Extensive experiments and detailed analysis on three Amazon datasets validate the theoretical equivalence and support the effectiveness of our theoretical analysis and practical module design.
MAPS: Motivation-Aware Personalized Search via LLM-Driven Consultation Alignment
Mar 05, 2025Personalized product search aims to retrieve and rank items that match users' preferences and search intent. Despite their effectiveness, existing approaches typically assume that users' query fully captures their real motivation. However, our analysis of a real-world e-commerce platform reveals that users often engage in relevant consultations before searching, indicating they refine intents through consultations based on motivation and need. The implied motivation in consultations is a key enhancing factor for personalized search. This unexplored area comes with new challenges including aligning contextual motivations with concise queries, bridging the category-text gap, and filtering noise within sequence history. To address these, we propose a Motivation-Aware Personalized Search (MAPS) method. It embeds queries and consultations into a unified semantic space via LLMs, utilizes a Mixture of Attention Experts (MoAE) to prioritize critical semantics, and introduces dual alignment: (1) contrastive learning aligns consultations, reviews, and product features; (2) bidirectional attention integrates motivation-aware embeddings with user preferences. Extensive experiments on real and synthetic data show MAPS outperforms existing methods in both retrieval and ranking tasks.
Enhancing Sequential Recommendations through Multi-Perspective Reflections and Iteration
Sep 10, 2024


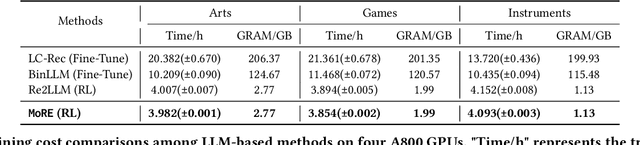
Sequence recommendation (SeqRec) aims to predict the next item a user will interact with by understanding user intentions and leveraging collaborative filtering information. Large language models (LLMs) have shown great promise in recommendation tasks through prompt-based, fixed reflection libraries, and fine-tuning techniques. However, these methods face challenges, including lack of supervision, inability to optimize reflection sources, inflexibility to diverse user needs, and high computational costs. Despite promising results, current studies primarily focus on reflections of users' explicit preferences (e.g., item titles) while neglecting implicit preferences (e.g., brands) and collaborative filtering information. This oversight hinders the capture of preference shifts and dynamic user behaviors. Additionally, existing approaches lack mechanisms for reflection evaluation and iteration, often leading to suboptimal recommendations. To address these issues, we propose the Mixture of REflectors (MoRE) framework, designed to model and learn dynamic user preferences in SeqRec. Specifically, MoRE introduces three reflectors for generating LLM-based reflections on explicit preferences, implicit preferences, and collaborative signals. Each reflector incorporates a self-improving strategy, termed refining-and-iteration, to evaluate and iteratively update reflections. Furthermore, a meta-reflector employs a contextual bandit algorithm to select the most suitable expert and corresponding reflections for each user's recommendation, effectively capturing dynamic preferences. Extensive experiments on three real-world datasets demonstrate that MoRE consistently outperforms state-of-the-art methods, requiring less training time and GPU memory compared to other LLM-based approaches in SeqRec.
Exploring the Nexus of Large Language Models and Legal Systems: A Short Survey
Apr 01, 2024With the advancement of Artificial Intelligence (AI) and Large Language Models (LLMs), there is a profound transformation occurring in the realm of natural language processing tasks within the legal domain. The capabilities of LLMs are increasingly demonstrating unique roles in the legal sector, bringing both distinctive benefits and various challenges. This survey delves into the synergy between LLMs and the legal system, such as their applications in tasks like legal text comprehension, case retrieval, and analysis. Furthermore, this survey highlights key challenges faced by LLMs in the legal domain, including bias, interpretability, and ethical considerations, as well as how researchers are addressing these issues. The survey showcases the latest advancements in fine-tuned legal LLMs tailored for various legal systems, along with legal datasets available for fine-tuning LLMs in various languages. Additionally, it proposes directions for future research and development.
Incorporating Judgment Prediction into Legal Case Retrieval via Law-aware Generative Retrieval
Dec 15, 2023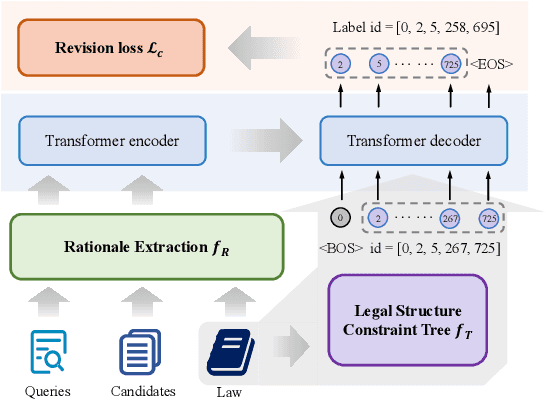
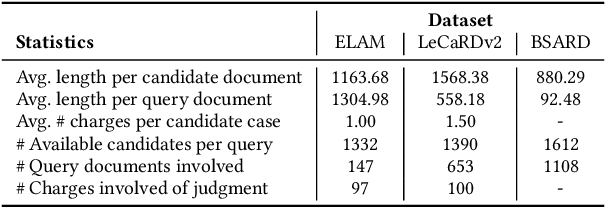
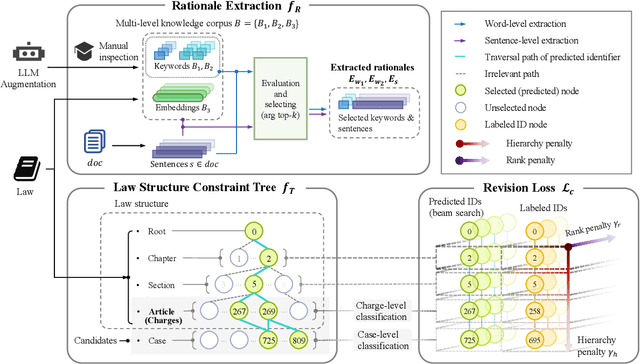
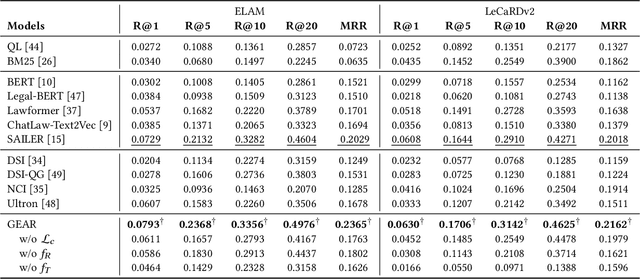
Legal case retrieval and judgment prediction are crucial components in intelligent legal systems. In practice, determining whether two cases share the same charges through legal judgment prediction is essential for establishing their relevance in case retrieval. However, current studies on legal case retrieval merely focus on the semantic similarity between paired cases, ignoring their charge-level consistency. This separation leads to a lack of context and potential inaccuracies in the case retrieval that can undermine trust in the system's decision-making process. Given the guidance role of laws to both tasks and inspired by the success of generative retrieval, in this work, we propose to incorporate judgment prediction into legal case retrieval, achieving a novel law-aware Generative legal case retrieval method called Gear. Specifically, Gear first extracts rationales (key circumstances and key elements) for legal cases according to the definition of charges in laws, ensuring a shared and informative representation for both tasks. Then in accordance with the inherent hierarchy of laws, we construct a law structure constraint tree and assign law-aware semantic identifier(s) to each case based on this tree. These designs enable a unified traversal from the root, through intermediate charge nodes, to case-specific leaf nodes, which respectively correspond to two tasks. Additionally, in the training, we also introduce a revision loss that jointly minimizes the discrepancy between the identifiers of predicted and labeled charges as well as retrieved cases, improving the accuracy and consistency for both tasks. Extensive experiments on two datasets demonstrate that Gear consistently outperforms state-of-the-art methods in legal case retrieval while maintaining competitive judgment prediction performance.