 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Gen Museum Guides: Autonomous Navigation and Visitor Interaction with an Agentic Robot
Jul 16, 2025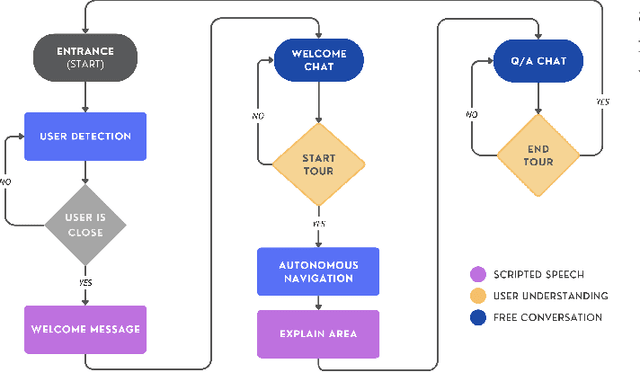

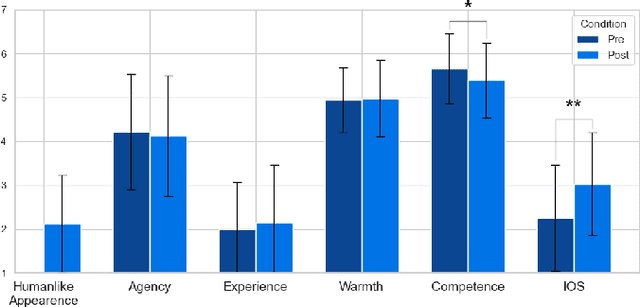
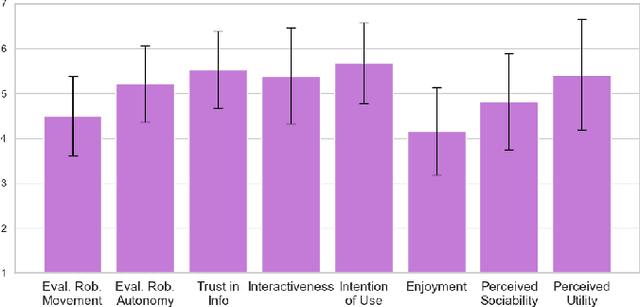
Autonomous robots are increasingly being tested into public spaces to enhance user experiences, particularly in cultural and educational settings. This paper presents the design, implementation, and evaluation of the autonomous museum guide robot Alter-Ego equipped with advanced navigation and interactive capabilities. The robot leverages state-of-the-art Large Language Models (LLMs) to provide real-time, context aware question-and-answer (Q&A) interactions, allowing visitors to engage in conversations about exhibits. It also employs robust simultaneous localization and mapping (SLAM) techniques, enabling seamless navigation through museum spaces and route adaptation based on user requests. The system was tested in a real museum environment with 34 participants, combining qualitative analysis of visitor-robot conversations and quantitative analysis of pre and post interaction surveys. Results showed that the robot was generally well-received and contributed to an engaging museum experience, despite some limitations in comprehension and responsiveness. This study sheds light on HRI in cultural spaces, highlighting not only the potential of AI-driven robotics to support accessibility and knowledge acquisition, but also the current limitations and challenges of deploying such technologies in complex, real-world environments.
Building Knowledge from Interactions: An LLM-Based Architecture for Adaptive Tutoring and Social Reasoning
Apr 02, 2025



Integrating robotics into everyday scenarios like tutoring or physical training requires robots capable of adaptive, socially engaging, and goal-oriented interactions. While Large Language Models show promise in human-like communication, their standalone use is hindered by memory constraints and contextual incoherence. This work presents a multimodal, cognitively inspired framework that enhances LLM-based autonomous decision-making in social and task-oriented Human-Robot Interaction. Specifically, we develop an LLM-based agent for a robot trainer, balancing social conversation with task guidance and goal-driven motivation. To further enhance autonomy and personalization, we introduce a memory system for selecting, storing and retrieving experiences, facilitating generalized reasoning based on knowledge built across different interactions. A preliminary HRI user study and offline experiments with a synthetic dataset validate our approach, demonstrating the system's ability to manage complex interactions, autonomously drive training tasks, and build and retrieve contextual memories, advancing socially intelligent robotics.
Toward a Universal Concept of Artificial Personality: Implementing Robotic Personality in a Kinova Arm
Jan 12, 2025



The fundamental role of personality in shaping interactions is increasingly being exploited in robotics. A carefully designed robotic personality has been shown to improve several key aspects of Human-Robot Interaction (HRI). However, the fragmentation and rigidity of existing approaches reveal even greater challenges when applied to non-humanoid robots. On one hand, the state of the art is very dispersed; on the other hand, Industry 4.0 is moving towards a future where humans and industrial robots are going to coexist. In this context, the proper design of a robotic personality can lead to more successful interactions. This research takes a first step in that direction by integrating a comprehensive cognitive architecture built upon the definition of robotic personality - validated on humanoid robots - into a robotic Kinova Jaco2 arm. The robot personality is defined through the cognitive architecture as a vector in the three-dimensional space encompassing Conscientiousness, Extroversion, and Agreeableness, affecting how actions are executed, the action selection process, and the internal reaction to environmental stimuli. Our main objective is to determine whether users perceive distinct personalities in the robot, regardless of its shape, and to understand the role language plays in shaping these perceptions. To achieve this, we conducted a user study comprising 144 sessions of a collaborative game between a Kinova Jaco2 arm and participants, where the robot's behavior was influenced by its assigned personality. Furthermore, we compared two conditions: in the first, the robot communicated solely through gestures and action choices, while in the second, it also utilized verbal interaction.
Let people fail! Exploring the influence of explainable virtual and robotic agents in learning-by-doing tasks
Nov 15, 2024
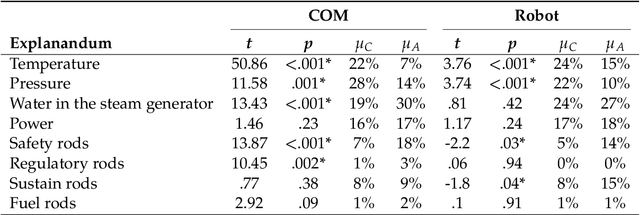
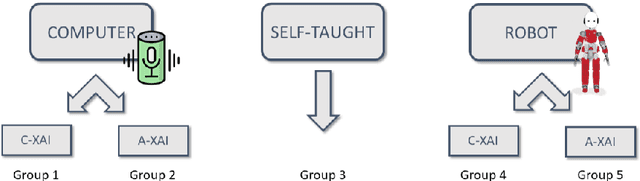
Collaborative decision-making with artificial intelligence (AI) agents presents opportunities and challenges. While human-AI performance often surpasses that of individuals, the impact of such technology on human behavior remains insufficiently understood, primarily when AI agents can provide justifiable explanations for their suggestions. This study compares the effects of classic vs. partner-aware explanations on human behavior and performance during a learning-by-doing task. Three participant groups were involved: one interacting with a computer, another with a humanoid robot, and a third one without assistance. Results indicated that partner-aware explanations influenced participants differently based on the type of artificial agents involved. With the computer, participants enhanced their task completion times. At the same time, those interacting with the humanoid robot were more inclined to follow its suggestions, although they did not reduce their timing. Interestingly, participants autonomously performing the learning-by-doing task demonstrated superior knowledge acquisition than those assisted by explainable AI (XAI). These findings raise profound questions and have significant implications for automated tutoring and human-AI collaboration.
The Effects of Selected Object Features on a Pick-and-Place Task: a Human Multimodal Dataset
Jul 18, 2024We propose a dataset to study the influence of object-specific characteristics on human pick-and-place movements and compare the quality of the motion kinematics extracted by various sensors. This dataset is also suitable for promoting a broader discussion on general learning problems in the hand-object interaction domain, such as intention recognition or motion generation with applications in the Robotics field. The dataset consists of the recordings of 15 subjects performing 80 repetitions of a pick-and-place action under various experimental conditions, for a total of 1200 pick-and-places. The data has been collected thanks to a multimodal setup composed of multiple cameras, observing the actions from different perspectives, a motion capture system, and a wrist-worn inertial measurement unit. All the objects manipulated in the experiments are identical in shape, size, and appearance but differ in weight and liquid filling, which influences the carefulness required for their handling.
* Camera ready version. Full paper available in open-access at https://doi.org/10.1177/02783649231210965 Dataset available on Kaggle (DOI: 10.34740/KAGGLE/DS/2319925, https://www.kaggle.com/datasets/alessandrocarf/effects-of-object-characteristics-on-manipulations)
How much informative is your XAI? A decision-making assessment task to objectively measure the goodness of explanations
Dec 07, 2023


There is an increasing consensus about the effectiveness of user-centred approaches in the explainable artificial intelligence (XAI) field. Indeed, the number and complexity of personalised and user-centred approaches to XAI have rapidly grown in recent years. Often, these works have a two-fold objective: (1) proposing novel XAI techniques able to consider the users and (2) assessing the \textit{goodness} of such techniques with respect to others. From these new works, it emerged that user-centred approaches to XAI positively affect the interaction between users and systems. However, so far, the goodness of XAI systems has been measured through indirect measures, such as performance. In this paper, we propose an assessment task to objectively and quantitatively measure the goodness of XAI systems in terms of their \textit{information power}, which we intended as the amount of information the system provides to the users during the interaction. Moreover, we plan to use our task to objectively compare two XAI techniques in a human-robot decision-making task to understand deeper whether user-centred approaches are more informative than classical ones.
Real-time Addressee Estimation: Deployment of a Deep-Learning Model on the iCub Robot
Nov 09, 2023Addressee Estimation is the ability to understand to whom a person is talking, a skill essential for social robots to interact smoothly with humans. In this sense, it is one of the problems that must be tackled to develop effective conversational agents in multi-party and unstructured scenarios. As humans, one of the channels that mainly lead us to such estimation is the non-verbal behavior of speakers: first of all, their gaze and body pose. Inspired by human perceptual skills, in the present work, a deep-learning model for Addressee Estimation relying on these two non-verbal features is designed, trained, and deployed on an iCub robot. The study presents the procedure of such implementation and the performance of the model deployed in real-time human-robot interaction compared to previous tests on the dataset used for the training.
Expressing and Inferring Action Carefulness in Human-to-Robot Handovers
Sep 30, 2023Implicit communication plays such a crucial role during social exchanges that it must be considered for a good experience in human-robot interaction. This work addresses implicit communication associated with the detection of physical properties, transport, and manipulation of objects. We propose an ecological approach to infer object characteristics from subtle modulations of the natural kinematics occurring during human object manipulation. Similarly, we take inspiration from human strategies to shape robot movements to be communicative of the object properties while pursuing the action goals. In a realistic HRI scenario, participants handed over cups - filled with water or empty - to a robotic manipulator that sorted them. We implemented an online classifier to differentiate careful/not careful human movements, associated with the cups' content. We compared our proposed "expressive" controller, which modulates the movements according to the cup filling, against a neutral motion controller. Results show that human kinematics is adjusted during the task, as a function of the cup content, even in reach-to-grasp motion. Moreover, the carefulness during the handover of full cups can be reliably inferred online, well before action completion. Finally, although questionnaires did not reveal explicit preferences from participants, the expressive robot condition improved task efficiency.
To Whom are You Talking? A Deep Learning Model to Endow Social Robots with Addressee Estimation Skills
Aug 21, 2023
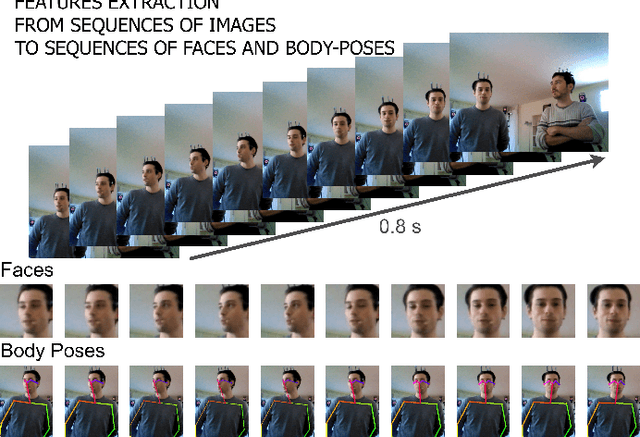

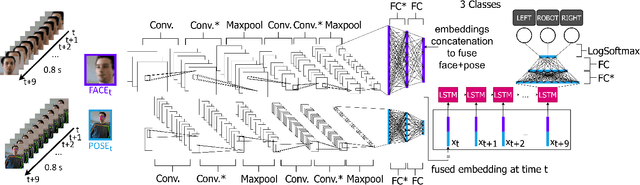
Communicating shapes our social word. For a robot to be considered social and being consequently integrated in our social environment it is fundamental to understand some of the dynamics that rule human-human communication. In this work, we tackle the problem of Addressee Estimation, the ability to understand an utterance's addressee, by interpreting and exploiting non-verbal bodily cues from the speaker. We do so by implementing an hybrid deep learning model composed of convolutional layers and LSTM cells taking as input images portraying the face of the speaker and 2D vectors of the speaker's body posture. Our implementation choices were guided by the aim to develop a model that could be deployed on social robots and be efficient in ecological scenarios. We demonstrate that our model is able to solve the Addressee Estimation problem in terms of addressee localisation in space, from a robot ego-centric point of view.
* Accepted version of a paper published at 2023 International Joint Conference on Neural Networks (IJCNN). Please find the published version and info to cite the paper at https://doi.org/10.1109/IJCNN54540.2023.10191452 . 10 pages, 8 Figures, 3 Tables
I am Only Happy When There is Light: The Impact of Environmental Changes on Affective Facial Expressions Recognition
Oct 28, 2022
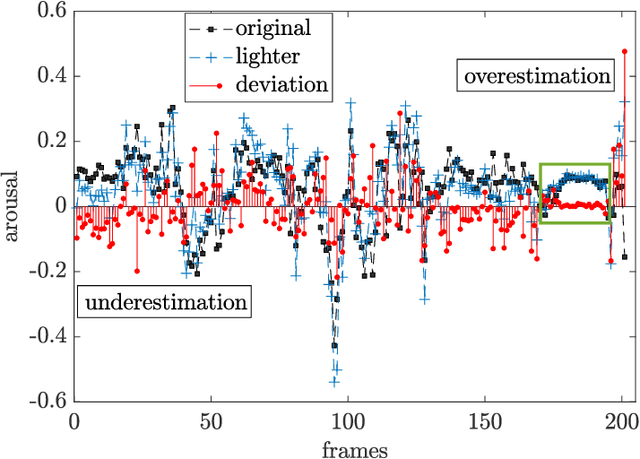
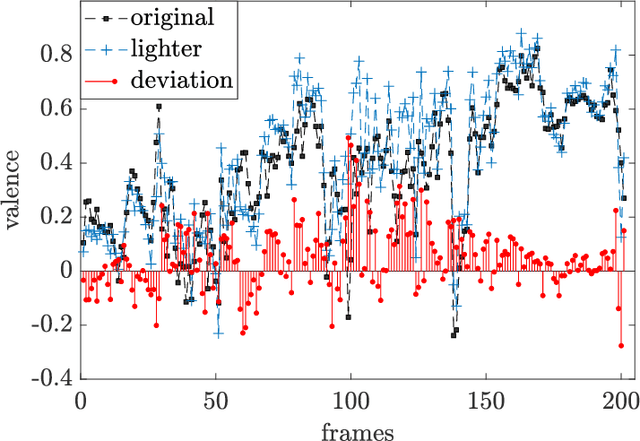
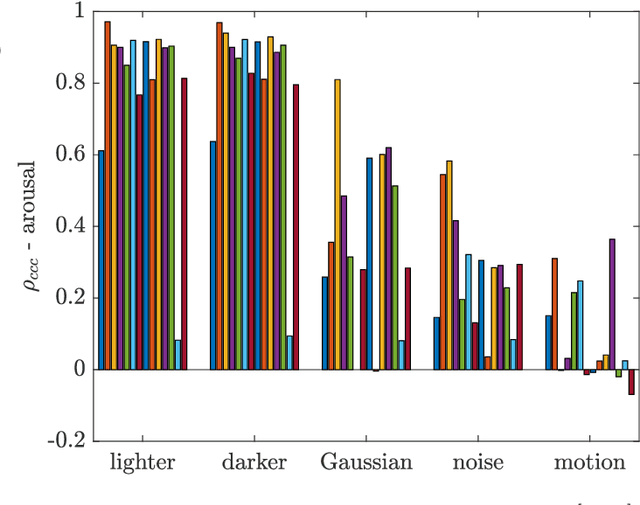
Human-robot interaction (HRI) benefits greatly from advances in the machine learning field as it allows researchers to employ high-performance models for perceptual tasks like detection and recognition. Especially deep learning models, either pre-trained for feature extraction or used for classification, are now established methods to characterize human behaviors in HRI scenarios and to have social robots that understand better those behaviors. As HRI experiments are usually small-scale and constrained to particular lab environments, the questions are how well can deep learning models generalize to specific interaction scenarios, and further, how good is their robustness towards environmental changes? These questions are important to address if the HRI field wishes to put social robotic companions into real environments acting consistently, i.e. changing lighting conditions or moving people should still produce the same recognition results. In this paper, we study the impact of different image conditions on the recognition of arousal and valence from human facial expressions using the FaceChannel framework \cite{Barro20}. Our results show how the interpretation of human affective states can differ greatly in either the positive or negative direction even when changing only slightly the image properties. We conclude the paper with important points to consider when employing deep learning models to ensure sound interpretation of HRI experiments.