 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Deep RL and Bayesian Inference for ObjectNav in Mobile Robotics
Mar 26, 2026Autonomous object search is challenging for mobile robots operating in indoor environments due to partial observability, perceptual uncertainty, and the need to trade off exploration and navigation efficiency. Classical probabilistic approaches explicitly represent uncertainty but typically rely on handcrafted action-selection heuristics, while deep reinforcement learning enables adaptive policies but often suffers from slow convergence and limited interpretability. This paper proposes a hybrid object-search framework that integrates Bayesian inference with deep reinforcement learning. The method maintains a spatial belief map over target locations, updated online through Bayesian inference from calibrated object detections, and trains a reinforcement learning policy to select navigation actions directly from this probabilistic representation. The approach is evaluated in realistic indoor simulation using Habitat 3.0 and compared against developed baseline strategies. Across two indoor environments, the proposed method improves success rate while reducing search effort. Overall, the results support the value of combining Bayesian belief estimation with learned action selection to achieve more efficient and reliable objectsearch behavior under partial observability.
Task-oriented grasping for dexterous robots using postural synergies and reinforcement learning
Feb 24, 2026In this paper, we address the problem of task-oriented grasping for humanoid robots, emphasizing the need to align with human social norms and task-specific objectives. Existing methods, employ a variety of open-loop and closed-loop approaches but lack an end-to-end solution that can grasp several objects while taking into account the downstream task's constraints. Our proposed approach employs reinforcement learning to enhance task-oriented grasping, prioritizing the post-grasp intention of the agent. We extract human grasp preferences from the ContactPose dataset, and train a hand synergy model based on the Variational Autoencoder (VAE) to imitate the participant's grasping actions. Based on this data, we train an agent able to grasp multiple objects while taking into account distinct post-grasp intentions that are task-specific. By combining data-driven insights from human grasping behavior with learning by exploration provided by reinforcement learning, we can develop humanoid robots capable of context-aware manipulation actions, facilitating collaboration in human-centered environments.
GRASPLAT: Enabling dexterous grasping through novel view synthesis
Oct 22, 2025Achieving dexterous robotic grasping with multi-fingered hands remains a significant challenge. While existing methods rely on complete 3D scans to predict grasp poses, these approaches face limitations due to the difficulty of acquiring high-quality 3D data in real-world scenarios. In this paper, we introduce GRASPLAT, a novel grasping framework that leverages consistent 3D information while being trained solely on RGB images. Our key insight is that by synthesizing physically plausible images of a hand grasping an object, we can regress the corresponding hand joints for a successful grasp. To achieve this, we utilize 3D Gaussian Splatting to generate high-fidelity novel views of real hand-object interactions, enabling end-to-end training with RGB data. Unlike prior methods, our approach incorporates a photometric loss that refines grasp predictions by minimizing discrepancies between rendered and real images. We conduct extensive experiments on both synthetic and real-world grasping datasets, demonstrating that GRASPLAT improves grasp success rates up to 36.9% over existing image-based methods. Project page: https://mbortolon97.github.io/grasplat/
The Role of Touch: Towards Optimal Tactile Sensing Distribution in Anthropomorphic Hands for Dexterous In-Hand Manipulation
Sep 18, 2025In-hand manipulation tasks, particularly in human-inspired robotic systems, must rely on distributed tactile sensing to achieve precise control across a wide variety of tasks. However, the optimal configuration of this network of sensors is a complex problem, and while the fingertips are a common choice for placing sensors, the contribution of tactile information from other regions of the hand is often overlooked. This work investigates the impact of tactile feedback from various regions of the fingers and palm in performing in-hand object reorientation tasks. We analyze how sensory feedback from different parts of the hand influences the robustness of deep reinforcement learning control policies and investigate the relationship between object characteristics and optimal sensor placement. We identify which tactile sensing configurations contribute to improving the efficiency and accuracy of manipulation. Our results provide valuable insights for the design and use of anthropomorphic end-effectors with enhanced manipulation capabilities.
HERB: Human-augmented Efficient Reinforcement learning for Bin-packing
Apr 23, 2025Packing objects efficiently is a fundamental problem in logistics, warehouse automation, and robotics. While traditional packing solutions focus on geometric optimization, packing irregular, 3D objects presents significant challenges due to variations in shape and stability. Reinforcement Learning~(RL) has gained popularity in robotic packing tasks, but training purely from simulation can be inefficient and computationally expensive. In this work, we propose HERB, a human-augmented RL framework for packing irregular objects. We first leverage human demonstrations to learn the best sequence of objects to pack, incorporating latent factors such as space optimization, stability, and object relationships that are difficult to model explicitly. Next, we train a placement algorithm that uses visual information to determine the optimal object positioning inside a packing container. Our approach is validated through extensive performance evaluations, analyzing both packing efficiency and latency. Finally, we demonstrate the real-world feasibility of our method on a robotic system. Experimental results show that our method outperforms geometric and purely RL-based approaches by leveraging human intuition, improving both packing robustness and adaptability. This work highlights the potential of combining human expertise-driven RL to tackle complex real-world packing challenges in robotic systems.
Extending 3D body pose estimation for robotic-assistive therapies of autistic children
Feb 12, 2024Robotic-assistive therapy has demonstrated very encouraging results for children with Autism. Accurate estimation of the child's pose is essential both for human-robot interaction and for therapy assessment purposes. Non-intrusive methods are the sole viable option since these children are sensitive to touch. While depth cameras have been used extensively, existing methods face two major limitations: (i) they are usually trained with adult-only data and do not correctly estimate a child's pose, and (ii) they fail in scenarios with a high number of occlusions. Therefore, our goal was to develop a 3D pose estimator for children, by adapting an existing state-of-the-art 3D body modelling method and incorporating a linear regression model to fine-tune one of its inputs, thereby correcting the pose of children's 3D meshes. In controlled settings, our method has an error below $0.3m$, which is considered acceptable for this kind of application and lower than current state-of-the-art methods. In real-world settings, the proposed model performs similarly to a Kinect depth camera and manages to successfully estimate the 3D body poses in a much higher number of frames.
Gaussian Mixture Models for Affordance Learning using Bayesian Networks
Feb 08, 2024Affordances are fundamental descriptors of relationships between actions, objects and effects. They provide the means whereby a robot can predict effects, recognize actions, select objects and plan its behavior according to desired goals. This paper approaches the problem of an embodied agent exploring the world and learning these affordances autonomously from its sensory experiences. Models exist for learning the structure and the parameters of a Bayesian Network encoding this knowledge. Although Bayesian Networks are capable of dealing with uncertainty and redundancy, previous work considered complete observability of the discrete sensory data, which may lead to hard errors in the presence of noise. In this paper we consider a probabilistic representation of the sensors by Gaussian Mixture Models (GMMs) and explicitly taking into account the probability distribution contained in each discrete affordance concept, which can lead to a more correct learning.
* IEEE/RSJ International Conference on Intelligent Robots and Systems 2010
Expressing and Inferring Action Carefulness in Human-to-Robot Handovers
Sep 30, 2023Implicit communication plays such a crucial role during social exchanges that it must be considered for a good experience in human-robot interaction. This work addresses implicit communication associated with the detection of physical properties, transport, and manipulation of objects. We propose an ecological approach to infer object characteristics from subtle modulations of the natural kinematics occurring during human object manipulation. Similarly, we take inspiration from human strategies to shape robot movements to be communicative of the object properties while pursuing the action goals. In a realistic HRI scenario, participants handed over cups - filled with water or empty - to a robotic manipulator that sorted them. We implemented an online classifier to differentiate careful/not careful human movements, associated with the cups' content. We compared our proposed "expressive" controller, which modulates the movements according to the cup filling, against a neutral motion controller. Results show that human kinematics is adjusted during the task, as a function of the cup content, even in reach-to-grasp motion. Moreover, the carefulness during the handover of full cups can be reliably inferred online, well before action completion. Finally, although questionnaires did not reveal explicit preferences from participants, the expressive robot condition improved task efficiency.
If You Are Careful, So Am I! How Robot Communicative Motions Can Influence Human Approach in a Joint Task
Oct 24, 2022As humans, we have a remarkable capacity for reading the characteristics of objects only by observing how another person carries them. Indeed, how we perform our actions naturally embeds information on the item features. Collaborative robots can achieve the same ability by modulating the strategy used to transport objects with their end-effector. A contribution in this sense would promote spontaneous interactions by making an implicit yet effective communication channel available. This work investigates if humans correctly perceive the implicit information shared by a robotic manipulator through its movements during a dyadic collaboration task. Exploiting a generative approach, we designed robot actions to convey virtual properties of the transported objects, particularly to inform the partner if any caution is required to handle the carried item. We found that carefulness is correctly interpreted when observed through the robot movements. In the experiment, we used identical empty plastic cups; nevertheless, participants approached them differently depending on the attitude shown by the robot: humans change how they reach for the object, being more careful whenever the robot does the same. This emerging form of motor contagion is entirely spontaneous and happens even if the task does not require it.
Robotic Learning the Sequence of Packing Irregular Objects from Human Demonstrations
Oct 04, 2022


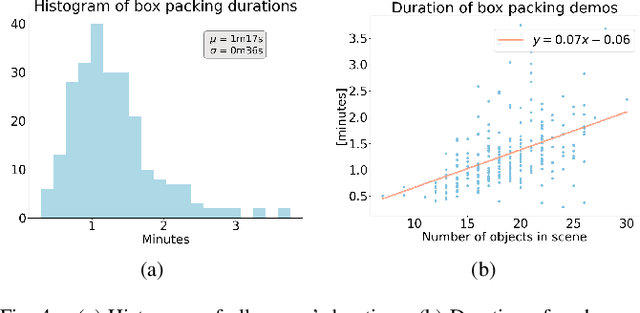
We address the unsolved task of robotic bin packing with irregular objects, such as groceries, where the underlying constraints on object placement and manipulation, and the diverse objects' physical properties make preprogrammed strategies unfeasible. Our approach is to learn directly from expert demonstrations in order to extract implicit task knowledge and strategies to achieve an efficient space usage, safe object positioning and to generate human-like behaviors that enhance human-robot trust. We collect and make available a novel and diverse dataset, BoxED, of box packing demonstrations by humans in virtual reality. In total, 263 boxes were packed with supermarket-like objects by 43 participants, yielding 4644 object manipulations. We use the BoxED dataset to learn a Markov chain to predict the object packing sequence for a given set of objects and compare it with human performance. Our experimental results show that the model surpasses human performance by generating sequence predictions that humans classify as human-like more frequently than human-generated sequences.