 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodecCap: High-Fidelity Codec-Inspired Residual Modeling for Dense Video Captioning
May 26, 2026Existing video captioning methods struggle to balance visual fidelity and redundancy: holistic captions are compact but lose fine-grained evidence, whereas segment-wise captions improve coverage but introduce heavy redundancy. We propose CodecCap, a codec-inspired framework for high-fidelity dense video captioning. Analogous to video codecs, CodecCap represents videos using keyframe and residual captions. Keyframe captions exhaustively encode stable visual context, while residual captions capture temporally only localized actions, motions and changes. This effectively preserves fine-grained visual evidence while reducing redundant descriptions. To quantify the fidelity of captions, we introduce VidCapQA, a caption-then-QA benchmark with 1,000 questions across 14 capability dimensions. Results on VidCapQA show that captions directly generated by strong VLMs still miss many visual details, highlighting caption representation as a critical bottleneck. Experiments show that CodecCap significantly surpasses direct captioning with the same underlying VLMs, suggesting keyframe-residual captioning a way for high-fidelity video-language supervision. We further use CodecCap to construct CodecVDC-100K, a large-scale dense captioning dataset with anchor, residual, scene-level, and video-level supervision.
Action-Aware Generative Sequence Modeling for Short Video Recommendation
Apr 28, 2026With the rapid development of the Internet, users have increasingly higher expectations for the recommendation accuracy of online content consumption platforms. However, short videos often contain diverse segments, and users may not hold the same attitude toward all of them. Traditional binary-classification recommendation models, which treat a video as a single holistic entity, face limitations in accurately capturing such nuanced preferences. Considering that user consumption is a temporal process, this paper demonstrates that the timing of user actions can represent diverse intentions through statistical analysis and examination of action patterns. Based on this insight, we propose a novel modeling paradigm: Action-Aware Generative Sequence Network (A2Gen), which refines user actions along the temporal dimension and chains them into sequences for unified processing and prediction. First, we introduce the Context-aware Attention Module (CAM) to model action sequences enriched with item-specific contextual features. Building upon this, we develop the Hierarchical Sequence Encoder (HSE) to learn temporal action patterns from users' historical actions. Finally, through leveraging CAM, we design a module for action sequence generation: the Action-seq Autoregressive Generator (AAG). Extensive offline experiments on the Kuaishou's dataset and the Tmall public dataset demonstrate the superiority of our proposed model. Furthermore, through large-scale online A/B testing deployed on Kuaishou's platform, our model achieves significant improvements over baseline methods in multi-task prediction by leveraging sequential information. Specifically, it yields increases of 0.34% in user watch time, 8.1% in interaction rate, and 0.162% in overall user retention (LifeTime-7), leading to successful deployment across all traffic, serving over 400 million users every day.
Physically-Induced Atmospheric Adversarial Perturbations: Enhancing Transferability and Robustness in Remote Sensing Image Classification
Apr 16, 2026Adversarial attacks pose a severe threat to the reliability of deep learning models in remote sensing (RS) image classification. Most existing methods rely on direct pixel-wise perturbations, failing to exploit the inherent atmospheric characteristics of RS imagery or survive real-world image degradations. In this paper, we propose FogFool, a physically plausible adversarial framework that generates fog-based perturbations by iteratively optimizing atmospheric patterns based on Perlin noise. By modeling fog formations with natural, irregular structures, FogFool generates adversarial examples that are not only visually consistent with authentic RS scenes but also deceptive. By leveraging the spatial coherence and mid-to-low-frequency nature of atmospheric phenomena, FogFool embeds adversarial information into structural features shared across diverse architectures. Extensive experiments on two benchmark RS datasets demonstrate that FogFool achieves superior performance: not only does it exceed in white-box settings, but also exhibits exceptional black-box transferability (reaching 83.74% TASR) and robustness against common preprocessing-based defenses such as JPEG compression and filtering. Detailed analyses, including confusion matrices and Class Activation Map (CAM) visualizations, reveal that our atmospheric-driven perturbations induce a universal shift in model attention. These results indicate that FogFool represents a practical, stealthy, and highly persistent threat to RS classification systems, providing a robust benchmark for evaluating model reliability in complex environments.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Differentiable Inverse Modeling with Physics-Constrained Latent Diffusion for Heterogeneous Subsurface Parameter Fields
Dec 27, 2025We present a latent diffusion-based differentiable inversion method (LD-DIM) for PDE-constrained inverse problems involving high-dimensional spatially distributed coefficients. LD-DIM couples a pretrained latent diffusion prior with an end-to-end differentiable numerical solver to reconstruct unknown heterogeneous parameter fields in a low-dimensional nonlinear manifold, improving numerical conditioning and enabling stable gradient-based optimization under sparse observations. The proposed framework integrates a latent diffusion model (LDM), trained in a compact latent space, with a differentiable finite-volume discretization of the forward PDE. Sensitivities are propagated through the discretization using adjoint-based gradients combined with reverse-mode automatic differentiation. Inversion is performed directly in latent space, which implicitly suppresses ill-conditioned degrees of freedom while preserving dominant structural modes, including sharp material interfaces. The effectiveness of LD-DIM is demonstrated using a representative inverse problem for flow in porous media, where heterogeneous conductivity fields are reconstructed from spatially sparse hydraulic head measurements. Numerical experiments assess convergence behavior and reconstruction quality for both Gaussian random fields and bimaterial coefficient distributions. The results show that LD-DIM achieves consistently improved numerical stability and reconstruction accuracy of both parameter fields and corresponding PDE solutions compared with physics-informed neural networks (PINNs) and physics-embedded variational autoencoder (VAE) baselines, while maintaining sharp discontinuities and reducing sensitivity to initialization.
AWPO: Enhancing Tool-Use of Large Language Models through Explicit Integration of Reasoning Rewards
Dec 23, 2025While reinforcement learning (RL) shows promise in training tool-use large language models (LLMs) using verifiable outcome rewards, existing methods largely overlook the potential of explicit reasoning rewards to bolster reasoning and tool utilization. Furthermore, natively combining reasoning and outcome rewards may yield suboptimal performance or conflict with the primary optimization objective. To address this, we propose advantage-weighted policy optimization (AWPO) -- a principled RL framework that effectively integrates explicit reasoning rewards to enhance tool-use capability. AWPO incorporates variance-aware gating and difficulty-aware weighting to adaptively modulate advantages from reasoning signals based on group-relative statistics, alongside a tailored clipping mechanism for stable optimization. Extensive experiments demonstrate that AWPO achieves state-of-the-art performance across standard tool-use benchmarks, significantly outperforming strong baselines and leading closed-source models in challenging multi-turn scenarios. Notably, with exceptional parameter efficiency, our 4B model surpasses Grok-4 by 16.0 percent in multi-turn accuracy while preserving generalization capability on the out-of-distribution MMLU-Pro benchmark.
MultiEditor: Controllable Multimodal Object Editing for Driving Scenarios Using 3D Gaussian Splatting Priors
Jul 30, 2025Autonomous driving systems rely heavily on multimodal perception data to understand complex environments. However, the long-tailed distribution of real-world data hinders generalization, especially for rare but safety-critical vehicle categories. To address this challenge, we propose MultiEditor, a dual-branch latent diffusion framework designed to edit images and LiDAR point clouds in driving scenarios jointly. At the core of our approach is introducing 3D Gaussian Splatting (3DGS) as a structural and appearance prior for target objects. Leveraging this prior, we design a multi-level appearance control mechanism--comprising pixel-level pasting, semantic-level guidance, and multi-branch refinement--to achieve high-fidelity reconstruction across modalities. We further propose a depth-guided deformable cross-modality condition module that adaptively enables mutual guidance between modalities using 3DGS-rendered depth, significantly enhancing cross-modality consistency. Extensive experiments demonstrate that MultiEditor achieves superior performance in visual and geometric fidelity, editing controllability, and cross-modality consistency. Furthermore, generating rare-category vehicle data with MultiEditor substantially enhances the detection accuracy of perception models on underrepresented classes.
Dependency Network-Based Portfolio Design with Forecasting and VaR Constraints
Jul 26, 2025

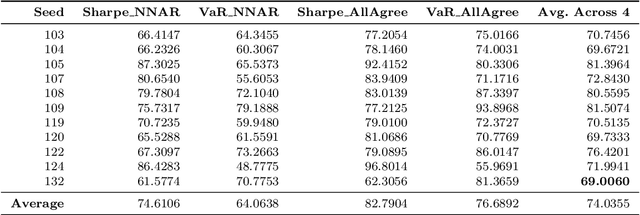

This study proposes a novel portfolio optimization framework that integrates statistical social network analysis with time series forecasting and risk management. Using daily stock data from the S&P 500 (2020-2024), we construct dependency networks via Vector Autoregression (VAR) and Forecast Error Variance Decomposition (FEVD), transforming influence relationships into a cost-based network. Specifically, FEVD breaks down the VAR's forecast error variance to quantify how much each stock's shocks contribute to another's uncertainty information we invert to form influence-based edge weights in our network. By applying the Minimum Spanning Tree (MST) algorithm, we extract the core inter-stock structure and identify central stocks through degree centrality. A dynamic portfolio is constructed using the top-ranked stocks, with capital allocated based on Value at Risk (VaR). To refine stock selection, we incorporate forecasts from ARIMA and Neural Network Autoregressive (NNAR) models. Trading simulations over a one-year period demonstrate that the MST-based strategies outperform a buy-and-hold benchmark, with the tuned NNAR-enhanced strategy achieving a 63.74% return versus 18.00% for the benchmark. Our results highlight the potential of combining network structures, predictive modeling, and risk metrics to improve adaptive financial decision-making.
Galerkin-ARIMA: A Two-Stage Polynomial Regression Framework for Fast Rolling One-Step-Ahead Forecasting
Jul 10, 2025Time-series models like ARIMA remain widely used for forecasting but limited to linear assumptions and high computational cost in large and complex datasets. We propose Galerkin-ARIMA that generalizes the AR component of ARIMA and replace it with a flexible spline-based function estimated by Galerkin projection. This enables the model to capture nonlinear dependencies in lagged values and retain the MA component and Gaussian noise assumption. We derive a closed-form OLS estimator for the Galerkin coefficients and show the model is asymptotically unbiased and consistent under standard conditions. Our method bridges classical time-series modeling and nonparametric regression, which offering improved forecasting performance and computational efficiency.
History-Aware Neural Operator: Robust Data-Driven Constitutive Modeling of Path-Dependent Materials
Jun 12, 2025



This study presents an end-to-end learning framework for data-driven modeling of path-dependent inelastic materials using neural operators. The framework is built on the premise that irreversible evolution of material responses, governed by hidden dynamics, can be inferred from observable data. We develop the History-Aware Neural Operator (HANO), an autoregressive model that predicts path-dependent material responses from short segments of recent strain-stress history without relying on hidden state variables, thereby overcoming self-consistency issues commonly encountered in recurrent neural network (RNN)-based models. Built on a Fourier-based neural operator backbone, HANO enables discretization-invariant learning. To enhance its ability to capture both global loading patterns and critical local path dependencies, we embed a hierarchical self-attention mechanism that facilitates multiscale feature extraction. Beyond ensuring self-consistency, HANO mitigates sensitivity to initial hidden states, a commonly overlooked issue that can lead to instability in recurrent models when applied to generalized loading paths. By modeling stress-strain evolution as a continuous operator rather than relying on fixed input-output mappings, HANO naturally accommodates varying path discretizations and exhibits robust performance under complex conditions, including irregular sampling, multi-cycle loading, noisy data, and pre-stressed states. We evaluate HANO on two benchmark problems: elastoplasticity with hardening and progressive anisotropic damage in brittle solids. Results show that HANO consistently outperforms baseline models in predictive accuracy, generalization, and robustness. With its demonstrated capabilities, HANO provides an effective data-driven surrogate for simulating inelastic materials and is well-suited for integration with classical numerical solvers.