 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Prediction of Human Motions and Actions in Human-Robot Collaboration
Apr 03, 2026Fluent human--robot collaboration requires robots to continuously estimate human behaviour and anticipate future intentions. This entails reasoning jointly about \emph{continuous movements} and \emph{discrete actions}, which are still largely modelled in isolation. In this paper, we introduce \textsf{MA-HERP}, a hierarchical and recursive probabilistic framework for the \emph{joint estimation and prediction} of human movements and actions. The model combines: (i) a hierarchical representation in which movements compose into actions through admissible Allen interval relations, (ii) a unified probabilistic factorisation coupling continuous dynamics, discrete labels, and durations, and (iii) a recursive inference scheme inspired by Bayesian filtering, alternating top-down action prediction with bottom-up sensory evidence. We present a preliminary experimental evaluation based on neural models trained on musculoskeletal simulations of reaching movements, showing accurate motion prediction, robust action inference under noise, and computational performance compatible with on-line human--robot collaboration.
A Distributed Multi-Modal Sensing Approach for Human Activity Recognition in Real-Time Human-Robot Collaboration
Feb 02, 2026Human activity recognition (HAR) is fundamental in human-robot collaboration (HRC), enabling robots to respond to and dynamically adapt to human intentions. This paper introduces a HAR system combining a modular data glove equipped with Inertial Measurement Units and a vision-based tactile sensor to capture hand activities in contact with a robot. We tested our activity recognition approach under different conditions, including offline classification of segmented sequences, real-time classification under static conditions, and a realistic HRC scenario. The experimental results show a high accuracy for all the tasks, suggesting that multiple collaborative settings could benefit from this multi-modal approach.
Factored Reasoning with Inner Speech and Persistent Memory for Evidence-Grounded Human-Robot Interaction
Jan 31, 2026Dialogue-based human-robot interaction requires robot cognitive assistants to maintain persistent user context, recover from underspecified requests, and ground responses in external evidence, while keeping intermediate decisions verifiable. In this paper we introduce JANUS, a cognitive architecture for assistive robots that models interaction as a partially observable Markov decision process and realizes control as a factored controller with typed interfaces. To this aim, Janus (i) decomposes the overall behavior into specialized modules, related to scope detection, intent recognition, memory, inner speech, query generation, and outer speech, and (ii) exposes explicit policies for information sufficiency, execution readiness, and tool grounding. A dedicated memory agent maintains a bounded recent-history buffer, a compact core memory, and an archival store with semantic retrieval, coupled through controlled consolidation and revision policies. Models inspired by the notion of inner speech in cognitive theories provide a control-oriented internal textual flow that validates parameter completeness and triggers clarification before grounding, while a faithfulness constraint ties robot-to-human claims to an evidence bundle combining working context and retrieved tool outputs. We evaluate JANUS through module-level unit tests in a dietary assistance domain grounded on a knowledge graph, reporting high agreement with curated references and practical latency profiles. These results support factored reasoning as a promising path to scalable, auditable, and evidence-grounded robot assistance over extended interaction horizons.
On the Generalization Gap in LLM Planning: Tests and Verifier-Reward RL
Jan 20, 2026Recent work shows that fine-tuned Large Language Models (LLMs) can achieve high valid plan rates on PDDL planning tasks. However, it remains unclear whether this reflects transferable planning competence or domain-specific memorization. In this work, we fine-tune a 1.7B-parameter LLM on 40,000 domain-problem-plan tuples from 10 IPC 2023 domains, and evaluate both in-domain and cross-domain generalization. While the model reaches 82.9% valid plan rate in in-domain conditions, it achieves 0% on two unseen domains. To analyze this failure, we introduce three diagnostic interventions, namely (i) instance-wise symbol anonymization, (ii) compact plan serialization, and (iii) verifier-reward fine-tuning using the VAL validator as a success-focused reinforcement signal. Symbol anonymization and compact serialization cause significant performance drops despite preserving plan semantics, thus revealing strong sensitivity to surface representations. Verifier-reward fine-tuning reaches performance saturation in half the supervised training epochs, but does not improve cross-domain generalization. For the explored configurations, in-domain performance plateaus around 80%, while cross-domain performance collapses, suggesting that our fine-tuned model relies heavily on domain-specific patterns rather than transferable planning competence in this setting. Our results highlight a persistent generalization gap in LLM-based planning and provide diagnostic tools for studying its causes.
An Event-Based Opto-Tactile Skin
Jan 07, 2026This paper presents a neuromorphic, event-driven tactile sensing system for soft, large-area skin, based on the Dynamic Vision Sensors (DVS) integrated with a flexible silicone optical waveguide skin. Instead of repetitively scanning embedded photoreceivers, this design uses a stereo vision setup comprising two DVS cameras looking sideways through the skin. Such a design produces events as changes in brightness are detected, and estimates press positions on the 2D skin surface through triangulation, utilizing Density-Based Spatial Clustering of Applications with Noise (DBSCAN) to find the center of mass of contact events resulting from pressing actions. The system is evaluated over a 4620 mm2 probed area of the skin using a meander raster scan. Across 95 % of the presses visible to both cameras, the press localization achieved a Root-Mean-Squared Error (RMSE) of 4.66 mm. The results highlight the potential of this approach for wide-area flexible and responsive tactile sensors in soft robotics and interactive environments. Moreover, we examined how the system performs when the amount of event data is strongly reduced. Using stochastic down-sampling, the event stream was reduced to 1/1024 of its original size. Under this extreme reduction, the average localization error increased only slightly (from 4.66 mm to 9.33 mm), and the system still produced valid press localizations for 85 % of the trials. This reduction in pass rate is expected, as some presses no longer produce enough events to form a reliable cluster for triangulation. These results show that the sensing approach remains functional even with very sparse event data, which is promising for reducing power consumption and computational load in future implementations. The system exhibits a detection latency distribution with a characteristic width of 31 ms.
Locally Optimal Solutions to Constraint Displacement Problems via Path-Obstacle Overlaps
Nov 15, 2025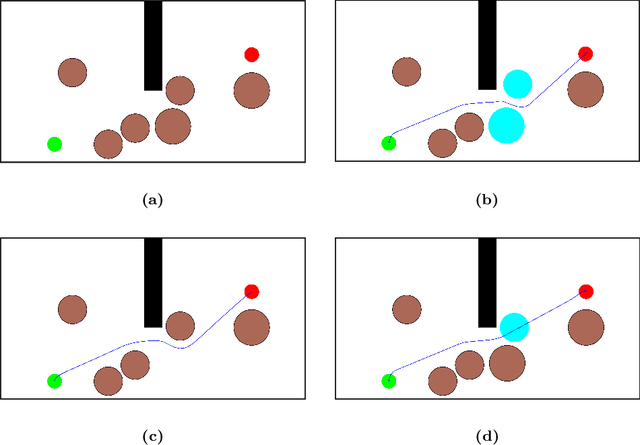
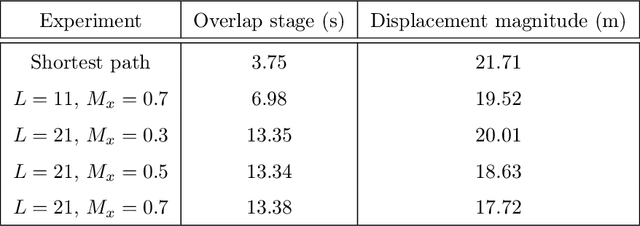
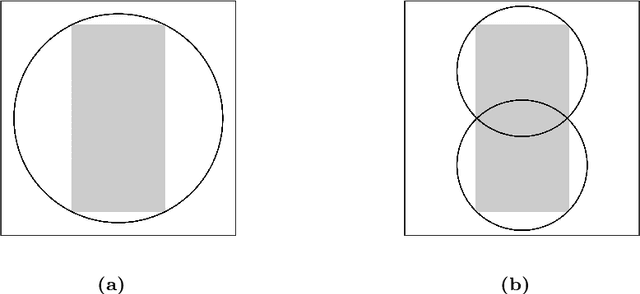
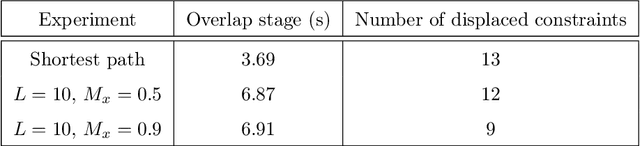
We present a unified approach for constraint displacement problems in which a robot finds a feasible path by displacing constraints or obstacles. To this end, we propose a two stage process that returns locally optimal obstacle displacements to enable a feasible path for the robot. The first stage proceeds by computing a trajectory through the obstacles while minimizing an appropriate objective function. In the second stage, these obstacles are displaced to make the computed robot trajectory feasible, that is, collision-free. Several examples are provided that successfully demonstrate our approach on two distinct classes of constraint displacement problems.
Achieving Scalable Robot Autonomy via neurosymbolic planning using lightweight local LLM
May 13, 2025PDDL-based symbolic task planning remains pivotal for robot autonomy yet struggles with dynamic human-robot collaboration due to scalability, re-planning demands, and delayed plan availability. Although a few neurosymbolic frameworks have previously leveraged LLMs such as GPT-3 to address these challenges, reliance on closed-source, remote models with limited context introduced critical constraints: third-party dependency, inconsistent response times, restricted plan length and complexity, and multi-domain scalability issues. We present Gideon, a novel framework that enables the transition to modern, smaller, local LLMs with extended context length. Gideon integrates a novel problem generator to systematically generate large-scale datasets of realistic domain-problem-plan tuples for any domain, and adapts neurosymbolic planning for local LLMs, enabling on-device execution and extended context for multi-domain support. Preliminary experiments in single-domain scenarios performed on Qwen-2.5 1.5B and trained on 8k-32k samples, demonstrate a valid plan percentage of 66.1% (32k model) and show that the figure can be further scaled through additional data. Multi-domain tests on 16k samples yield an even higher 70.6% planning validity rate, proving extensibility across domains and signaling that data variety can have a positive effect on learning efficiency. Although long-horizon planning and reduced model size make Gideon training much less efficient than baseline models based on larger LLMs, the results are still significant considering that the trained model is about 120x smaller than baseline and that significant advantages can be achieved in inference efficiency, scalability, and multi-domain adaptability, all critical factors in human-robot collaboration. Training inefficiency can be mitigated by Gideon's streamlined data generation pipeline.
A Comparative Study of Human Activity Recognition: Motion, Tactile, and multi-modal Approaches
May 13, 2025Human activity recognition (HAR) is essential for effective Human-Robot Collaboration (HRC), enabling robots to interpret and respond to human actions. This study evaluates the ability of a vision-based tactile sensor to classify 15 activities, comparing its performance to an IMU-based data glove. Additionally, we propose a multi-modal framework combining tactile and motion data to leverage their complementary strengths. We examined three approaches: motion-based classification (MBC) using IMU data, tactile-based classification (TBC) with single or dual video streams, and multi-modal classification (MMC) integrating both. Offline validation on segmented datasets assessed each configuration's accuracy under controlled conditions, while online validation on continuous action sequences tested online performance. Results showed the multi-modal approach consistently outperformed single-modality methods, highlighting the potential of integrating tactile and motion sensing to enhance HAR systems for collaborative robotics.
A Social Robot with Inner Speech for Dietary Guidance
May 13, 2025We explore the use of inner speech as a mechanism to enhance transparency and trust in social robots for dietary advice. In humans, inner speech structures thought processes and decision-making; in robotics, it improves explainability by making reasoning explicit. This is crucial in healthcare scenarios, where trust in robotic assistants depends on both accurate recommendations and human-like dialogue, which make interactions more natural and engaging. Building on this, we developed a social robot that provides dietary advice, and we provided the architecture with inner speech capabilities to validate user input, refine reasoning, and generate clear justifications. The system integrates large language models for natural language understanding and a knowledge graph for structured dietary information. By making decisions more transparent, our approach strengthens trust and improves human-robot interaction in healthcare. We validated this by measuring the computational efficiency of our architecture and conducting a small user study, which assessed the reliability of inner speech in explaining the robot's behavior.
A Task and Motion Planning Framework Using Iteratively Deepened AND/OR Graph Networks
Mar 10, 2025In this paper, we present an approach for integrated task and motion planning based on an AND/OR graph network, which is used to represent task-level states and actions, and we leverage it to implement different classes of task and motion planning problems (TAMP). Several problems that fall under task and motion planning do not have a predetermined number of sub-tasks to achieve a goal. For example, while retrieving a target object from a cluttered workspace, in principle the number of object re-arrangements required to finally grasp it cannot be known ahead of time. To address this challenge, and in contrast to traditional planners, also those based on AND/OR graphs, we grow the AND/OR graph at run-time by progressively adding sub-graphs until grasping the target object becomes feasible, which yields a network of AND/OR graphs. The approach is extended to enable multi-robot task and motion planning, and (i) it allows us to perform task allocation while coordinating the activity of a given number of robots, and (ii) can handle multi-robot tasks involving an a priori unknown number of sub-tasks. The approach is evaluated and validated both in simulation and with a real dual-arm robot manipulator, that is, Baxter from Rethink Robotics. In particular, for the single-robot task and motion planning, we validated our approach in three different TAMP domains. Furthermore, we also use three different robots for simulation, namely, Baxter, Franka Emika Panda manipulators, and a PR2 robot. Experiments show that our approach can be readily scaled to scenarios with many objects and robots, and is capable of handling different classes of TAMP problems.