 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocating Demographic Bias at the Attention-Head Level in CLIP's Vision Encoder
Mar 12, 2026Standard fairness audits of foundation models quantify that a model is biased, but not where inside the network the bias resides. We propose a mechanistic fairness audit that combines projected residual-stream decomposition, zero-shot Concept Activation Vectors, and bias-augmented TextSpan analysis to locate demographic bias at the level of individual attention heads in vision transformers. As a feasibility case study, we apply this pipeline to the CLIP ViT-L-14 encoder on 42 profession classes of the FACET benchmark, auditing both gender and age bias. For gender, the pipeline identifies four terminal-layer heads whose ablation reduces global bias (Cramer's V: 0.381 -> 0.362) while marginally improving accuracy (+0.42%); a layer-matched random control confirms that this effect is specific to the identified heads. A single head in the final layer contributes to the majority of the reduction in the most stereotyped classes, and class-level analysis shows that corrected predictions shift toward the correct occupation. For age, the same pipeline identifies candidate heads, but ablation produces weaker and less consistent effects, suggesting that age bias is encoded more diffusely than gender bias in this model. These results provide preliminary evidence that head-level bias localisation is feasible for discriminative vision encoders and that the degree of localisability may vary across protected attributes. keywords: Bias . CLIP . Mechanistic Interpretability . Vision Transformer . Fairness
Prediction of 30-day hospital readmission with clinical notes and EHR information
Mar 29, 2025



High hospital readmission rates are associated with significant costs and health risks for patients. Therefore, it is critical to develop predictive models that can support clinicians to determine whether or not a patient will return to the hospital in a relatively short period of time (e.g, 30-days). Nowadays, it is possible to collect both structured (electronic health records - EHR) and unstructured information (clinical notes) about a patient hospital event, all potentially containing relevant information for a predictive model. However, their integration is challenging. In this work we explore the combination of clinical notes and EHRs to predict 30-day hospital readmissions. We address the representation of the various types of information available in the EHR data, as well as exploring LLMs to characterize the clinical notes. We collect both information sources as the nodes of a graph neural network (GNN). Our model achieves an AUROC of 0.72 and a balanced accuracy of 66.7\%, highlighting the importance of combining the multimodal information.
MIL vs. Aggregation: Evaluating Patient-Level Survival Prediction Strategies Using Graph-Based Learning
Mar 29, 2025Oncologists often rely on a multitude of data, including whole-slide images (WSIs), to guide therapeutic decisions, aiming for the best patient outcome. However, predicting the prognosis of cancer patients can be a challenging task due to tumor heterogeneity and intra-patient variability, and the complexity of analyzing WSIs. These images are extremely large, containing billions of pixels, making direct processing computationally expensive and requiring specialized methods to extract relevant information. Additionally, multiple WSIs from the same patient may capture different tumor regions, some being more informative than others. This raises a fundamental question: Should we use all WSIs to characterize the patient, or should we identify the most representative slide for prognosis? Our work seeks to answer this question by performing a comparison of various strategies for predicting survival at the WSI and patient level. The former treats each WSI as an independent sample, mimicking the strategy adopted in other works, while the latter comprises methods to either aggregate the predictions of the several WSIs or automatically identify the most relevant slide using multiple-instance learning (MIL). Additionally, we evaluate different Graph Neural Networks architectures under these strategies. We conduct our experiments using the MMIST-ccRCC dataset, which comprises patients with clear cell renal cell carcinoma (ccRCC). Our results show that MIL-based selection improves accuracy, suggesting that choosing the most representative slide benefits survival prediction.
The Role of Graph-based MIL and Interventional Training in the Generalization of WSI Classifiers
Jan 31, 2025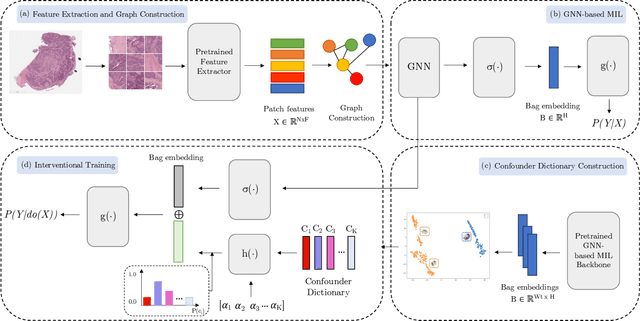



Whole Slide Imaging (WSI), which involves high-resolution digital scans of pathology slides, has become the gold standard for cancer diagnosis, but its gigapixel resolution and the scarcity of annotated datasets present challenges for deep learning models. Multiple Instance Learning (MIL), a widely-used weakly supervised approach, bypasses the need for patch-level annotations. However, conventional MIL methods overlook the spatial relationships between patches, which are crucial for tasks such as cancer grading and diagnosis. To address this, graph-based approaches have gained prominence by incorporating spatial information through node connections. Despite their potential, both MIL and graph-based models are vulnerable to learning spurious associations, like color variations in WSIs, affecting their robustness. In this dissertation, we conduct an extensive comparison of multiple graph construction techniques, MIL models, graph-MIL approaches, and interventional training, introducing a new framework, Graph-based Multiple Instance Learning with Interventional Training (GMIL-IT), for WSI classification. We evaluate their impact on model generalization through domain shift analysis and demonstrate that graph-based models alone achieve the generalization initially anticipated from interventional training. Our code is available here: github.com/ritamartinspereira/GMIL-IT
Continual Deep Active Learning for Medical Imaging: Replay-Base Architecture for Context Adaptation
Jan 14, 2025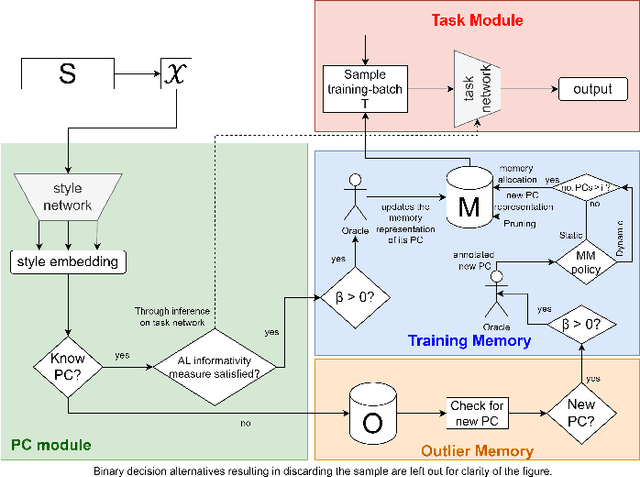
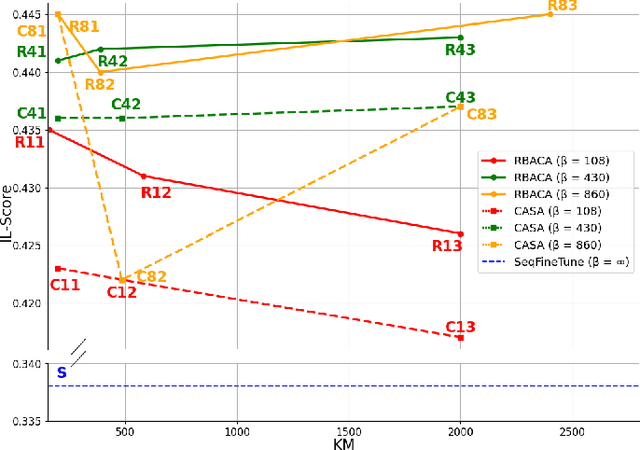
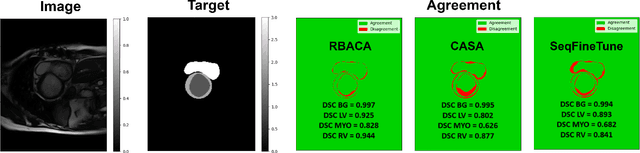
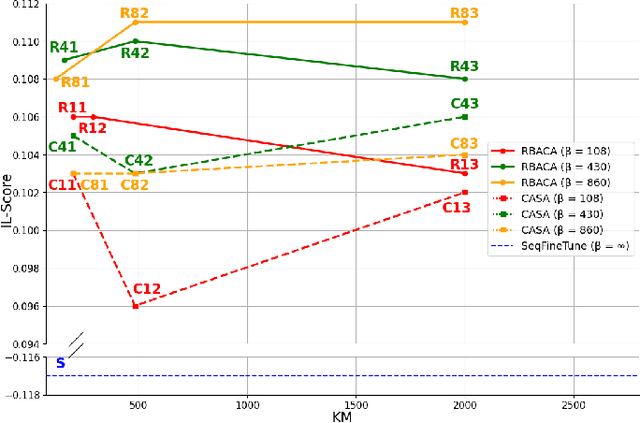
Deep Learning for medical imaging faces challenges in adapting and generalizing to new contexts. Additionally, it often lacks sufficient labeled data for specific tasks requiring significant annotation effort. Continual Learning (CL) tackles adaptability and generalizability by enabling lifelong learning from a data stream while mitigating forgetting of previously learned knowledge. Active Learning (AL) reduces the number of required annotations for effective training. This work explores both approaches (CAL) to develop a novel framework for robust medical image analysis. Based on the automatic recognition of shifts in image characteristics, Replay-Base Architecture for Context Adaptation (RBACA) employs a CL rehearsal method to continually learn from diverse contexts, and an AL component to select the most informative instances for annotation. A novel approach to evaluate CAL methods is established using a defined metric denominated IL-Score, which allows for the simultaneous assessment of transfer learning, forgetting, and final model performance. We show that RBACA works in domain and class-incremental learning scenarios, by assessing its IL-Score on the segmentation and diagnosis of cardiac images. The results show that RBACA outperforms a baseline framework without CAL, and a state-of-the-art CAL method across various memory sizes and annotation budgets. Our code is available in https://github.com/RuiDaniel/RBACA .
Pinpoint Counterfactuals: Reducing social bias in foundation models via localized counterfactual generation
Dec 12, 2024
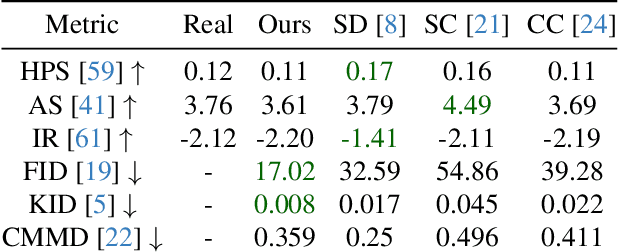

Foundation models trained on web-scraped datasets propagate societal biases to downstream tasks. While counterfactual generation enables bias analysis, existing methods introduce artifacts by modifying contextual elements like clothing and background. We present a localized counterfactual generation method that preserves image context by constraining counterfactual modifications to specific attribute-relevant regions through automated masking and guided inpainting. When applied to the Conceptual Captions dataset for creating gender counterfactuals, our method results in higher visual and semantic fidelity than state-of-the-art alternatives, while maintaining the performance of models trained using only real data on non-human-centric tasks. Models fine-tuned with our counterfactuals demonstrate measurable bias reduction across multiple metrics, including a decrease in gender classification disparity and balanced person preference scores, while preserving ImageNet zero-shot performance. The results establish a framework for creating balanced datasets that enable both accurate bias profiling and effective mitigation.
MMIST-ccRCC: A Real World Medical Dataset for the Development of Multi-Modal Systems
May 02, 2024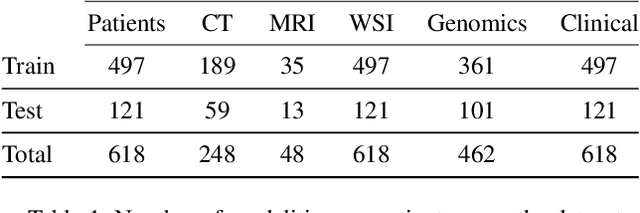
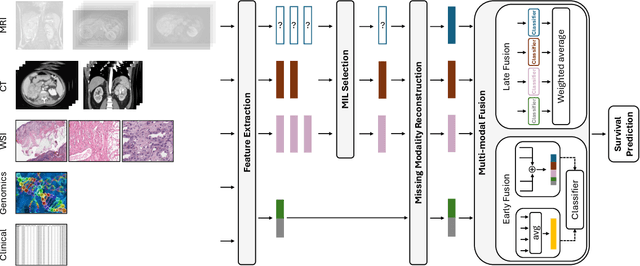
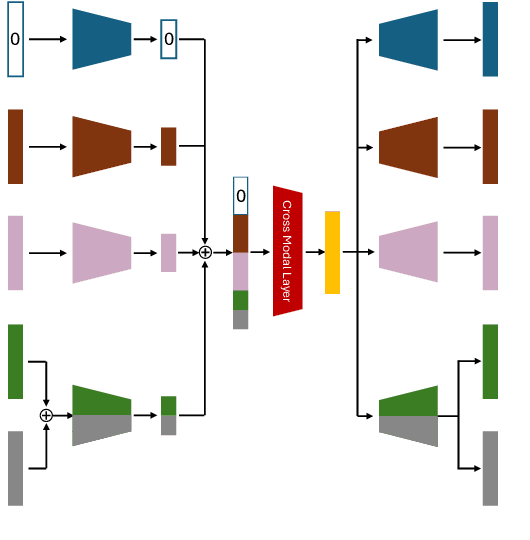
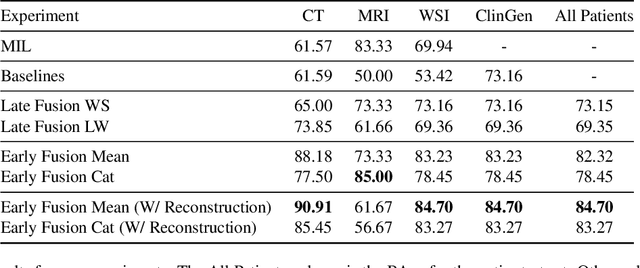
The acquisition of different data modalities can enhance our knowledge and understanding of various diseases, paving the way for a more personalized healthcare. Thus, medicine is progressively moving towards the generation of massive amounts of multi-modal data (\emph{e.g,} molecular, radiology, and histopathology). While this may seem like an ideal environment to capitalize data-centric machine learning approaches, most methods still focus on exploring a single or a pair of modalities due to a variety of reasons: i) lack of ready to use curated datasets; ii) difficulty in identifying the best multi-modal fusion strategy; and iii) missing modalities across patients. In this paper we introduce a real world multi-modal dataset called MMIST-CCRCC that comprises 2 radiology modalities (CT and MRI), histopathology, genomics, and clinical data from 618 patients with clear cell renal cell carcinoma (ccRCC). We provide single and multi-modal (early and late fusion) benchmarks in the task of 12-month survival prediction in the challenging scenario of one or more missing modalities for each patient, with missing rates that range from 26$\%$ for genomics data to more than 90$\%$ for MRI. We show that even with such severe missing rates the fusion of modalities leads to improvements in the survival forecasting. Additionally, incorporating a strategy to generate the latent representations of the missing modalities given the available ones further improves the performance, highlighting a potential complementarity across modalities. Our dataset and code are available here: https://multi-modal-ist.github.io/datasets/ccRCC
Key Patches Are All You Need: A Multiple Instance Learning Framework For Robust Medical Diagnosis
May 02, 2024Deep learning models have revolutionized the field of medical image analysis, due to their outstanding performances. However, they are sensitive to spurious correlations, often taking advantage of dataset bias to improve results for in-domain data, but jeopardizing their generalization capabilities. In this paper, we propose to limit the amount of information these models use to reach the final classification, by using a multiple instance learning (MIL) framework. MIL forces the model to use only a (small) subset of patches in the image, identifying discriminative regions. This mimics the clinical procedures, where medical decisions are based on localized findings. We evaluate our framework on two medical applications: skin cancer diagnosis using dermoscopy and breast cancer diagnosis using mammography. Our results show that using only a subset of the patches does not compromise diagnostic performance for in-domain data, compared to the baseline approaches. However, our approach is more robust to shifts in patient demographics, while also providing more detailed explanations about which regions contributed to the decision. Code is available at: https://github.com/diogojpa99/MedicalMultiple-Instance-Learning.
Extending 3D body pose estimation for robotic-assistive therapies of autistic children
Feb 12, 2024Robotic-assistive therapy has demonstrated very encouraging results for children with Autism. Accurate estimation of the child's pose is essential both for human-robot interaction and for therapy assessment purposes. Non-intrusive methods are the sole viable option since these children are sensitive to touch. While depth cameras have been used extensively, existing methods face two major limitations: (i) they are usually trained with adult-only data and do not correctly estimate a child's pose, and (ii) they fail in scenarios with a high number of occlusions. Therefore, our goal was to develop a 3D pose estimator for children, by adapting an existing state-of-the-art 3D body modelling method and incorporating a linear regression model to fine-tune one of its inputs, thereby correcting the pose of children's 3D meshes. In controlled settings, our method has an error below $0.3m$, which is considered acceptable for this kind of application and lower than current state-of-the-art methods. In real-world settings, the proposed model performs similarly to a Kinect depth camera and manages to successfully estimate the 3D body poses in a much higher number of frames.
XAI for Skin Cancer Detection with Prototypes and Non-Expert Supervision
Feb 02, 2024Skin cancer detection through dermoscopy image analysis is a critical task. However, existing models used for this purpose often lack interpretability and reliability, raising the concern of physicians due to their black-box nature. In this paper, we propose a novel approach for the diagnosis of melanoma using an interpretable prototypical-part model. We introduce a guided supervision based on non-expert feedback through the incorporation of: 1) binary masks, obtained automatically using a segmentation network; and 2) user-refined prototypes. These two distinct information pathways aim to ensure that the learned prototypes correspond to relevant areas within the skin lesion, excluding confounding factors beyond its boundaries. Experimental results demonstrate that, even without expert supervision, our approach achieves superior performance and generalization compared to non-interpretable models.