 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConservative Bias in Multi-Teacher Learning: Why Agents Prefer Low-Reward Advisors
Dec 23, 2025Interactive reinforcement learning (IRL) has shown promise in enabling autonomous agents and robots to learn complex behaviours from human teachers, yet the dynamics of teacher selection remain poorly understood. This paper reveals an unexpected phenomenon in IRL: when given a choice between teachers with different reward structures, learning agents overwhelmingly prefer conservative, low-reward teachers (93.16% selection rate) over those offering 20x higher rewards. Through 1,250 experimental runs in navigation tasks with multiple expert teachers, we discovered: (1) Conservative bias dominates teacher selection: agents systematically choose the lowest-reward teacher, prioritising consistency over optimality; (2) Critical performance thresholds exist at teacher availability rho >= 0.6 and accuracy omega >= 0.6, below which the framework fails catastrophically; (3) The framework achieves 159% improvement over baseline Q-learning under concept drift. These findings challenge fundamental assumptions about optimal teaching in RL and suggest potential implications for human-robot collaboration, where human preferences for safety and consistency may align with the observed agent selection behaviour, potentially informing training paradigms for safety-critical robotic applications.
Towards Senior-Robot Interaction: Reactive Robot Dog Gestures
Dec 22, 2025



As the global population ages, many seniors face the problem of loneliness. Companion robots offer a potential solution. However, current companion robots often lack advanced functionality, while task-oriented robots are not designed for social interaction, limiting their suitability and acceptance by seniors. Our work introduces a senior-oriented system for quadruped robots that allows for more intuitive user input and provides more socially expressive output. For user input, we implemented a MediaPipe-based module for hand gesture and head movement recognition, enabling control without a remote. For output, we designed and trained robotic dog gestures using curriculum-based reinforcement learning in Isaac Gym, progressing from simple standing to three-legged balancing and leg extensions, and more. The final tests achieved over 95\% success on average in simulation, and we validated a key social gesture (the paw-lift) on a Unitree robot. Real-world tests demonstrated the feasibility and social expressiveness of this framework, while also revealing sim-to-real challenges in joint compliance, load distribution, and balance control. These contributions advance the development of practical quadruped robots as social companions for the senior and outline pathways for sim-to-real adaptation and inform future user studies.
LAPX: Lightweight Hourglass Network with Global Context
Dec 18, 2025Human pose estimation is a crucial task in computer vision. Methods that have SOTA (State-of-the-Art) accuracy, often involve a large number of parameters and incur substantial computational cost. Many lightweight variants have been proposed to reduce the model size and computational cost of them. However, several of these methods still contain components that are not well suited for efficient deployment on edge devices. Moreover, models that primarily emphasize inference speed on edge devices often suffer from limited accuracy due to their overly simplified designs. To address these limitations, we propose LAPX, an Hourglass network with self-attention that captures global contextual information, based on previous work, LAP. In addition to adopting the self-attention module, LAPX advances the stage design and refine the lightweight attention modules. It achieves competitive results on two benchmark datasets, MPII and COCO, with only 2.3M parameters, and demonstrates real-time performance, confirming its edge-device suitability.
Towards Closing the Domain Gap with Event Cameras
Dec 18, 2025Although traditional cameras are the primary sensor for end-to-end driving, their performance suffers greatly when the conditions of the data they were trained on does not match the deployment environment, a problem known as the domain gap. In this work, we consider the day-night lighting difference domain gap. Instead of traditional cameras we propose event cameras as a potential alternative which can maintain performance across lighting condition domain gaps without requiring additional adjustments. Our results show that event cameras maintain more consistent performance across lighting conditions, exhibiting domain-shift penalties that are generally comparable to or smaller than grayscale frames and provide superior baseline performance in cross-domain scenarios.
SWIFT-Nav: Stability-Aware Waypoint-Level TD3 with Fuzzy Arbitration for UAV Navigation in Cluttered Environments
Dec 17, 2025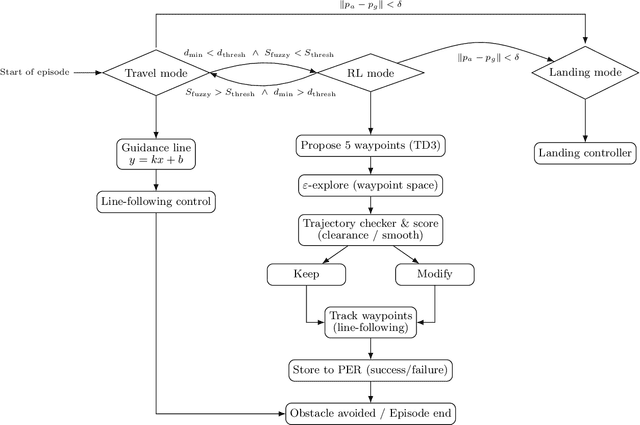



Efficient and reliable UAV navigation in cluttered and dynamic environments remains challenging. We propose SWIFT-Nav: Stability-aware Waypoint-level Integration of Fuzzy arbitration and TD3 for Navigation, a TD3-based navigation framework that achieves fast, stable convergence to obstacle-aware paths. The system couples a sensor-driven perception front end with a TD3 waypoint policy: the perception module converts LiDAR ranges into a confidence-weighted safety map and goal cues, while the TD3 policy is trained with Prioritised Experience Replay to focus on high-error transitions and a decaying epsilon-greedy exploration schedule that gradually shifts from exploration to exploitation. A lightweight fuzzy-logic layer computes a safety score from radial measurements and near obstacles, gates mode switching and clamps unsafe actions; in parallel, task-aligned reward shaping combining goal progress, clearance, and switch-economy terms provides dense, well-scaled feedback that accelerates learning. Implemented in Webots with proximity-based collision checking, our approach consistently outperforms baselines in trajectory smoothness and generalization to unseen layouts, while preserving real-time responsiveness. These results show that combining TD3 with replay prioritisation, calibrated exploration, and fuzzy-safety rules yields a robust and deployable solution for UAV navigation in cluttered scenes.
Ensemble Elastic DQN: A novel multi-step ensemble approach to address overestimation in deep value-based reinforcement learning
Jun 06, 2025While many algorithmic extensions to Deep Q-Networks (DQN) have been proposed, there remains limited understanding of how different improvements interact. In particular, multi-step and ensemble style extensions have shown promise in reducing overestimation bias, thereby improving sample efficiency and algorithmic stability. In this paper, we introduce a novel algorithm called Ensemble Elastic Step DQN (EEDQN), which unifies ensembles with elastic step updates to stabilise algorithmic performance. EEDQN is designed to address two major challenges in deep reinforcement learning: overestimation bias and sample efficiency. We evaluated EEDQN against standard and ensemble DQN variants across the MinAtar benchmark, a set of environments that emphasise behavioral learning while reducing representational complexity. Our results show that EEDQN achieves consistently robust performance across all tested environments, outperforming baseline DQN methods and matching or exceeding state-of-the-art ensemble DQNs in final returns on most of the MinAtar environments. These findings highlight the potential of systematically combining algorithmic improvements and provide evidence that ensemble and multi-step methods, when carefully integrated, can yield substantial gains.
Large Language Models Are More Persuasive Than Incentivized Human Persuaders
May 14, 2025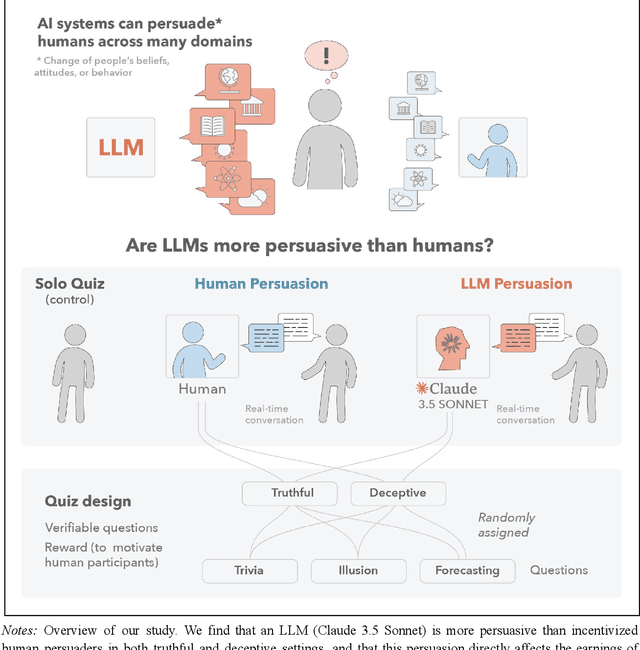
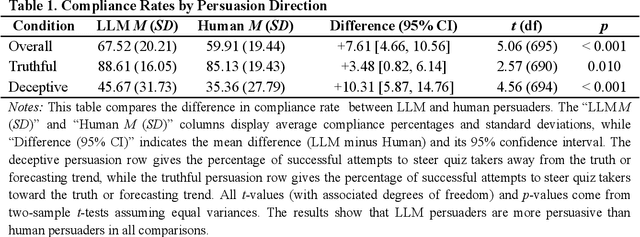
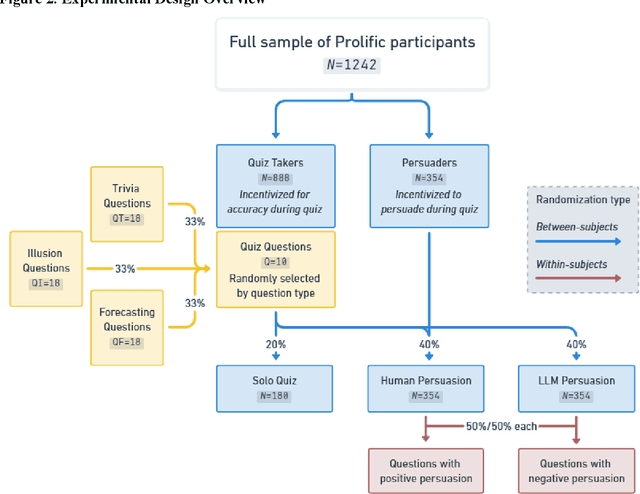
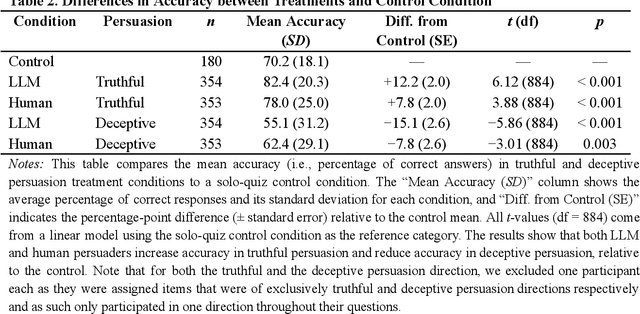
We directly compare the persuasion capabilities of a frontier large language model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an interactive, real-time conversational quiz setting. In this preregistered, large-scale incentivized experiment, participants (quiz takers) completed an online quiz where persuaders (either humans or LLMs) attempted to persuade quiz takers toward correct or incorrect answers. We find that LLM persuaders achieved significantly higher compliance with their directional persuasion attempts than incentivized human persuaders, demonstrating superior persuasive capabilities in both truthful (toward correct answers) and deceptive (toward incorrect answers) contexts. We also find that LLM persuaders significantly increased quiz takers' accuracy, leading to higher earnings, when steering quiz takers toward correct answers, and significantly decreased their accuracy, leading to lower earnings, when steering them toward incorrect answers. Overall, our findings suggest that AI's persuasion capabilities already exceed those of humans that have real-money bonuses tied to performance. Our findings of increasingly capable AI persuaders thus underscore the urgency of emerging alignment and governance frameworks.
How Can LLMs and Knowledge Graphs Contribute to Robot Safety? A Few-Shot Learning Approach
Dec 16, 2024Large Language Models (LLMs) are transforming the robotics domain by enabling robots to comprehend and execute natural language instructions. The cornerstone benefits of LLM include processing textual data from technical manuals, instructions, academic papers, and user queries based on the knowledge provided. However, deploying LLM-generated code in robotic systems without safety verification poses significant risks. This paper outlines a safety layer that verifies the code generated by ChatGPT before executing it to control a drone in a simulated environment. The safety layer consists of a fine-tuned GPT-4o model using Few-Shot learning, supported by knowledge graph prompting (KGP). Our approach improves the safety and compliance of robotic actions, ensuring that they adhere to the regulations of drone operations.
Attention-Enhanced Lightweight Hourglass Network for Human Pose Estimation
Dec 09, 2024



Pose estimation is a critical task in computer vision with a wide range of applications from activity monitoring to human-robot interaction. However,most of the existing methods are computationally expensive or have complex architecture. Here we propose a lightweight attention based pose estimation network that utilizes depthwise separable convolution and Convolutional Block Attention Module on an hourglass backbone. The network significantly reduces the computational complexity (floating point operations) and the model size (number of parameters) containing only about 10% of parameters of original eight stack Hourglass network.Experiments were conducted on COCO and MPII datasets using a two stack hourglass backbone. The results showed that our model performs well in comparison to six other lightweight pose estimation models with an average precision of 72.07. The model achieves this performance with only 2.3M parameters and 3.7G FLOPs.
Adaptive Alignment: Dynamic Preference Adjustments via Multi-Objective Reinforcement Learning for Pluralistic AI
Oct 31, 2024
Emerging research in Pluralistic Artificial Intelligence (AI) alignment seeks to address how intelligent systems can be designed and deployed in accordance with diverse human needs and values. We contribute to this pursuit with a dynamic approach for aligning AI with diverse and shifting user preferences through Multi Objective Reinforcement Learning (MORL), via post-learning policy selection adjustment. In this paper, we introduce the proposed framework for this approach, outline its anticipated advantages and assumptions, and discuss technical details about the implementation. We also examine the broader implications of adopting a retroactive alignment approach through the sociotechnical systems perspective.