 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSRLive: Live Streaming Recommendation with Dynamic Semantic ID
Jun 05, 2026Live streaming has emerged as one of the fastest-growing forms of online media, enabling instant content broadcasting and real-time engagement between users and streamers. Despite the effectiveness of existing recommendation algorithms in this domain, they often suffer from limited utilization of computational resources, with low FLOPs that hinder further performance enhancement. Generative recommendation techniques, which have gained traction in various industrial tasks, offer a promising avenue for improving live streaming recommendations. However, directly applying generative methods to live streaming is non-trivial due to two major challenges: (1) static semantic IDs (SIDs) cannot reflect the rapidly changing nature of live room content; and (2) generative pipelines generally do not incorporate user--streamer interaction signals (e.g., likes, orders), which are critical for modeling user intent toward both the streamer and showcased products. To address these challenges, we introduce SSRLive: Dynamic Semantic ID-guided Streaming Recommendation for Live platforms. The proposed framework integrates a generative module and a discriminative module in a unified architecture. The generative component employs an encoder-decoder design to produce both static and dynamic SIDs, enabling timely representation of live room content while leveraging multimodal information. The discriminative component refines task-specific representations by combining SIDs with user features, augments them with user-streamer interaction data, and performs multi-task predictions. Online A/B tests in real-world deployment demonstrate tangible benefits: watch time (+3.38%), GMV (+0.72%), follower growth (+3.12%), and interaction volume (+2.92%). These improvements highlight the effectiveness and business value of SSRLive, which is now fully deployed, serving hundreds of millions of active users.
OneReason Technical Report
Jun 04, 2026Generative recommendation models in the OneRec family have been widely deployed in many real-world services, such as short-video, live-streaming, advertising, and e-commerce. However, these generative models can only benefit from the scaling advantage, while their reasoning ability is hard to activate, since we cannot construct meaningful Chain-of-Thought (CoT) sequences consisting of itemic tokens only. Inspired by the success of the reasoning-style ``think before answer'' paradigm in the LLM field, we conduct preliminary studies (i.e., OneRec-Think, OpenOneRec) to explore reasoning capability in generative recommendation. Nevertheless, we notice an unexpected phenomenon: the thinking mode does not show advantages over the non-thinking mode. Drawing insights from recent findings on CoT robustness in multi-modal language models, we argue that effective reasoning in recommendation rests on two factors: perception, the ability to ground itemic tokens in their underlying language semantics, and cognition, the ability to reorganize a user's behavior sequence into coherent latent interest points. We therefore propose OneReason, which includes: (1) strong itemic token perception in pre-training, (2) a three-level cognition-enhanced CoT format for recommendation tasks in SFT, and (3) a specialize-then-unify training recipe in RL to enhance the thinking ability.
Bringing Model Editing to Generative Recommendation in Cold-Start Scenarios
Mar 15, 2026Generative recommendation (GR) has shown strong potential for sequential recommendation in an end-to-end generation paradigm. However, existing GR models suffer from severe cold-start collapse: their recommendation accuracy on cold-start items can drop to near zero. Current solutions typically rely on retraining with cold-start interactions, which is hindered by sparse feedback, high computational cost, and delayed updates, limiting practical utility in rapidly evolving recommendation catalogs. Inspired by model editing in NLP, which enables training-free knowledge injection into large language models, we explore how to bring this paradigm to generative recommendation. This, however, faces two key challenges: GR lacks the explicit subject-object binding common in natural language, making targeted edits difficult; and GR does not exhibit stable token co-occurrence patterns, making the injection of multi-token item representations unreliable. To address these challenges, we propose GenRecEdit, a model editing framework tailored for generative recommendation. GenRecEdit explicitly models the relationship between the full sequence context and next-token generation, adopts iterative token-level editing to inject multi-token item representations, and introduces a one-to-one trigger mechanism to reduce interference among multiple edits during inference. Extensive experiments on multiple datasets show that GenRecEdit substantially improves recommendation performance on cold-start items while preserving the model's original recommendation quality. Moreover, it achieves these gains using only about 9.5% of the training time required for retraining, enabling more efficient and frequent model updates.
LLaDA-Rec: Discrete Diffusion for Parallel Semantic ID Generation in Generative Recommendation
Nov 09, 2025Generative recommendation represents each item as a semantic ID, i.e., a sequence of discrete tokens, and generates the next item through autoregressive decoding. While effective, existing autoregressive models face two intrinsic limitations: (1) unidirectional constraints, where causal attention restricts each token to attend only to its predecessors, hindering global semantic modeling; and (2) error accumulation, where the fixed left-to-right generation order causes prediction errors in early tokens to propagate to the predictions of subsequent token. To address these issues, we propose LLaDA-Rec, a discrete diffusion framework that reformulates recommendation as parallel semantic ID generation. By combining bidirectional attention with the adaptive generation order, the approach models inter-item and intra-item dependencies more effectively and alleviates error accumulation. Specifically, our approach comprises three key designs: (1) a parallel tokenization scheme that produces semantic IDs for bidirectional modeling, addressing the mismatch between residual quantization and bidirectional architectures; (2) two masking mechanisms at the user-history and next-item levels to capture both inter-item sequential dependencies and intra-item semantic relationships; and (3) an adapted beam search strategy for adaptive-order discrete diffusion decoding, resolving the incompatibility of standard beam search with diffusion-based generation. Experiments on three real-world datasets show that LLaDA-Rec consistently outperforms both ID-based and state-of-the-art generative recommenders, establishing discrete diffusion as a new paradigm for generative recommendation.
PrLM: Learning Explicit Reasoning for Personalized RAG via Contrastive Reward Optimization
Aug 10, 2025Personalized retrieval-augmented generation (RAG) aims to produce user-tailored responses by incorporating retrieved user profiles alongside the input query. Existing methods primarily focus on improving retrieval and rely on large language models (LLMs) to implicitly integrate the retrieved context with the query. However, such models are often sensitive to retrieval quality and may generate responses that are misaligned with user preferences. To address this limitation, we propose PrLM, a reinforcement learning framework that trains LLMs to explicitly reason over retrieved user profiles. Guided by a contrastively trained personalization reward model, PrLM effectively learns from user responses without requiring annotated reasoning paths. Experiments on three personalized text generation datasets show that PrLM outperforms existing methods and remains robust across varying numbers of retrieved profiles and different retrievers.
Bridging Search and Recommendation through Latent Cross Reasoning
Aug 06, 2025Search and recommendation (S&R) are fundamental components of modern online platforms, yet effectively leveraging search behaviors to improve recommendation remains a challenging problem. User search histories often contain noisy or irrelevant signals that can even degrade recommendation performance, while existing approaches typically encode S&R histories either jointly or separately without explicitly identifying which search behaviors are truly useful. Inspired by the human decision-making process, where one first identifies recommendation intent and then reasons about relevant evidence, we design a latent cross reasoning framework that first encodes user S&R histories to capture global interests and then iteratively reasons over search behaviors to extract signals beneficial for recommendation. Contrastive learning is employed to align latent reasoning states with target items, and reinforcement learning is further introduced to directly optimize ranking performance. Extensive experiments on public benchmarks demonstrate consistent improvements over strong baselines, validating the importance of reasoning in enhancing search-aware recommendation.
StyliTruth : Unlocking Stylized yet Truthful LLM Generation via Disentangled Steering
Aug 06, 2025Generating stylized large language model (LLM) responses via representation editing is a promising way for fine-grained output control. However, there exists an inherent trade-off: imposing a distinctive style often degrades truthfulness. Existing representation editing methods, by naively injecting style signals, overlook this collateral impact and frequently contaminate the model's core truthfulness representations, resulting in reduced answer correctness. We term this phenomenon stylization-induced truthfulness collapse. We attribute this issue to latent coupling between style and truth directions in certain key attention heads, and propose StyliTruth, a mechanism that preserves stylization while keeping truthfulness intact. StyliTruth separates the style-relevant and truth-relevant subspaces in the model's representation space via an orthogonal deflation process. This decomposition enables independent control of style and truth in their own subspaces, minimizing interference. By designing adaptive, token-level steering vectors within each subspace, we dynamically and precisely control the generation process to maintain both stylistic fidelity and truthfulness. We validate our method on multiple styles and languages. Extensive experiments and analyses show that StyliTruth significantly reduces stylization-induced truthfulness collapse and outperforms existing inference-time intervention methods in balancing style adherence with truthfulness.
Benefit from Rich: Tackling Search Interaction Sparsity in Search Enhanced Recommendation
Aug 06, 2025In modern online platforms, search and recommendation (S&R) often coexist, offering opportunities for performance improvement through search-enhanced approaches. Existing studies show that incorporating search signals boosts recommendation performance. However, the effectiveness of these methods relies heavily on rich search interactions. They primarily benefit a small subset of users with abundant search behavior, while offering limited improvements for the majority of users who exhibit only sparse search activity. To address the problem of sparse search data in search-enhanced recommendation, we face two key challenges: (1) how to learn useful search features for users with sparse search interactions, and (2) how to design effective training objectives under sparse conditions. Our idea is to leverage the features of users with rich search interactions to enhance those of users with sparse search interactions. Based on this idea, we propose GSERec, a method that utilizes message passing on the User-Code Graphs to alleviate data sparsity in Search-Enhanced Recommendation. Specifically, we utilize Large Language Models (LLMs) with vector quantization to generate discrete codes, which connect similar users and thereby construct the graph. Through message passing on this graph, embeddings of users with rich search data are propagated to enhance the embeddings of users with sparse interactions. To further ensure that the message passing captures meaningful information from truly similar users, we introduce a contrastive loss to better model user similarities. The enhanced user representations are then integrated into downstream search-enhanced recommendation models. Experiments on three real-world datasets show that GSERec consistently outperforms baselines, especially for users with sparse search behaviors.
Similarity = Value? Consultation Value Assessment and Alignment for Personalized Search
Jun 17, 2025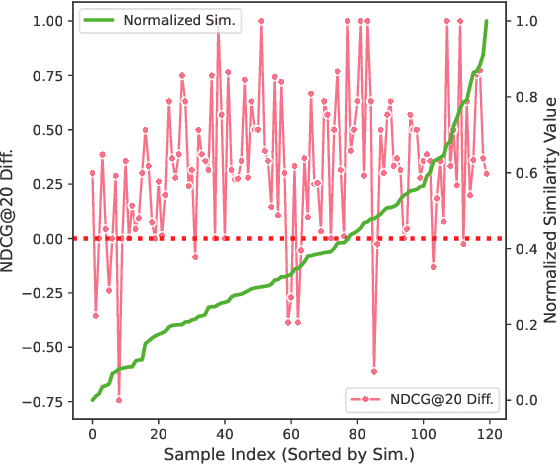

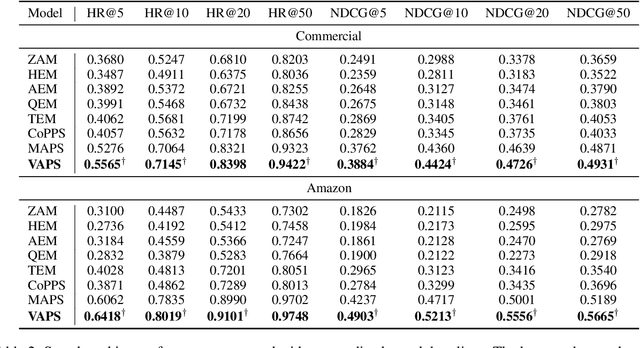
Personalized search systems in e-commerce platforms increasingly involve user interactions with AI assistants, where users consult about products, usage scenarios, and more. Leveraging consultation to personalize search services is trending. Existing methods typically rely on semantic similarity to align historical consultations with current queries due to the absence of 'value' labels, but we observe that semantic similarity alone often fails to capture the true value of consultation for personalization. To address this, we propose a consultation value assessment framework that evaluates historical consultations from three novel perspectives: (1) Scenario Scope Value, (2) Posterior Action Value, and (3) Time Decay Value. Based on this, we introduce VAPS, a value-aware personalized search model that selectively incorporates high-value consultations through a consultation-user action interaction module and an explicit objective that aligns consultations with user actions. Experiments on both public and commercial datasets show that VAPS consistently outperforms baselines in both retrieval and ranking tasks.
Unified Generative Search and Recommendation
Apr 10, 2025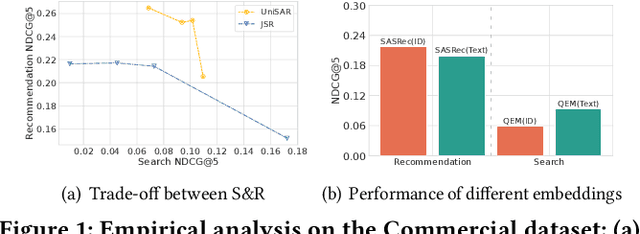
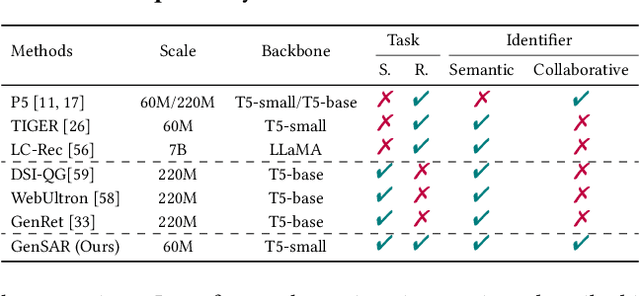
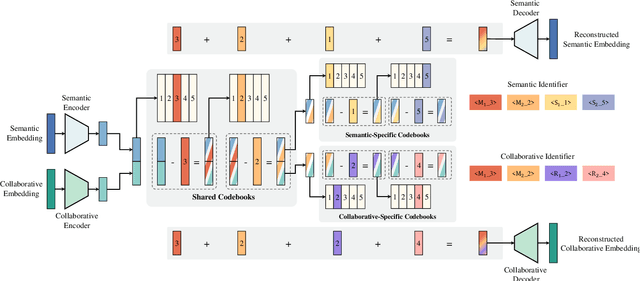

Modern commercial platforms typically offer both search and recommendation functionalities to serve diverse user needs, making joint modeling of these tasks an appealing direction. While prior work has shown that integrating search and recommendation can be mutually beneficial, it also reveals a performance trade-off: enhancements in one task often come at the expense of the other. This challenge arises from their distinct information requirements: search emphasizes semantic relevance between queries and items, whereas recommendation depends more on collaborative signals among users and items. Effectively addressing this trade-off requires tackling two key problems: (1) integrating both semantic and collaborative signals into item representations, and (2) guiding the model to distinguish and adapt to the unique demands of search and recommendation. The emergence of generative retrieval with Large Language Models (LLMs) presents new possibilities. This paradigm encodes items as identifiers and frames both search and recommendation as sequential generation tasks, offering the flexibility to leverage multiple identifiers and task-specific prompts. In light of this, we introduce GenSAR, a unified generative framework for balanced search and recommendation. Our approach designs dual-purpose identifiers and tailored training strategies to incorporate complementary signals and align with task-specific objectives. Experiments on both public and commercial datasets demonstrate that GenSAR effectively reduces the trade-off and achieves state-of-the-art performance on both tasks.