 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning While Recommending: Entropy-Guided Latent Reasoning in Generative Re-ranking Models
Jan 20, 2026Reinforcement learning plays a crucial role in generative re-ranking scenarios due to its exploration-exploitation capabilities, but existing generative methods mostly fail to adapt to the dynamic entropy changes in model difficulty during list generation, making it challenging to accurately capture complex preferences. Given that language models have achieved remarkable breakthroughs by integrating reasoning capabilities, we draw on this approach to introduce a latent reasoning mechanism, and experimental validation demonstrates that this mechanism effectively reduces entropy in the model's decision-making process. Based on these findings, we introduce the Entropy-Guided Latent Reasoning (EGLR) recommendation model, which has three core advantages. First, it abandons the "reason first, recommend later" paradigm to achieve "reasoning while recommending", specifically designed for the high-difficulty nature of list generation by enabling real-time reasoning during generation. Second, it implements entropy-guided variable-length reasoning using context-aware reasoning token alongside dynamic temperature adjustment, expanding exploration breadth in reasoning and boosting exploitation precision in recommending to achieve a more precisely adapted exploration-exploitation trade-off. Third, the model adopts a lightweight integration design with no complex independent modules or post-processing, enabling easy adaptation to existing models. Experimental results on two real-world datasets validate the model's effectiveness, and its notable advantage lies in being compatible with existing generative re-ranking models to enhance their performance. Further analyses also demonstrate its practical deployment value and research potential.
Process In-Context Learning: Enhancing Mathematical Reasoning via Dynamic Demonstration Insertion
Jan 17, 2026In-context learning (ICL) has proven highly effective across diverse large language model (LLM) tasks. However, its potential for enhancing tasks that demand step-by-step logical deduction, such as mathematical reasoning, remains underexplored. A core limitation of existing ICL approaches is their static use of demonstrations: examples are pre-selected before inference and remain fixed, failing to adapt to the dynamic confusion points that often arise during multi-step reasoning such as ambiguous calculations or logical gaps. These unresolved confusion points can lead to cascading errors that degrade final accuracy. To tackle this issue, we propose Process In-Context Learning (PICL), a dynamic demonstration integration framework designed to boost mathematical reasoning by responding to real-time inference needs. PICL operates in two stages: 1)~it identifies potential confusion points by analyzing semantics and entropy in the reasoning process and summarizes their core characteristics; 2)~upon encountering these points, it retrieves relevant demonstrations from the demonstration pool that match the confusion context and inserts them directly into the ongoing reasoning process to guide subsequent steps. Experiments show that PICL outperforms baseline methods by mitigating mid-inference confusion, highlighting the value of adaptive demonstration insertion in complex mathematical reasoning.
Test-Time Alignment for Tracking User Interest Shifts in Sequential Recommendation
Apr 02, 2025Sequential recommendation is essential in modern recommender systems, aiming to predict the next item a user may interact with based on their historical behaviors. However, real-world scenarios are often dynamic and subject to shifts in user interests. Conventional sequential recommendation models are typically trained on static historical data, limiting their ability to adapt to such shifts and resulting in significant performance degradation during testing. Recently, Test-Time Training (TTT) has emerged as a promising paradigm, enabling pre-trained models to dynamically adapt to test data by leveraging unlabeled examples during testing. However, applying TTT to effectively track and address user interest shifts in recommender systems remains an open and challenging problem. Key challenges include how to capture temporal information effectively and explicitly identifying shifts in user interests during the testing phase. To address these issues, we propose T$^2$ARec, a novel model leveraging state space model for TTT by introducing two Test-Time Alignment modules tailored for sequential recommendation, effectively capturing the distribution shifts in user interest patterns over time. Specifically, T$^2$ARec aligns absolute time intervals with model-adaptive learning intervals to capture temporal dynamics and introduce an interest state alignment mechanism to effectively and explicitly identify the user interest shifts with theoretical guarantees. These two alignment modules enable efficient and incremental updates to model parameters in a self-supervised manner during testing, enhancing predictions for online recommendation. Extensive evaluations on three benchmark datasets demonstrate that T$^2$ARec achieves state-of-the-art performance and robustly mitigates the challenges posed by user interest shifts.
Comment Staytime Prediction with LLM-enhanced Comment Understanding
Apr 02, 2025



In modern online streaming platforms, the comments section plays a critical role in enhancing the overall user experience. Understanding user behavior within the comments section is essential for comprehensive user interest modeling. A key factor of user engagement is staytime, which refers to the amount of time that users browse and post comments. Existing watchtime prediction methods struggle to adapt to staytime prediction, overlooking interactions with individual comments and their interrelation. In this paper, we present a micro-video recommendation dataset with video comments (named as KuaiComt) which is collected from Kuaishou platform. correspondingly, we propose a practical framework for comment staytime prediction with LLM-enhanced Comment Understanding (LCU). Our framework leverages the strong text comprehension capabilities of large language models (LLMs) to understand textual information of comments, while also incorporating fine-grained comment ranking signals as auxiliary tasks. The framework is two-staged: first, the LLM is fine-tuned using domain-specific tasks to bridge the video and the comments; second, we incorporate the LLM outputs into the prediction model and design two comment ranking auxiliary tasks to better understand user preference. Extensive offline experiments demonstrate the effectiveness of our framework, showing significant improvements on the task of comment staytime prediction. Additionally, online A/B testing further validates the practical benefits on industrial scenario. Our dataset KuaiComt (https://github.com/lyingCS/KuaiComt.github.io) and code for LCU (https://github.com/lyingCS/LCU) are fully released.
Modeling Domain and Feedback Transitions for Cross-Domain Sequential Recommendation
Aug 15, 2024Nowadays, many recommender systems encompass various domains to cater to users' diverse needs, leading to user behaviors transitioning across different domains. In fact, user behaviors across different domains reveal changes in preference toward recommended items. For instance, a shift from negative feedback to positive feedback indicates improved user satisfaction. However, existing cross-domain sequential recommendation methods typically model user interests by focusing solely on information about domain transitions, often overlooking the valuable insights provided by users' feedback transitions. In this paper, we propose $\text{Transition}^2$, a novel method to model transitions across both domains and types of user feedback. Specifically, $\text{Transition}^2$ introduces a transition-aware graph encoder based on user history, assigning different weights to edges according to the feedback type. This enables the graph encoder to extract historical embeddings that capture the transition information between different domains and feedback types. Subsequently, we encode the user history using a cross-transition multi-head self-attention, incorporating various masks to distinguish different types of transitions. Finally, we integrate these modules to make predictions across different domains. Experimental results on two public datasets demonstrate the effectiveness of $\text{Transition}^2$.
A Survey of Controllable Learning: Methods and Applications in Information Retrieval
Jul 04, 2024


Controllable learning (CL) emerges as a critical component in trustworthy machine learning, ensuring that learners meet predefined targets and can adaptively adjust without retraining according to the changes in those targets. We provide a formal definition of CL, and discuss its applications in information retrieval (IR) where information needs are often complex and dynamic. The survey categorizes CL according to who controls (users or platforms), what is controllable (e.g., retrieval objectives, users' historical behaviors, controllable environmental adaptation), how control is implemented (e.g., rule-based method, Pareto optimization, Hypernetwork), and where to implement control (e.g.,pre-processing, in-processing, post-processing methods). Then, we identify challenges faced by CL across training, evaluation, task setting, and deployment in online environments. Additionally, we outline promising directions for CL in theoretical analysis, efficient computation, empowering large language models, application scenarios and evaluation frameworks in IR.
Do Not Wait: Learning Re-Ranking Model Without User Feedback At Serving Time in E-Commerce
Jun 20, 2024Recommender systems have been widely used in e-commerce, and re-ranking models are playing an increasingly significant role in the domain, which leverages the inter-item influence and determines the final recommendation lists. Online learning methods keep updating a deployed model with the latest available samples to capture the shifting of the underlying data distribution in e-commerce. However, they depend on the availability of real user feedback, which may be delayed by hours or even days, such as item purchases, leading to a lag in model enhancement. In this paper, we propose a novel extension of online learning methods for re-ranking modeling, which we term LAST, an acronym for Learning At Serving Time. It circumvents the requirement of user feedback by using a surrogate model to provide the instructional signal needed to steer model improvement. Upon receiving an online request, LAST finds and applies a model modification on the fly before generating a recommendation result for the request. The modification is request-specific and transient. It means the modification is tailored to and only to the current request to capture the specific context of the request. After a request, the modification is discarded, which helps to prevent error propagation and stabilizes the online learning procedure since the predictions of the surrogate model may be inaccurate. Most importantly, as a complement to feedback-based online learning methods, LAST can be seamlessly integrated into existing online learning systems to create a more adaptive and responsive recommendation experience. Comprehensive experiments, both offline and online, affirm that LAST outperforms state-of-the-art re-ranking models.
QAGCF: Graph Collaborative Filtering for Q&A Recommendation
Jun 07, 2024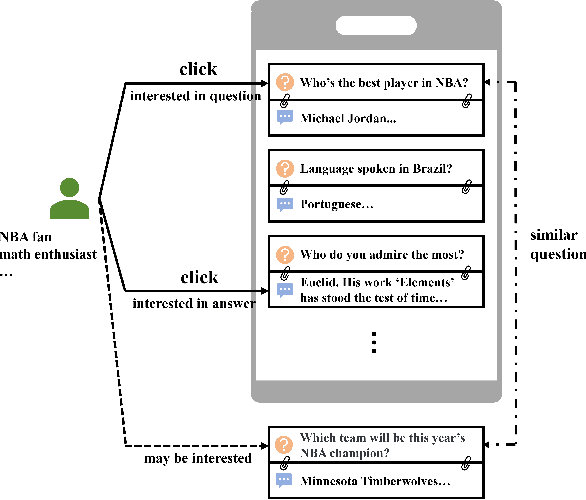

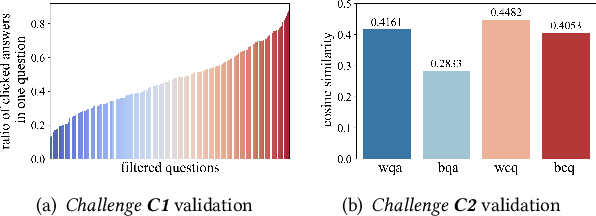
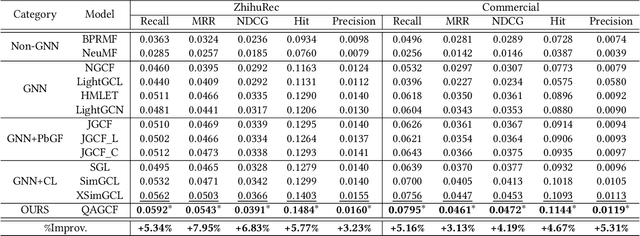
Question and answer (Q&A) platforms usually recommend question-answer pairs to meet users' knowledge acquisition needs, unlike traditional recommendations that recommend only one item. This makes user behaviors more complex, and presents two challenges for Q&A recommendation, including: the collaborative information entanglement, which means user feedback is influenced by either the question or the answer; and the semantic information entanglement, where questions are correlated with their corresponding answers, and correlations also exist among different question-answer pairs. Traditional recommendation methods treat the question-answer pair as a whole or only consider the answer as a single item, which overlooks the two challenges and cannot effectively model user interests. To address these challenges, we introduce Question & Answer Graph Collaborative Filtering (QAGCF), a graph neural network model that creates separate graphs for collaborative and semantic views to disentangle the information in question-answer pairs. The collaborative view disentangles questions and answers to individually model collaborative information, while the semantic view captures the semantic information both within and between question-answer pairs. These views are further merged into a global graph to integrate the collaborative and semantic information. Polynomial-based graph filters are used to address the high heterophily issues of the global graph. Additionally, contrastive learning is utilized to obtain robust embeddings during training. Extensive experiments on industrial and public datasets demonstrate that QAGCF consistently outperforms baselines and achieves state-of-the-art results.
UOEP: User-Oriented Exploration Policy for Enhancing Long-Term User Experiences in Recommender Systems
Jan 17, 2024



Reinforcement learning (RL) has gained traction for enhancing user long-term experiences in recommender systems by effectively exploring users' interests. However, modern recommender systems exhibit distinct user behavioral patterns among tens of millions of items, which increases the difficulty of exploration. For example, user behaviors with different activity levels require varying intensity of exploration, while previous studies often overlook this aspect and apply a uniform exploration strategy to all users, which ultimately hurts user experiences in the long run. To address these challenges, we propose User-Oriented Exploration Policy (UOEP), a novel approach facilitating fine-grained exploration among user groups. We first construct a distributional critic which allows policy optimization under varying quantile levels of cumulative reward feedbacks from users, representing user groups with varying activity levels. Guided by this critic, we devise a population of distinct actors aimed at effective and fine-grained exploration within its respective user group. To simultaneously enhance diversity and stability during the exploration process, we further introduce a population-level diversity regularization term and a supervision module. Experimental results on public recommendation datasets demonstrate that our approach outperforms all other baselines in terms of long-term performance, validating its user-oriented exploration effectiveness. Meanwhile, further analyses reveal our approach's benefits of improved performance for low-activity users as well as increased fairness among users.
Controllable Multi-Objective Re-ranking with Policy Hypernetworks
Jun 13, 2023



Multi-stage ranking pipelines have become widely used strategies in modern recommender systems, where the final stage aims to return a ranked list of items that balances a number of requirements such as user preference, diversity, novelty etc. Linear scalarization is arguably the most widely used technique to merge multiple requirements into one optimization objective, by summing up the requirements with certain preference weights. Existing final-stage ranking methods often adopt a static model where the preference weights are determined during offline training and kept unchanged during online serving. Whenever a modification of the preference weights is needed, the model has to be re-trained, which is time and resources inefficient. Meanwhile, the most appropriate weights may vary greatly for different groups of targeting users or at different time periods (e.g., during holiday promotions). In this paper, we propose a framework called controllable multi-objective re-ranking (CMR) which incorporates a hypernetwork to generate parameters for a re-ranking model according to different preference weights. In this way, CMR is enabled to adapt the preference weights according to the environment changes in an online manner, without retraining the models. Moreover, we classify practical business-oriented tasks into four main categories and seamlessly incorporate them in a new proposed re-ranking model based on an Actor-Evaluator framework, which serves as a reliable real-world testbed for CMR. Offline experiments based on the dataset collected from Taobao App showed that CMR improved several popular re-ranking models by using them as underlying models. Online A/B tests also demonstrated the effectiveness and trustworthiness of CMR.