 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sea to System: Exploring User-Centered Explainable AI for Maritime Decision Support
Sep 18, 2025As autonomous technologies increasingly shape maritime operations, understanding why an AI system makes a decision becomes as crucial as what it decides. In complex and dynamic maritime environments, trust in AI depends not only on performance but also on transparency and interpretability. This paper highlights the importance of Explainable AI (XAI) as a foundation for effective human-machine teaming in the maritime domain, where informed oversight and shared understanding are essential. To support the user-centered integration of XAI, we propose a domain-specific survey designed to capture maritime professionals' perceptions of trust, usability, and explainability. Our aim is to foster awareness and guide the development of user-centric XAI systems tailored to the needs of seafarers and maritime teams.
Asch Meets HRI: Human Conformity to Robot Groups
Aug 25, 2023
We present a research outline that aims at investigating group dynamics and peer pressure in the context of industrial robots. Our research plan was motivated by the fact that industrial robots became already an integral part of human-robot co-working. However, industrial robots have been sparsely integrated into research on robot credibility, group dynamics, and potential users' tendency to follow a robot's indication. Therefore, we aim to transfer the classic Asch experiment (see \cite{Asch_51}) into HRI with industrial robots. More precisely, we will test to what extent participants follow a robot's response when confronted with a group (vs. individual) industrial robot arms (vs. human) peers who give a false response. We are interested in highlighting the effects of group size, perceived robot credibility, psychological stress, and peer pressure in the context of industrial robots. With the results of this research, we hope to highlight group dynamics that might underlie HRI in industrial settings in which numerous robots already work closely together with humans in shared environments.
I am Only Happy When There is Light: The Impact of Environmental Changes on Affective Facial Expressions Recognition
Oct 28, 2022
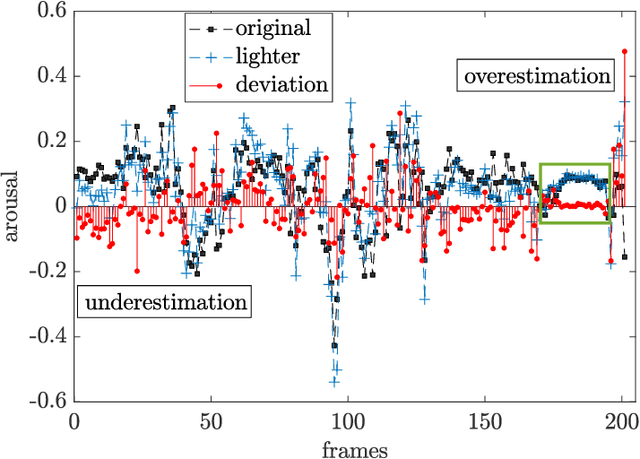
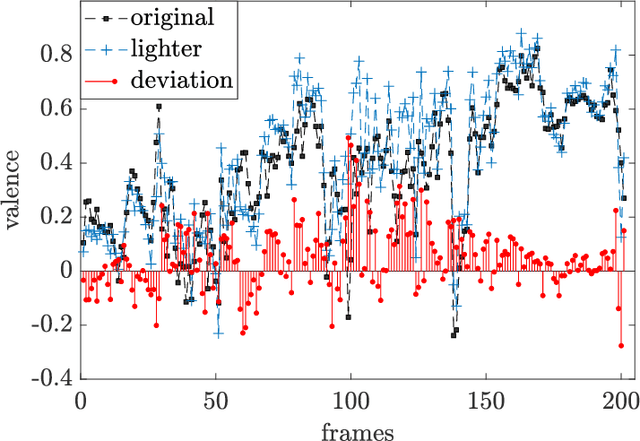
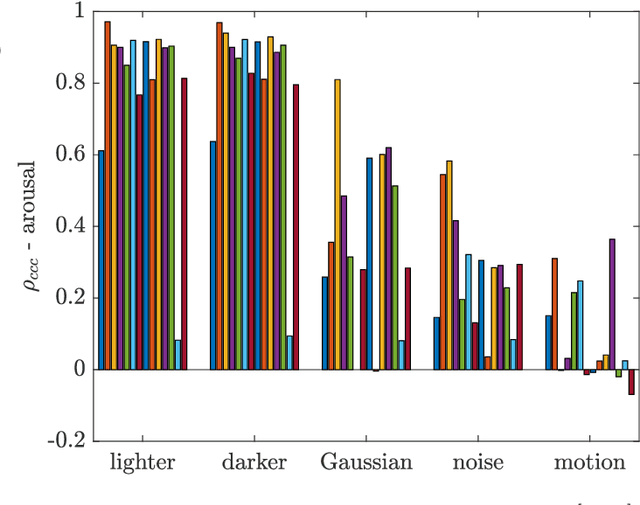
Human-robot interaction (HRI) benefits greatly from advances in the machine learning field as it allows researchers to employ high-performance models for perceptual tasks like detection and recognition. Especially deep learning models, either pre-trained for feature extraction or used for classification, are now established methods to characterize human behaviors in HRI scenarios and to have social robots that understand better those behaviors. As HRI experiments are usually small-scale and constrained to particular lab environments, the questions are how well can deep learning models generalize to specific interaction scenarios, and further, how good is their robustness towards environmental changes? These questions are important to address if the HRI field wishes to put social robotic companions into real environments acting consistently, i.e. changing lighting conditions or moving people should still produce the same recognition results. In this paper, we study the impact of different image conditions on the recognition of arousal and valence from human facial expressions using the FaceChannel framework \cite{Barro20}. Our results show how the interpretation of human affective states can differ greatly in either the positive or negative direction even when changing only slightly the image properties. We conclude the paper with important points to consider when employing deep learning models to ensure sound interpretation of HRI experiments.
Snapture -- A Novel Neural Architecture for Combined Static and Dynamic Hand Gesture Recognition
May 28, 2022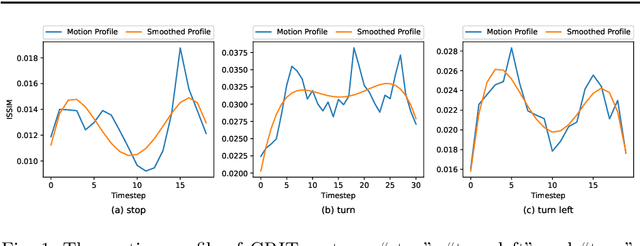

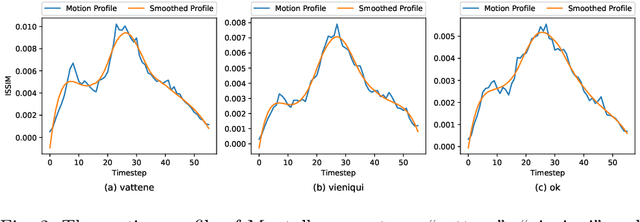
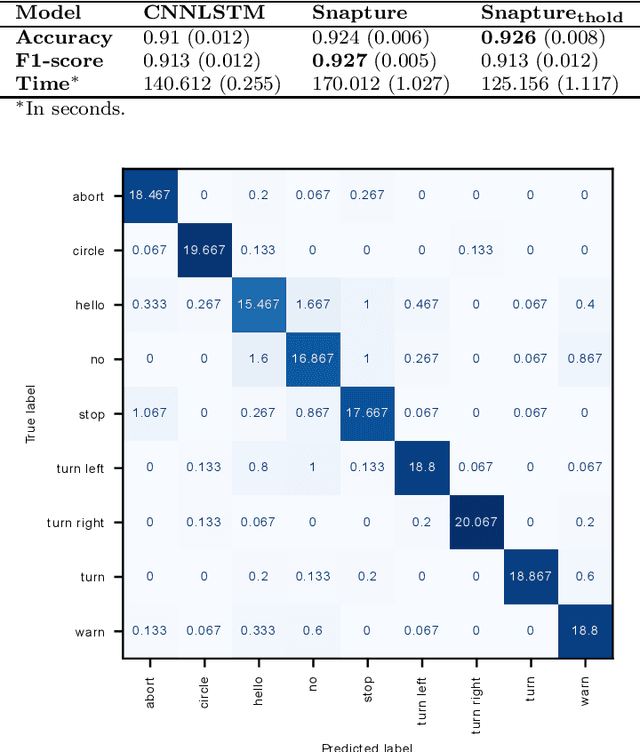
As robots are expected to get more involved in people's everyday lives, frameworks that enable intuitive user interfaces are in demand. Hand gesture recognition systems provide a natural way of communication and, thus, are an integral part of seamless Human-Robot Interaction (HRI). Recent years have witnessed an immense evolution of computational models powered by deep learning. However, state-of-the-art models fall short in expanding across different gesture domains, such as emblems and co-speech. In this paper, we propose a novel hybrid hand gesture recognition system. Our architecture enables learning both static and dynamic gestures: by capturing a so-called "snapshot" of the gesture performance at its peak, we integrate the hand pose along with the dynamic movement. Moreover, we present a method for analyzing the motion profile of a gesture to uncover its dynamic characteristics and which allows regulating a static channel based on the amount of motion. Our evaluation demonstrates the superiority of our approach on two gesture benchmarks compared to a CNNLSTM baseline. We also provide an analysis on a gesture class basis that unveils the potential of our Snapture architecture for performance improvements. Thanks to its modular implementation, our framework allows the integration of other multimodal data like facial expressions and head tracking, which are important cues in HRI scenarios, into one architecture. Thus, our work contributes both to gesture recognition research and machine learning applications for non-verbal communication with robots.
Solving Visual Object Ambiguities when Pointing: An Unsupervised Learning Approach
Dec 13, 2019
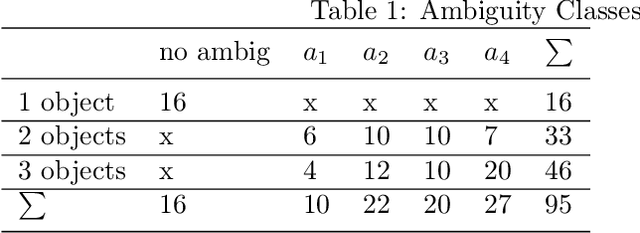
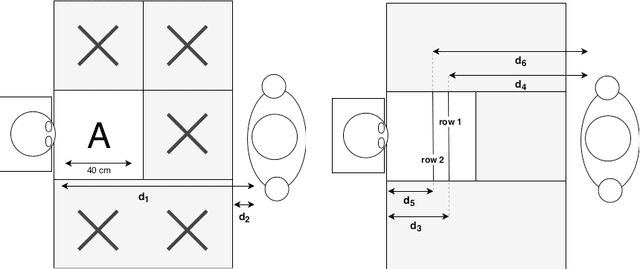
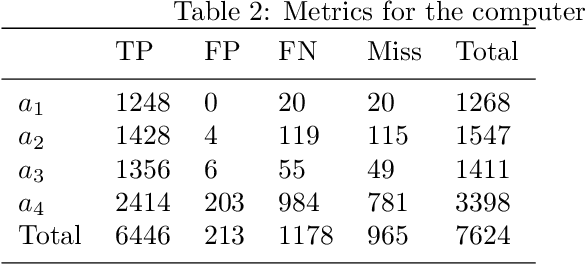
Whenever we are addressing a specific object or refer to a certain spatial location, we are using referential or deictic gestures usually accompanied by some verbal description. Especially pointing gestures are necessary to dissolve ambiguities in a scene and they are of crucial importance when verbal communication may fail due to environmental conditions or when two persons simply do not speak the same language. With the currently increasing advances of humanoid robots and their future integration in domestic domains, the development of gesture interfaces complementing human-robot interaction scenarios is of substantial interest. The implementation of an intuitive gesture scenario is still challenging because both the pointing intention and the corresponding object have to be correctly recognized in real-time. The demand increases when considering pointing gestures in a cluttered environment, as is the case in households. Also, humans perform pointing in many different ways and those variations have to be captured. Research in this field often proposes a set of geometrical computations which do not scale well with the number of gestures and objects, use specific markers or a predefined set of pointing directions. In this paper, we propose an unsupervised learning approach to model the distribution of pointing gestures using a growing-when-required (GWR) network. We introduce an interaction scenario with a humanoid robot and define so-called ambiguity classes. Our implementation for the hand and object detection is independent of any markers or skeleton models, thus it can be easily reproduced. Our evaluation comparing a baseline computer vision approach with our GWR model shows that the pointing-object association is well learned even in cases of ambiguities resulting from close object proximity.
Potentials and Limitations of Deep Neural Networks for Cognitive Robots
May 02, 2018Although Deep Neural Networks reached remarkable performance on several benchmarks and even gained scientific publicity, they are not able to address the concept of cognition as a whole. In this paper, we argue that those architectures are potentially interesting for cognitive robots regarding their perceptual representation power for audio and vision data. Then, we identify crucial settings for cognitive robotics where deep neural networks have as yet only contributed little compared to the challenges in cognitive robotics. Finally, we argue that the rather unexplored area of Reservoir Computing qualifies to be an integral part of sequential learning in this context.