 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMIST-ccRCC: A Real World Medical Dataset for the Development of Multi-Modal Systems
May 02, 2024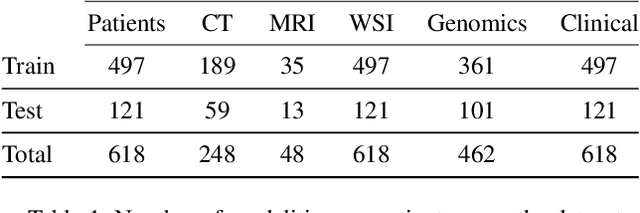
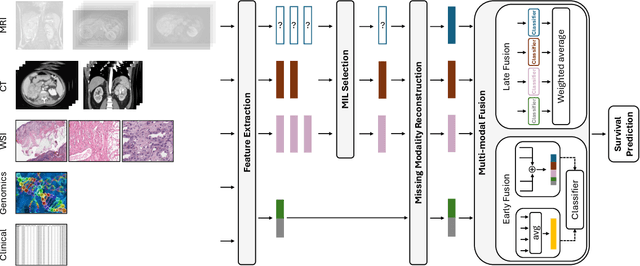
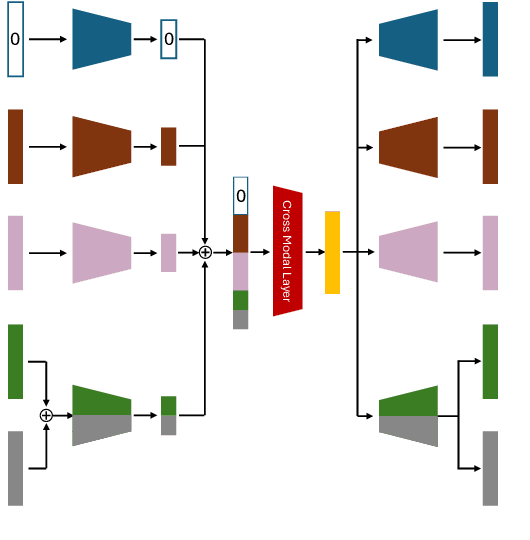
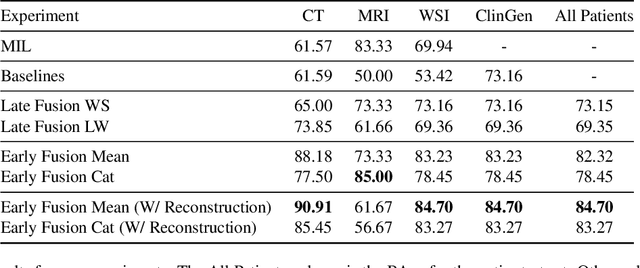
The acquisition of different data modalities can enhance our knowledge and understanding of various diseases, paving the way for a more personalized healthcare. Thus, medicine is progressively moving towards the generation of massive amounts of multi-modal data (\emph{e.g,} molecular, radiology, and histopathology). While this may seem like an ideal environment to capitalize data-centric machine learning approaches, most methods still focus on exploring a single or a pair of modalities due to a variety of reasons: i) lack of ready to use curated datasets; ii) difficulty in identifying the best multi-modal fusion strategy; and iii) missing modalities across patients. In this paper we introduce a real world multi-modal dataset called MMIST-CCRCC that comprises 2 radiology modalities (CT and MRI), histopathology, genomics, and clinical data from 618 patients with clear cell renal cell carcinoma (ccRCC). We provide single and multi-modal (early and late fusion) benchmarks in the task of 12-month survival prediction in the challenging scenario of one or more missing modalities for each patient, with missing rates that range from 26$\%$ for genomics data to more than 90$\%$ for MRI. We show that even with such severe missing rates the fusion of modalities leads to improvements in the survival forecasting. Additionally, incorporating a strategy to generate the latent representations of the missing modalities given the available ones further improves the performance, highlighting a potential complementarity across modalities. Our dataset and code are available here: https://multi-modal-ist.github.io/datasets/ccRCC
Combining Commonsense Reasoning and Knowledge Acquisition to Guide Deep Learning in Robotics
Jan 25, 2022
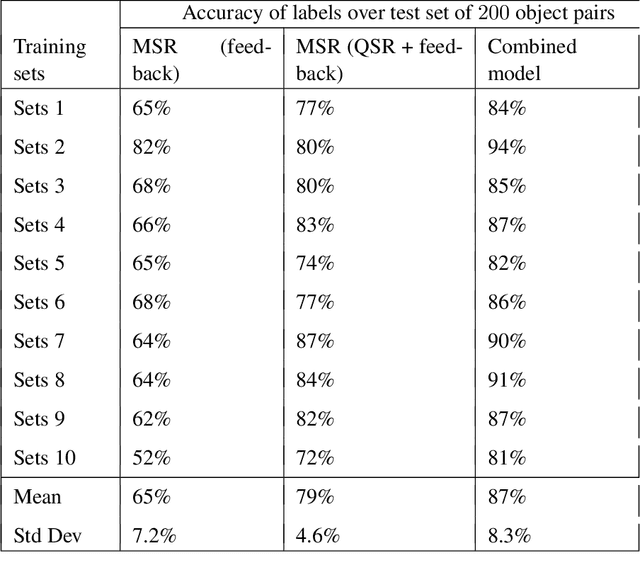
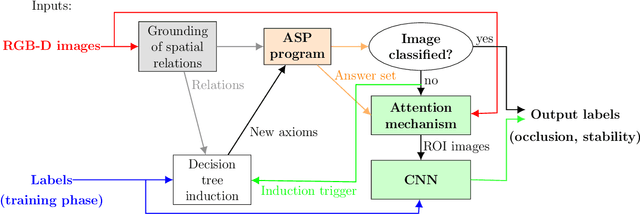

Algorithms based on deep network models are being used for many pattern recognition and decision-making tasks in robotics and AI. Training these models requires a large labeled dataset and considerable computational resources, which are not readily available in many domains. Also, it is difficult to explore the internal representations and reasoning mechanisms of these models. As a step towards addressing the underlying knowledge representation, reasoning, and learning challenges, the architecture described in this paper draws inspiration from research in cognitive systems. As a motivating example, we consider an assistive robot trying to reduce clutter in any given scene by reasoning about the occlusion of objects and stability of object configurations in an image of the scene. In this context, our architecture incrementally learns and revises a grounding of the spatial relations between objects and uses this grounding to extract spatial information from input images. Non-monotonic logical reasoning with this information and incomplete commonsense domain knowledge is used to make decisions about stability and occlusion. For images that cannot be processed by such reasoning, regions relevant to the tasks at hand are automatically identified and used to train deep network models to make the desired decisions. Image regions used to train the deep networks are also used to incrementally acquire previously unknown state constraints that are merged with the existing knowledge for subsequent reasoning. Experimental evaluation performed using simulated and real-world images indicates that in comparison with baselines based just on deep networks, our architecture improves reliability of decision making and reduces the effort involved in training data-driven deep network models.
Axiom Learning and Belief Tracing for Transparent Decision Making in Robotics
Oct 20, 2020
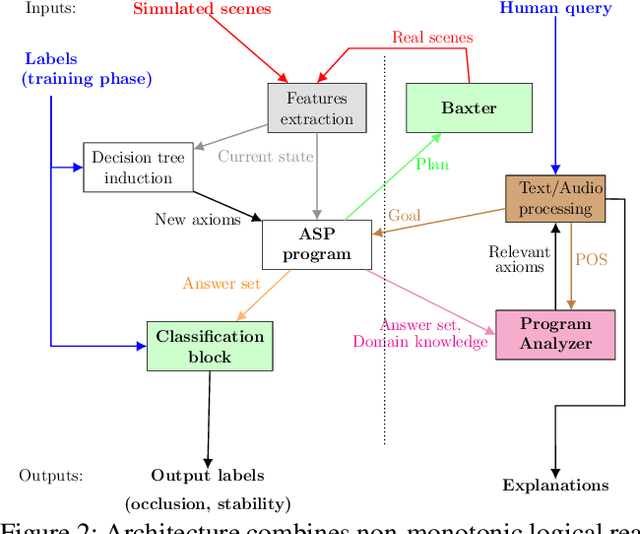
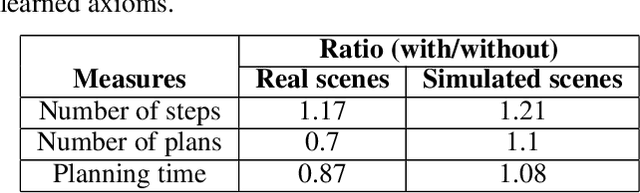
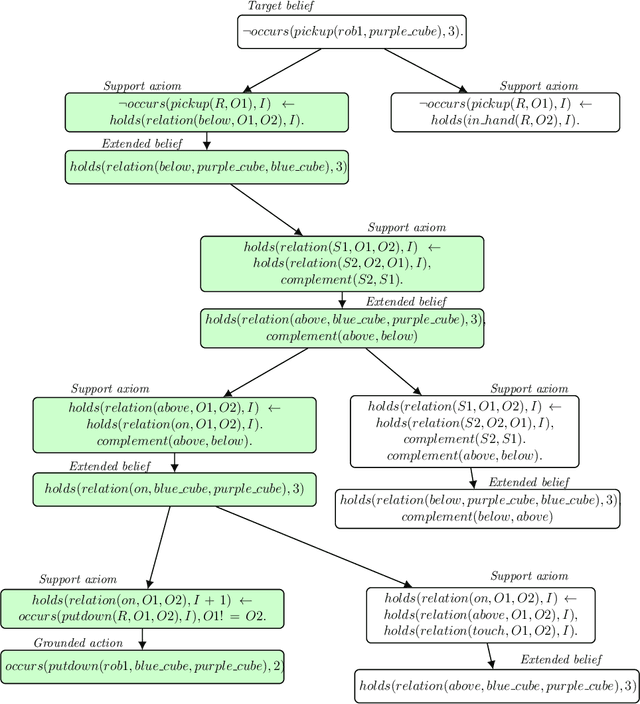
A robot's ability to provide descriptions of its decisions and beliefs promotes effective collaboration with humans. Providing such transparency is particularly challenging in integrated robot systems that include knowledge-based reasoning methods and data-driven learning algorithms. Towards addressing this challenge, our architecture couples the complementary strengths of non-monotonic logical reasoning, deep learning, and decision-tree induction. During reasoning and learning, the architecture enables a robot to provide on-demand relational descriptions of its decisions, beliefs, and the outcomes of hypothetical actions. These capabilities are grounded and evaluated in the context of scene understanding tasks and planning tasks performed using simulated images and images from a physical robot manipulating tabletop objects.