 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Selected Object Features on a Pick-and-Place Task: a Human Multimodal Dataset
Jul 18, 2024We propose a dataset to study the influence of object-specific characteristics on human pick-and-place movements and compare the quality of the motion kinematics extracted by various sensors. This dataset is also suitable for promoting a broader discussion on general learning problems in the hand-object interaction domain, such as intention recognition or motion generation with applications in the Robotics field. The dataset consists of the recordings of 15 subjects performing 80 repetitions of a pick-and-place action under various experimental conditions, for a total of 1200 pick-and-places. The data has been collected thanks to a multimodal setup composed of multiple cameras, observing the actions from different perspectives, a motion capture system, and a wrist-worn inertial measurement unit. All the objects manipulated in the experiments are identical in shape, size, and appearance but differ in weight and liquid filling, which influences the carefulness required for their handling.
* Camera ready version. Full paper available in open-access at https://doi.org/10.1177/02783649231210965 Dataset available on Kaggle (DOI: 10.34740/KAGGLE/DS/2319925, https://www.kaggle.com/datasets/alessandrocarf/effects-of-object-characteristics-on-manipulations)
Careful with That! Observation of Human Movements to Estimate Objects Properties
Mar 10, 2021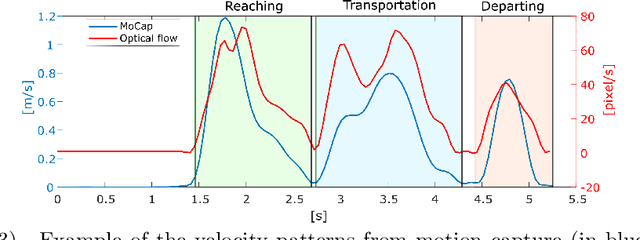
Humans are very effective at interpreting subtle properties of the partner's movement and use this skill to promote smooth interactions. Therefore, robotic platforms that support human partners in daily activities should acquire similar abilities. In this work we focused on the features of human motor actions that communicate insights on the weight of an object and the carefulness required in its manipulation. Our final goal is to enable a robot to autonomously infer the degree of care required in object handling and to discriminate whether the item is light or heavy, just by observing a human manipulation. This preliminary study represents a promising step towards the implementation of those abilities on a robot observing the scene with its camera. Indeed, we succeeded in demonstrating that it is possible to reliably deduct if the human operator is careful when handling an object, through machine learning algorithms relying on the stream of visual acquisition from either a robot camera or from a motion capture system. On the other hand, we observed that the same approach is inadequate to discriminate between light and heavy objects.
* Preprint version - 13th International Workshop of Human-Friendly Robotics (HFR 2020)
Action similarity judgment based on kinematic primitives
Aug 30, 2020
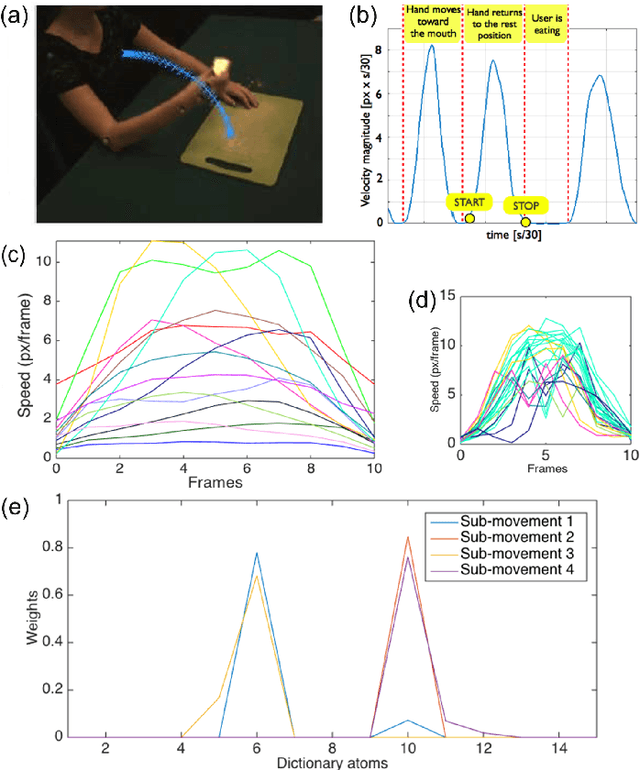
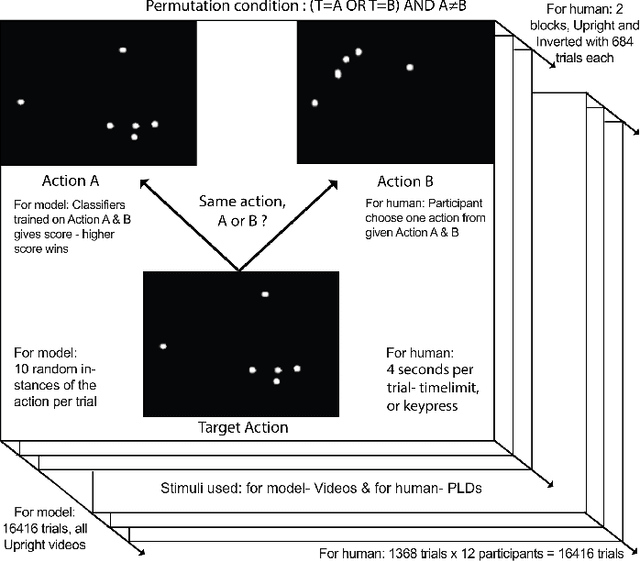
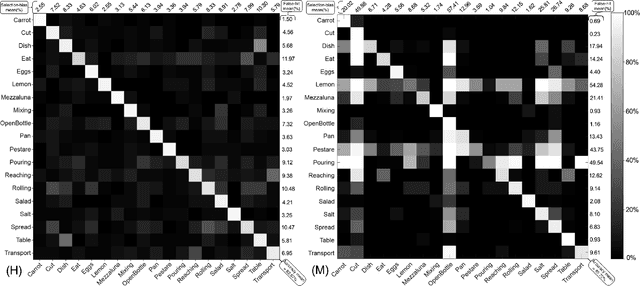
Understanding which features humans rely on -- in visually recognizing action similarity is a crucial step towards a clearer picture of human action perception from a learning and developmental perspective. In the present work, we investigate to which extent a computational model based on kinematics can determine action similarity and how its performance relates to human similarity judgments of the same actions. To this aim, twelve participants perform an action similarity task, and their performances are compared to that of a computational model solving the same task. The chosen model has its roots in developmental robotics and performs action classification based on learned kinematic primitives. The comparative experiment results show that both the model and human participants can reliably identify whether two actions are the same or not. However, the model produces more false hits and has a greater selection bias than human participants. A possible reason for this is the particular sensitivity of the model towards kinematic primitives of the presented actions. In a second experiment, human participants' performance on an action identification task indicated that they relied solely on kinematic information rather than on action semantics. The results show that both the model and human performance are highly accurate in an action similarity task based on kinematic-level features, which can provide an essential basis for classifying human actions.